 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening to the Echo: User-Reaction Aware Policy Optimization via Scalar-Verbal Hybrid Reinforcement Learning
Mar 16, 2026While current emotional support dialogue systems typically rely on expert-defined scalar rewards for alignment, these signals suffer from severe information sparsity. They cannot explain why a response failed or how to adapt to dynamic user states, often diverging from the actual goal of facilitating positive emotional shifts. In practice, the most direct and reliable learning signal emerges from the user's continuous reactions during ongoing interaction. We therefore propose Reaction Aware Policy Optimization (RAPO), a framework that optimizes over interaction consequences rather than rubric scores. RAPO treats dialogue as a reaction-driven process and utilizes simulated user responses to generate dense natural-language feedback through three core components: Hindsight Dialogue Selection, which isolates pivotal turns that meaningfully alter user emotional trajectories; Generative Hindsight Feedback, which transforms user reactions into contrastive ranking signals and natural-language critiques; and Scalar-Verbal Hybrid Policy Optimization, which couples scalar reward optimization for global alignment with verbal feedback distillation for fine-grained semantic refinement. Extensive experiments on ESC and Sotopia demonstrate that RAPO significantly outperforms strong reinforcement learning baselines in driving positive interaction outcomes.
ALIVE: Awakening LLM Reasoning via Adversarial Learning and Instructive Verbal Evaluation
Feb 05, 2026The quest for expert-level reasoning in Large Language Models (LLMs) has been hampered by a persistent \textit{reward bottleneck}: traditional reinforcement learning (RL) relies on scalar rewards that are \textbf{costly} to scale, \textbf{brittle} across domains, and \textbf{blind} to the underlying logic of a solution. This reliance on external, impoverished signals prevents models from developing a deep, self-contained understanding of reasoning principles. We introduce \textbf{ALIVE} (\emph{Adversarial Learning with Instructive Verbal Evaluation}), a hands-free alignment framework that moves beyond scalar reward optimization toward intrinsic reasoning acquisition. Grounded in the principle of \emph{Cognitive Synergy}, ALIVE unifies problem posing, solving, and judging within a single policy model to internalize the logic of correctness. By coupling adversarial learning with instructive verbal feedback, ALIVE enables models to internalize evaluative criteria directly from raw corpora, effectively transforming external critiques into an endogenous reasoning faculty. Empirical evaluations across mathematical reasoning, code generation, and general logical inference benchmarks demonstrate that ALIVE consistently mitigates reward signal limitations. With identical data and compute, it achieves accuracy gains, markedly improved cross-domain generalization, and higher self-correction rates. These results indicate that the reasoning trinity fosters a self-sustaining trajectory of capability growth, positioning ALIVE as a scalable foundation for general-purpose reasoning alignment without human-in-the-loop supervision.
Beyond Text-to-SQL: Can LLMs Really Debug Enterprise ETL SQL?
Jan 26, 2026SQL is central to enterprise data engineering, yet generating fully correct SQL code in a single attempt remains difficult, even for experienced developers and advanced text-to-SQL LLMs, often requiring multiple debugging iterations. We introduce OurBench, the first benchmark for enterprise-level SQL reasoning and debugging. Our benchmark is built on two key innovations: (1) an automated construction workflow that uses reverse engineering to systematically inject realistic bugs into large-scale SQL code, enabling scalable and diverse benchmark generation; and (2) an execution-free evaluation framework tailored to enterprise settings, providing fast, accurate, and resource-efficient assessment. OurBench comprises 469 OurBenchSyn queries featuring syntax errors with explicit error messages, and 516 OurBenchSem queries targeting semantic errors in which the code fails to meet user intent. The queries are highly complex, averaging over 140 lines and featuring deep and wide abstract syntax trees. Evaluation of nearly 30 LLMs reveals a substantial performance gap: the best-performing model, Claude-4-Sonnet, achieves only 36.46 percent accuracy on OurBenchSyn and 32.17 percent on OurBenchSem, while most models score below 20 percent. We further explore four solution strategies, identify key challenges, and outline promising directions for enterprise SQL debugging with LLMs.
