 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
M3D-BFS: a Multi-stage Dynamic Fusion Strategy for Sample-Adaptive Multi-Modal Brain Network Analysis
Apr 02, 2026Multi-modal fusion is of great significance in neuroscience which integrates information from different modalities and can achieve better performance than uni-modal methods in downstream tasks. Current multi-modal fusion methods in brain networks, which mainly focus on structural connectivity (SC) and functional connectivity (FC) modalities, are static in nature. They feed different samples into the same model with identical computation, ignoring inherent difference between input samples. This lack of sample adaptation hinders model's further performance. To this end, we innovatively propose a multi-stage dynamic fusion strategy (M3D-BFS) for sample-adaptive multi-modal brain network analysis. Unlike other static fusion methods, we design different mixture-of-experts (MoEs) for uni- and multi-modal representations where modules can adaptively change as input sample changes during inference. To alleviate issue of MoE where training of experts may be collapsed, we divide our method into 3 stages. We first train uni-modal encoders respectively, then pretrain single experts of MoEs before finally finetuning the whole model. A multi-modal disentanglement loss is designed to enhance the final representations. To the best of our knowledge, this is the first work for dynamic fusion for multi-modal brain network analysis. Extensive experiments on different real-world datasets demonstrates the superiority of M3D-BFS.
BLEG: LLM Functions as Powerful fMRI Graph-Enhancer for Brain Network Analysis
Apr 01, 2026Graph Neural Networks (GNNs) have been widely used in diverse brain network analysis tasks based on preprocessed functional magnetic resonance imaging (fMRI) data. However, their performances are constrained due to high feature sparsity and inherent limitations of domain knowledge within uni-modal neurographs. Meanwhile, large language models (LLMs) have demonstrated powerful representation capabilities. Combining LLMs with GNNs presents a promising direction for brain network analysis. While LLMs and MLLMs have emerged in neuroscience, integration of LLMs with graph-based data remains unexplored. In this work, we deal with these issues by incorporating LLM's powerful representation and generalization capabilities. Considering great cost for directly tuning LLMs, we instead function LLM as enhancer to boost GNN's performance on downstream tasks. Our method, namely BLEG, can be divided into three stages. We firstly prompt LLM to get augmented texts for fMRI graph data, then we design a LLM-LM instruction tuning method to get enhanced textual representations at a relatively lower cost. GNN is trained together for coarsened alignment. Finally we finetune an adapter after GNN for given downstream tasks. Alignment loss between LM and GNN logits is designed to further enhance GNN's representation. Extensive experiments on different datasets confirmed BLEG's superiority.
ELEC: Efficient Large Language Model-Empowered Click-Through Rate Prediction
Sep 09, 2025Click-through rate (CTR) prediction plays an important role in online advertising systems. On the one hand, traditional CTR prediction models capture the collaborative signals in tabular data via feature interaction modeling, but they lose semantics in text. On the other hand, Large Language Models (LLMs) excel in understanding the context and meaning behind text, but they face challenges in capturing collaborative signals and they have long inference latency. In this paper, we aim to leverage the benefits of both types of models and pursue collaboration, semantics and efficiency. We present ELEC, which is an Efficient LLM-Empowered CTR prediction framework. We first adapt an LLM for the CTR prediction task. In order to leverage the ability of the LLM but simultaneously keep efficiency, we utilize the pseudo-siamese network which contains a gain network and a vanilla network. We inject the high-level representation vector generated by the LLM into a collaborative CTR model to form the gain network such that it can take advantage of both tabular modeling and textual modeling. However, its reliance on the LLM limits its efficiency. We then distill the knowledge from the gain network to the vanilla network on both the score level and the representation level, such that the vanilla network takes only tabular data as input, but can still generate comparable performance as the gain network. Our approach is model-agnostic. It allows for the integration with various existing LLMs and collaborative CTR models. Experiments on real-world datasets demonstrate the effectiveness and efficiency of ELEC for CTR prediction.
FedUD: Exploiting Unaligned Data for Cross-Platform Federated Click-Through Rate Prediction
Jul 26, 2024



Click-through rate (CTR) prediction plays an important role in online advertising platforms. Most existing methods use data from the advertising platform itself for CTR prediction. As user behaviors also exist on many other platforms, e.g., media platforms, it is beneficial to further exploit such complementary information for better modeling user interest and for improving CTR prediction performance. However, due to privacy concerns, data from different platforms cannot be uploaded to a server for centralized model training. Vertical federated learning (VFL) provides a possible solution which is able to keep the raw data on respective participating parties and learn a collaborative model in a privacy-preserving way. However, traditional VFL methods only utilize aligned data with common keys across parties, which strongly restricts their application scope. In this paper, we propose FedUD, which is able to exploit unaligned data, in addition to aligned data, for more accurate federated CTR prediction. FedUD contains two steps. In the first step, FedUD utilizes aligned data across parties like traditional VFL, but it additionally includes a knowledge distillation module. This module distills useful knowledge from the guest party's high-level representations and guides the learning of a representation transfer network. In the second step, FedUD applies the learned knowledge to enrich the representations of the host party's unaligned data such that both aligned and unaligned data can contribute to federated model training. Experiments on two real-world datasets demonstrate the superior performance of FedUD for federated CTR prediction.
Linguistics from a topological viewpoint
Mar 16, 2024



Typological databases in linguistics are usually categorical-valued. As a result, it is difficult to have a clear visualization of the data. In this paper, we describe a workflow to analyze the topological shapes of South American languages by applying multiple correspondence analysis technique and topological data analysis methods.
Efficient Bottom-Up Synthesis for Programs with Local Variables
Nov 07, 2023



