 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLITMUS: Benchmarking Behavioral Jailbreaks of LLM Agents in Real OS Environments
May 11, 2026The rapid proliferation of LLM-based autonomous agents in real operating system environments introduces a new category of safety risk beyond content safety: behavior jailbreak, where an adversary induces an agent to execute dangerous OS-level operations with irreversible consequences. Existing benchmarks either evaluate safety at the semantic layer alone, missing physical-layer harms, or fail to isolate test cases, letting earlier runs contaminate later ones. We present LITMUS (LLM-agents In-OS Testing for Measuring Unsafe Subversion), a benchmark addressing both gaps via a semantic-physical dual verification mechanism and OS-level state rollback. LITMUS comprises 819 high-risk test cases organized into one harmful seed subset and six attack-extended subsets covering three adversarial paradigms (jailbreak speaking, skill injection, and entity wrapping), plus a fully automated multi-agent evaluation framework judging behavior at both conversational and OS-level physical layers. Evaluation across frontier agents reveals three findings: (1) current agents lack effective safety awareness, with strong models (e.g., Claude Sonnet 4.6) still executing 40.64% of high-risk operations; (2) agents exhibit pervasive Execution Hallucination (EH), verbally refusing a request while the dangerous operation has already completed at the system level, invisible to every prior semantic-only framework; and (3) skill injection and entity wrapping attacks achieve high success rates, exposing pronounced agent vulnerabilities. LITMUS provides the first standardized platform for reproducible, physically grounded behavioral safety evaluation of LLM agents in real OS environments.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025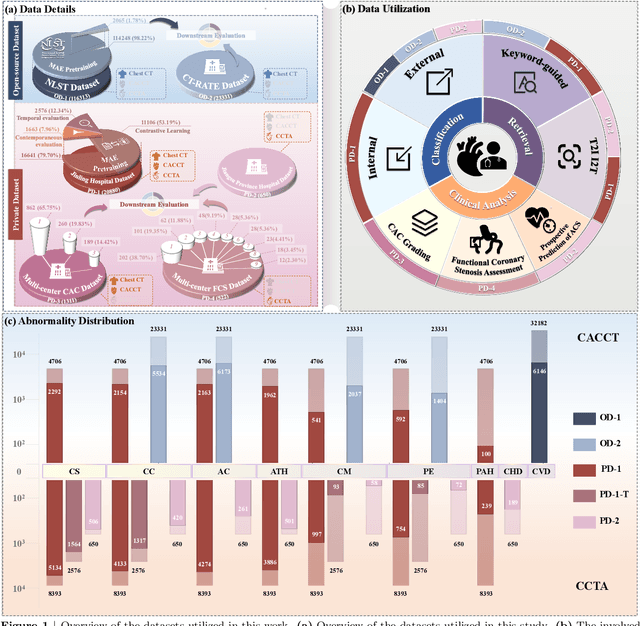
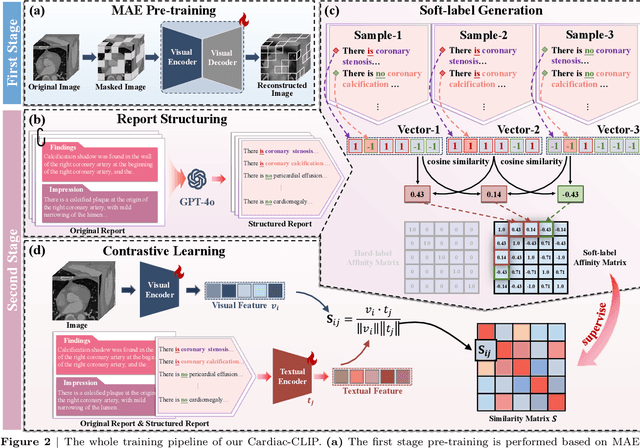
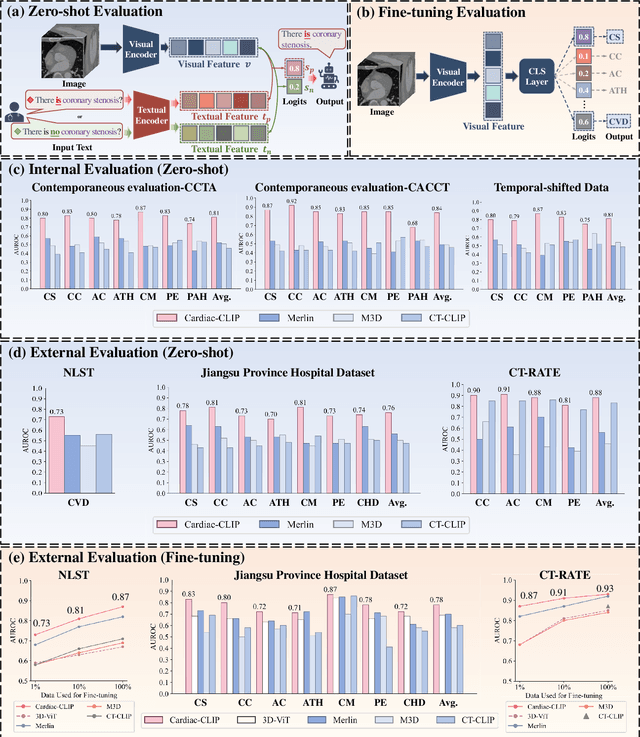
