 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAFMat: Hybrid Priors Guided Adaptive Fusion for Single-Image Human Material Estimation
Jun 15, 2026Physically based rendering (PBR) material estimation is a fundamental appearance decomposition task with broad applications in virtual content creation, relighting, and digital human rendering. However, estimating PBR materials from a single human image remains highly ill-posed, since illumination, geometry, and reflectance are heavily entangled in the observed appearance. To mitigate this ambiguity, we propose HAFMat, a hybrid-prior-guided framework for single-image human material estimation. Our method introduces guidance maps that encode complementary cues, including appearance, body geometry, structure, and prior material predictions from pre-trained models. A key observation is that these guidance cues are heterogeneous: some cues mainly provide texture-level constraints, while others convey higher-level semantic information. To exploit this property, we design a Multi-layer Adaptive Feature Fusion Mechanism, which adaptively fuses guidance features with decoder features at different stages. This design enables texture-dominant and semantic-dominant cues to guide material decoding at appropriate levels, leading to more accurate and physically plausible material estimation. Extensive experiments on both synthetic and real data demonstrate that our method achieves state-of-the-art performance in material estimation and downstream relighting.
PathAR: Structure-First Autoregressive Synthesis of Multimodal Pathology Images
Jun 01, 2026Data scarcity in multimodal pathology motivates unified generative models that synthesize modality-specific appearance while preserving anatomically coherent structure. Although modalities differ in appearance statistics, morphological structures such as cellular topology and tissue boundaries are largely preserved across acquisition protocols. However, existing methods often model these factors within a homogeneous token stream, implicitly coupling structure with appearance and weakening structural controllability under modality shifts. To address this, we propose pathology Autorgressive modeling (PathAR), a structure-first autoregressive synthesis framework that explicitly factorizes structure and appearance for modality-label-conditioned pathology generation.PathAR employs a dual vector quantization (Dual-VQ) tokenizer to decompose samples into mask-grounded structure and appearance tokens, and an interleaved autoregressive (IAR) transformer with asymmetric attention visibility to enforce structure-to-appearance dependence. PathAR stabilizes morphology under heterogeneous modality-specific appearances and enables spatially aligned image--mask pair generation. Extensive experiments show that PathAR improves structural consistency and modality fidelity over baselines, maintains sample diversity, supports downstream segmentation in data-scarce regimes, and demonstrates extensibility to finer-grained intra-modality organ-label variation.
Interpretable Zero-shot Referring Expression Comprehension with Query-driven Scene Graphs
Mar 26, 2026Zero-shot referring expression comprehension (REC) aims to locate target objects in images given natural language queries without relying on task-specific training data, demanding strong visual understanding capabilities. Existing Vision-Language Models~(VLMs), such as CLIP, commonly address zero-shot REC by directly measuring feature similarities between textual queries and image regions. However, these methods struggle to capture fine-grained visual details and understand complex object relationships. Meanwhile, Large Language Models~(LLMs) excel at high-level semantic reasoning, their inability to directly abstract visual features into textual semantics limits their application in REC tasks. To overcome these limitations, we propose \textbf{SGREC}, an interpretable zero-shot REC method leveraging query-driven scene graphs as structured intermediaries. Specifically, we first employ a VLM to construct a query-driven scene graph that explicitly encodes spatial relationships, descriptive captions, and object interactions relevant to the given query. By leveraging this scene graph, we bridge the gap between low-level image regions and higher-level semantic understanding required by LLMs. Finally, an LLM infers the target object from the structured textual representation provided by the scene graph, responding with detailed explanations for its decisions that ensure interpretability in the inference process. Extensive experiments show that SGREC achieves top-1 accuracy on most zero-shot REC benchmarks, including RefCOCO val (66.78\%), RefCOCO+ testB (53.43\%), and RefCOCOg val (73.28\%), highlighting its strong visual scene understanding.