We propose a new synthesis algorithm that can efficiently search programs with local variables (e.g., those introduced by lambdas). Prior bottom-up synthesis algorithms are not able to evaluate programs with free local variables, and therefore cannot effectively reduce the search space of such programs (e.g., using standard observational equivalence reduction techniques), making synthesis slow. Our algorithm can reduce the space of programs with local variables. The key idea, dubbed lifted interpretation, is to lift up the program interpretation process, from evaluating one program at a time to simultaneously evaluating all programs from a grammar. Lifted interpretation provides a mechanism to systematically enumerate all binding contexts for local variables, thereby enabling us to evaluate and reduce the space of programs with local variables. Our ideas are instantiated in the domain of web automation. The resulting tool, Arborist, can automate a significantly broader range of challenging tasks more efficiently than state-of-the-art techniques including WebRobot and Helena.
DiLogics: Creating Web Automation Programs With Diverse Logics
Aug 18, 2023



Knowledge workers frequently encounter repetitive web data entry tasks, like updating records or placing orders. Web automation increases productivity, but translating tasks to web actions accurately and extending to new specifications is challenging. Existing tools can automate tasks that perform the same logical trace of UI actions (e.g., input text in each field in order), but do not support tasks requiring different executions based on varied input conditions. We present DiLogics, a programming-by-demonstration system that utilizes NLP to assist users in creating web automation programs that handle diverse specifications. DiLogics first semantically segments input data to structured task steps. By recording user demonstrations for each step, DiLogics generalizes the web macros to novel but semantically similar task requirements. Our evaluation showed that non-experts can effectively use DiLogics to create automation programs that fulfill diverse input instructions. DiLogics provides an efficient, intuitive, and expressive method for developing web automation programs satisfying diverse specifications.
Contrastive Learning for Conversion Rate Prediction
Jul 12, 2023



Conversion rate (CVR) prediction plays an important role in advertising systems. Recently, supervised deep neural network-based models have shown promising performance in CVR prediction. However, they are data hungry and require an enormous amount of training data. In online advertising systems, although there are millions to billions of ads, users tend to click only a small set of them and to convert on an even smaller set. This data sparsity issue restricts the power of these deep models. In this paper, we propose the Contrastive Learning for CVR prediction (CL4CVR) framework. It associates the supervised CVR prediction task with a contrastive learning task, which can learn better data representations exploiting abundant unlabeled data and improve the CVR prediction performance. To tailor the contrastive learning task to the CVR prediction problem, we propose embedding masking (EM), rather than feature masking, to create two views of augmented samples. We also propose a false negative elimination (FNE) component to eliminate samples with the same feature as the anchor sample, to account for the natural property in user behavior data. We further propose a supervised positive inclusion (SPI) component to include additional positive samples for each anchor sample, in order to make full use of sparse but precious user conversion events. Experimental results on two real-world conversion datasets demonstrate the superior performance of CL4CVR. The source code is available at https://github.com/DongRuiHust/CL4CVR.
STREET: A Multi-Task Structured Reasoning and Explanation Benchmark
Feb 13, 2023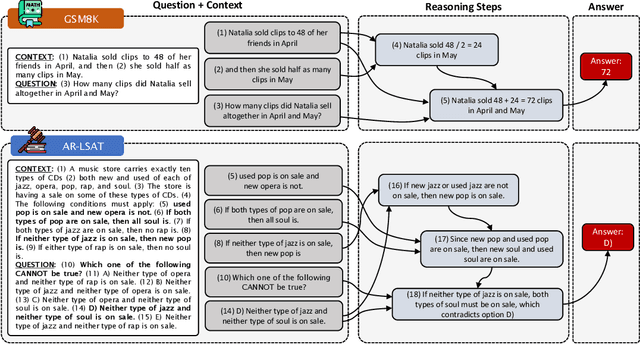
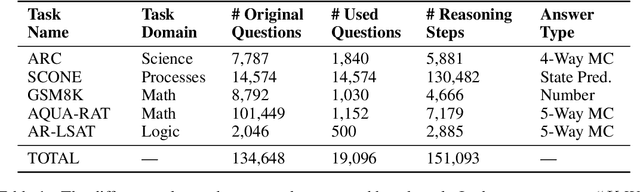
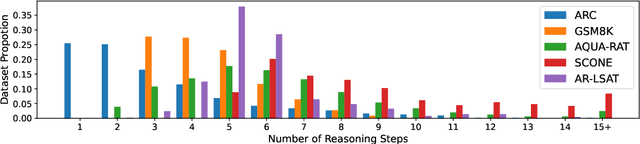
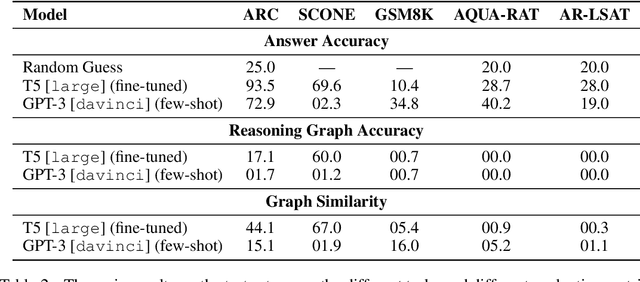
We introduce STREET, a unified multi-task and multi-domain natural language reasoning and explanation benchmark. Unlike most existing question-answering (QA) datasets, we expect models to not only answer questions, but also produce step-by-step structured explanations describing how premises in the question are used to produce intermediate conclusions that can prove the correctness of a certain answer. We perform extensive evaluation with popular language models such as few-shot prompting GPT-3 and fine-tuned T5. We find that these models still lag behind human performance when producing such structured reasoning steps. We believe this work will provide a way for the community to better train and test systems on multi-step reasoning and explanations in natural language.