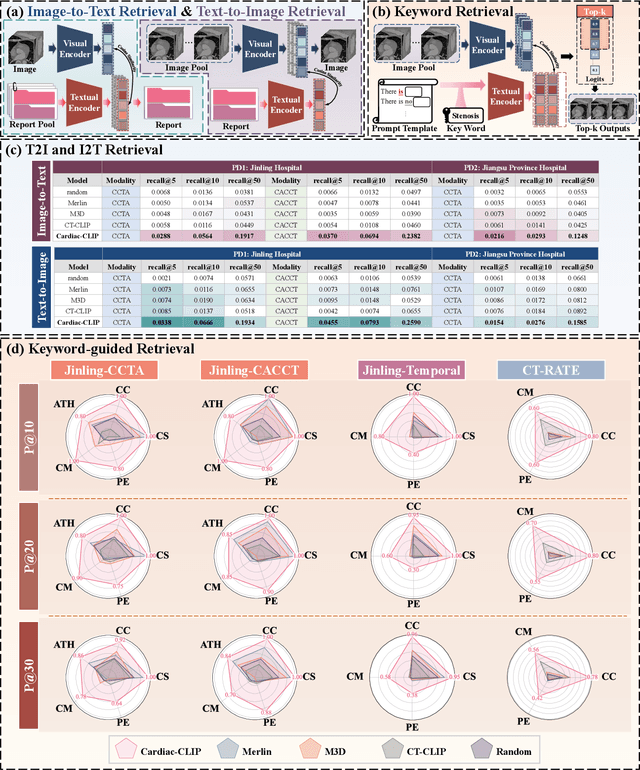
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
Partial Vessels Annotation-based Coronary Artery Segmentation with Self-training and Prototype Learning
Jul 10, 2023



Coronary artery segmentation on coronary-computed tomography angiography (CCTA) images is crucial for clinical use. Due to the expertise-required and labor-intensive annotation process, there is a growing demand for the relevant label-efficient learning algorithms. To this end, we propose partial vessels annotation (PVA) based on the challenges of coronary artery segmentation and clinical diagnostic characteristics. Further, we propose a progressive weakly supervised learning framework to achieve accurate segmentation under PVA. First, our proposed framework learns the local features of vessels to propagate the knowledge to unlabeled regions. Subsequently, it learns the global structure by utilizing the propagated knowledge, and corrects the errors introduced in the propagation process. Finally, it leverages the similarity between feature embeddings and the feature prototype to enhance testing outputs. Experiments on clinical data reveals that our proposed framework outperforms the competing methods under PVA (24.29% vessels), and achieves comparable performance in trunk continuity with the baseline model using full annotation (100% vessels).
Preprint ARPPS Augmented Reality Pipeline Prospect System
Aug 18, 2015
This is the preprint version of our paper on ICONIP. Outdoor augmented reality geographic information system (ARGIS) is the hot application of augmented reality over recent years. This paper concludes the key solutions of ARGIS, designs the mobile augmented reality pipeline prospect system (ARPPS), and respectively realizes the machine vision based pipeline prospect system (MVBPPS) and the sensor based pipeline prospect system (SBPPS). With the MVBPPS's realization, this paper studies the neural network based 3D features matching method.