Disentangle-then-Align: Non-Iterative Hybrid Multimodal Image Registration via Cross-Scale Feature Disentanglement
Mar 20, 2026Multimodal image registration is a fundamental task and a prerequisite for downstream cross-modal analysis. Despite recent progress in shared feature extraction and multi-scale architectures, two key limitations remain. First, some methods use disentanglement to learn shared features but mainly regularize the shared part, allowing modality-private cues to leak into the shared space. Second, most multi-scale frameworks support only a single transformation type, limiting their applicability when global misalignment and local deformation coexist. To address these issues, we formulate hybrid multimodal registration as jointly learning a stable shared feature space and a unified hybrid transformation. Based on this view, we propose HRNet, a Hybrid Registration Network that couples representation disentanglement with hybrid parameter prediction. A shared backbone with Modality-Specific Batch Normalization (MSBN) extracts multi-scale features, while a Cross-scale Disentanglement and Adaptive Projection (CDAP) module suppresses modality-private cues and projects shared features into a stable subspace for matching. Built on this shared space, a Hybrid Parameter Prediction Module (HPPM) performs non-iterative coarse-to-fine estimation of global rigid parameters and deformation fields, which are fused into a coherent deformation field. Extensive experiments on four multimodal datasets demonstrate state-of-the-art performance on rigid and non-rigid registration tasks. The code is available at the project website.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025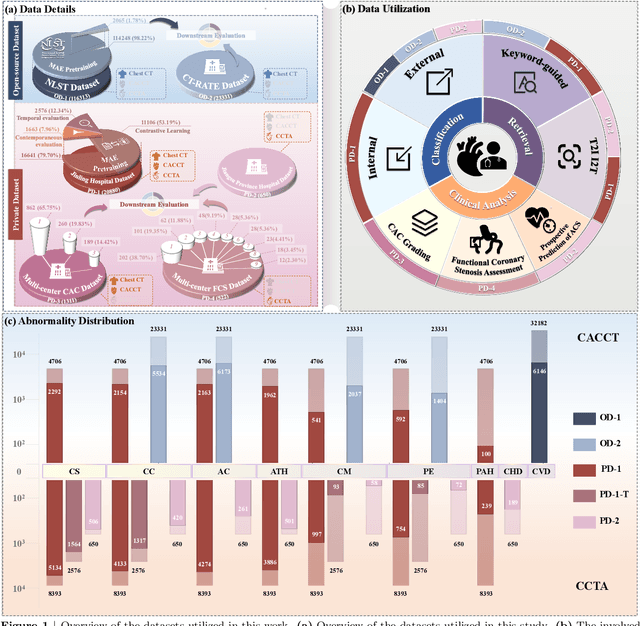
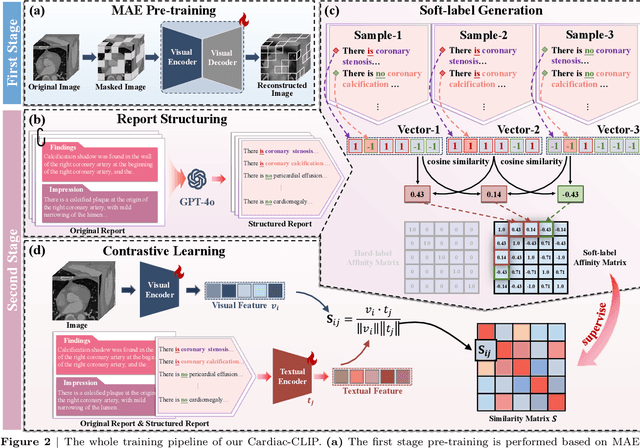
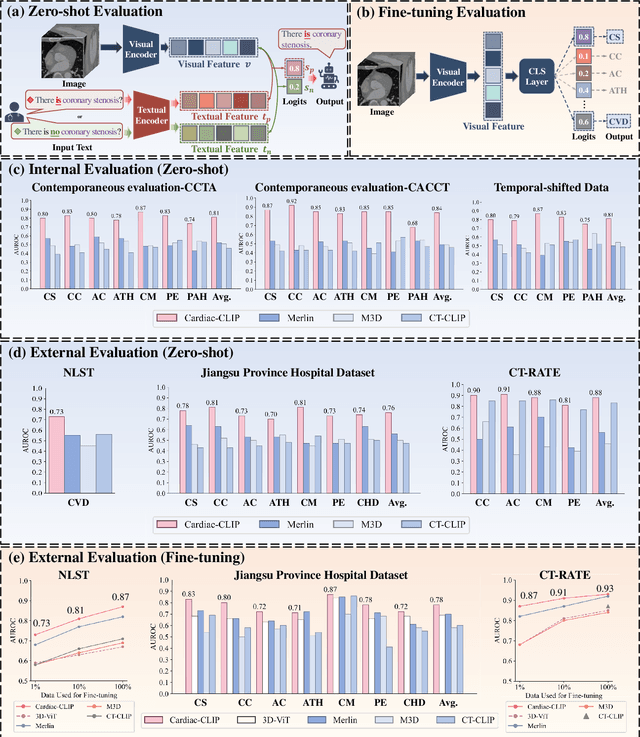
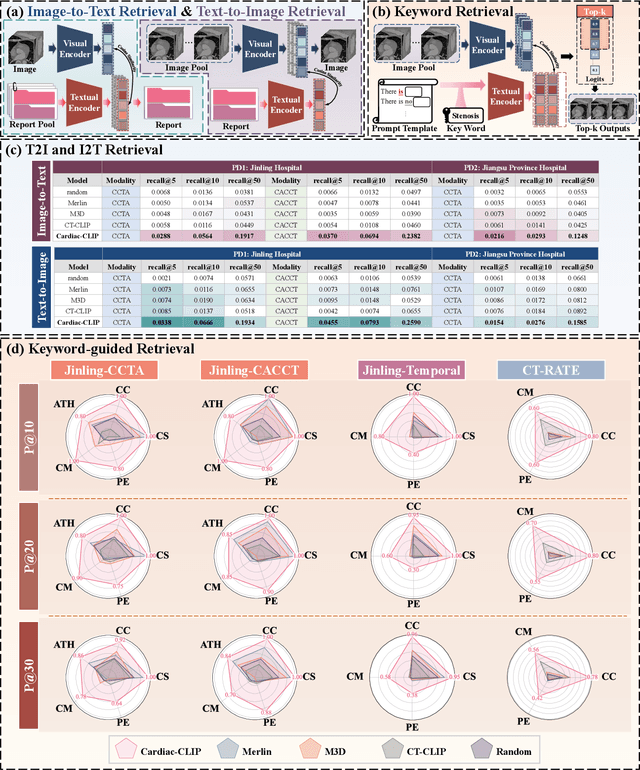
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
Unsupervised Part Discovery via Descriptor-Based Masked Image Restoration with Optimized Constraints
Jul 16, 2025Part-level features are crucial for image understanding, but few studies focus on them because of the lack of fine-grained labels. Although unsupervised part discovery can eliminate the reliance on labels, most of them cannot maintain robustness across various categories and scenarios, which restricts their application range. To overcome this limitation, we present a more effective paradigm for unsupervised part discovery, named Masked Part Autoencoder (MPAE). It first learns part descriptors as well as a feature map from the inputs and produces patch features from a masked version of the original images. Then, the masked regions are filled