EmoHarbor: Evaluating Personalized Emotional Support by Simulating the User's Internal World
Jan 04, 2026Current evaluation paradigms for emotional support conversations tend to reward generic empathetic responses, yet they fail to assess whether the support is genuinely personalized to users' unique psychological profiles and contextual needs. We introduce EmoHarbor, an automated evaluation framework that adopts a User-as-a-Judge paradigm by simulating the user's inner world. EmoHarbor employs a Chain-of-Agent architecture that decomposes users' internal processes into three specialized roles, enabling agents to interact with supporters and complete assessments in a manner similar to human users. We instantiate this benchmark using 100 real-world user profiles that cover a diverse range of personality traits and situations, and define 10 evaluation dimensions of personalized support quality. Comprehensive evaluation of 20 advanced LLMs on EmoHarbor reveals a critical insight: while these models excel at generating empathetic responses, they consistently fail to tailor support to individual user contexts. This finding reframes the central challenge, shifting research focus from merely enhancing generic empathy to developing truly user-aware emotional support. EmoHarbor provides a reproducible and scalable framework to guide the development and evaluation of more nuanced and user-aware emotional support systems.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025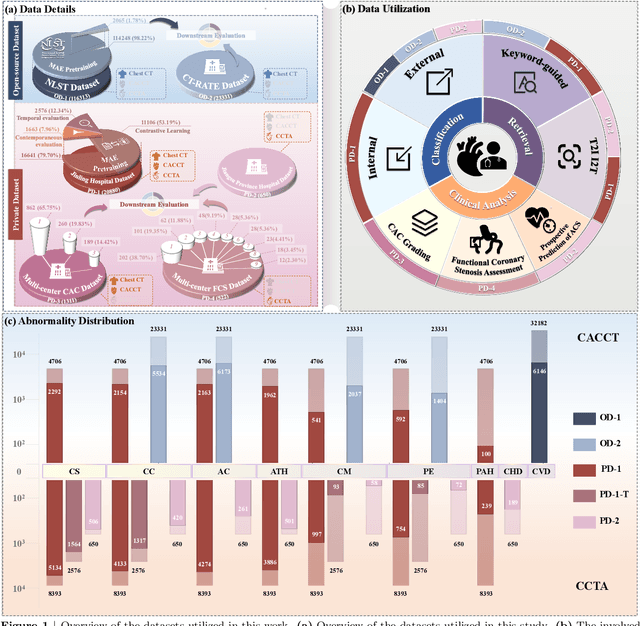
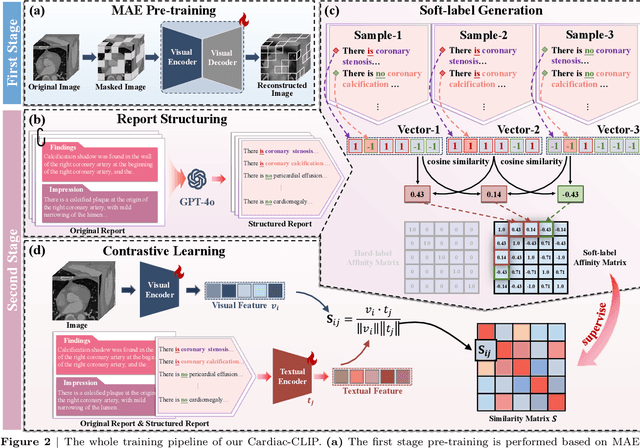
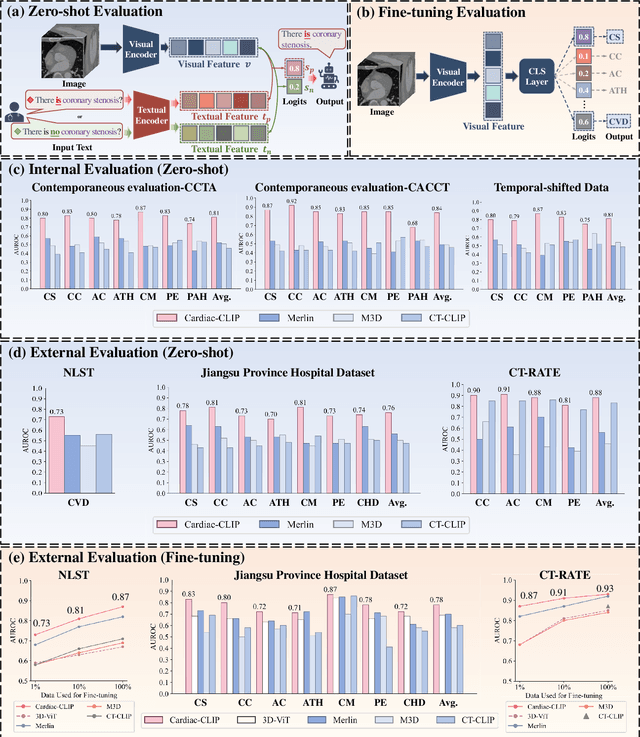
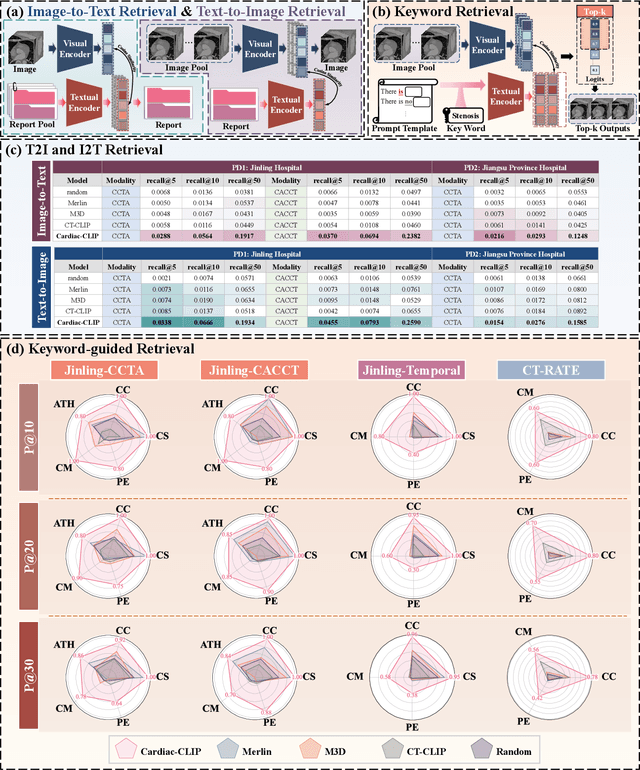
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
AMF-MedIT: An Efficient Align-Modulation-Fusion Framework for Medical Image-Tabular Data
Jun 24, 2025



Multimodal medical analysis combining image and tabular data has gained increasing attention. However, effective fusion remains challenging due to cross-modal discrepancies in feature dimensions and modality contributions, as well as the noise from high-dimensional tabular inputs. To address these problems, we present AMF-MedIT, an efficient Align-Modulation-Fusion framework for medical image and tabular data integration, particularly