with the learned part descriptors based on the similarity between the local features and descriptors. By restoring these masked patches using the part descriptors, they become better aligned with their part shapes, guided by appearance features from unmasked patches. Finally, MPAE robustly discovers meaningful parts that closely match the actual object shapes, even in complex scenarios. Moreover, several looser yet more effective constraints are proposed to enable MPAE to identify the presence of parts across various scenarios and categories in an unsupervised manner. This provides the foundation for addressing challenges posed by occlusion and for exploring part similarity across multiple categories. Extensive experiments demonstrate that our method robustly discovers meaningful parts across various categories and scenarios. The code is available at the project https://github.com/Jiahao-UTS/MPAE.
Mitigating Knowledge Discrepancies among Multiple Datasets for Task-agnostic Unified Face Alignment
Mar 28, 2025



Despite the similar structures of human faces, existing face alignment methods cannot learn unified knowledge from multiple datasets with different landmark annotations. The limited training samples in a single dataset commonly result in fragile robustness in this field. To mitigate knowledge discrepancies among different datasets and train a task-agnostic unified face alignment (TUFA) framework, this paper presents a strategy to unify knowledge from multiple datasets. Specifically, we calculate a mean face shape for each dataset. To explicitly align these mean shapes on an interpretable plane based on their semantics, each shape is then incorporated with a group of semantic alignment embeddings. The 2D coordinates of these aligned shapes can be viewed as the anchors of the plane. By encoding them into structure prompts and further regressing the corresponding facial landmarks using image features, a mapping from the plane to the target faces is finally established, which unifies the learning target of different datasets. Consequently, multiple datasets can be utilized to boost the generalization ability of the model. The successful mitigation of discrepancies also enhances the efficiency of knowledge transferring to a novel dataset, significantly boosts the performance of few-shot face alignment. Additionally, the interpretable plane endows TUFA with a task-agnostic characteristic, enabling it to locate landmarks unseen during training in a zero-shot manner. Extensive experiments are carried on seven benchmarks and the results demonstrate an impressive improvement in face alignment brought by knowledge discrepancies mitigation.
FCaS: Fine-grained Cardiac Image Synthesis based on 3D Template Conditional Diffusion Model
Mar 12, 2025Solving medical imaging data scarcity through semantic image generation has attracted significant attention in recent years. However, existing methods primarily focus on generating whole-organ or large-tissue structures, showing limited effectiveness for organs with fine-grained structure. Due to stringent topological consistency, fragile coronary features, and complex 3D morphological heterogeneity in cardiac imaging, accurately reconstructing fine-grained anatomical details of the heart remains a great challenge. To address this problem, in this paper, we propose the Fine-grained Cardiac image Synthesis(FCaS) framework, established on 3D template conditional diffusion model. FCaS achieves precise cardiac structure generation using Template-guided Conditional Diffusion Model (TCDM) through bidirectional mechanisms, which provides the fine-grained topological structure information of target image through the guidance of template. Meanwhile, we design a deformable Mask Generation Module (MGM) to mitigate the scarcity of high-quality and diverse reference mask in the generation process. Furthermore, to alleviate the confusion caused by imprecise synthetic images, we propose a Confidence-aware Adaptive Learning (CAL) strategy to facilitate the pre-training of downstream segmentation tasks. Specifically, we introduce the Skip-Sampling Variance (SSV) estimation to obtain confidence maps, which are subsequently employed to rectify the pre-training on downstream tasks. Experimental results demonstrate that images generated from FCaS achieves state-of-the-art performance in topological consistency and visual quality, which significantly facilitates the downstream tasks as well. Code will be released in the future.
Unsupervised Part Discovery via Dual Representation Alignment
Aug 15, 2024



Object parts serve as crucial intermediate representations in various downstream tasks, but part-level representation learning still has not received as much attention as other vision tasks. Previous research has established that Vision Transformer can learn instance-level attention without labels, extracting high-quality instance-level representations for boosting downstream tasks. In this paper, we achieve unsupervised part-specific attention learning using a novel paradigm and further employ the part representations to improve part discovery performance. Specifically, paired images are generated from the same image with different geometric transformations, and multiple part representations are extracted from these paired images using a novel module, named PartFormer. These part representations from the paired images are then exchanged to improve geometric transformation invariance. Subsequently, the part representations are aligned with the feature map extracted by a feature map encoder, achieving high similarity with the pixel representations of the corresponding part regions and low similarity in irrelevant regions. Finally, the geometric and semantic constraints are applied to the part representations through the intermediate results in alignment for part-specific attention learning, encouraging the PartFormer to focus locally and the part representations to explicitly include the information of the corresponding parts. Moreover, the aligned part representations can further serve as a series of reliable detectors in the testing phase, predicting pixel masks for part discovery. Extensive experiments are carried out on four widely used datasets, and our results demonstrate that the proposed method achieves competitive performance and robustness due to its part-specific attention.
Embracing Events and Frames with Hierarchical Feature Refinement Network for Object Detection
Jul 17, 2024



In frame-based vision, object detection faces substantial performance degradation under challenging conditions due to the limited sensing capability of conventional cameras. Event cameras output sparse and asynchronous events, providing a potential solution to solve these problems. However, effectively fusing two heterogeneous modalities remains an open issue. In this work, we propose a novel hierarchical feature refinement network for event-frame fusion. The core concept is the design of the coarse-to-fine fusion module, denoted as the cross-modality adaptive feature refinement (CAFR) module. In the initial phase, the bidirectional cross-modality interaction (BCI) part facilitates information bridging from two distinct sources. Subsequently, the features are further refined by aligning the channel-level mean and variance in the two-fold adaptive feature refinement (TAFR) part. We conducted extensive experiments on two benchmarks: the low-resolution PKU-DDD17-Car dataset and the high-resolution DSEC dataset. Experimental results show that our method surpasses the state-of-the-art by an impressive margin of $\textbf{8.0}\%$ on the DSEC dataset. Besides, our method exhibits significantly better robustness (\textbf{69.5}\% versus \textbf{38.7}\%) when introducing 15 different corruption types to the frame images. The code can be found at the link (https://github.com/HuCaoFighting/FRN).