under data-scarce conditions. To harmonize dimension discrepancies and dynamically adjust modality contributions, we propose the Adaptive Modulation and Fusion (AMF) module, a novel modulation-based fusion paradigm with a streamlined architecture. We first derive the modulation objectives and introduce a modality confidence ratio, enabling the incorporation of prior knowledge into the fusion process. Then, the feature masks, density and leakage losses are proposed to achieve the modulation objectives. Additionally, we introduce FT-Mamba, a powerful tabular encoder leveraging a selective mechanism to handle noisy medical tabular data efficiently. Furthermore, interpretability studies are conducted to explore how different tabular encoders supervise the imaging modality during contrastive pretraining for the first time. Extensive experiments demonstrate that AMF-MedIT achieves a superior balance between multimodal performance and data efficiency while showing strong adaptability to incomplete tabular data. Interpretability analysis also highlights FT-Mamba's capabilities in extracting distinct tabular features and guiding the image encoder toward more accurate and flexible attention patterns.
ChARM: Character-based Act-adaptive Reward Modeling for Advanced Role-Playing Language Agents
May 29, 2025



Role-Playing Language Agents (RPLAs) aim to simulate characters for realistic and engaging human-computer interactions. However, traditional reward models often struggle with scalability and adapting to subjective conversational preferences. We propose ChARM, a Character-based Act-adaptive Reward Model, addressing these challenges through two innovations: (1) an act-adaptive margin that significantly enhances learning efficiency and generalizability, and (2) a self-evolution mechanism leveraging large-scale unlabeled data to improve training coverage. Additionally, we introduce RoleplayPref, the first large-scale preference dataset specifically for RPLAs, featuring 1,108 characters, 13 subcategories, and 16,888 bilingual dialogues, alongside RoleplayEval, a dedicated evaluation benchmark. Experimental results show a 13% improvement over the conventional Bradley-Terry model in preference rankings. Furthermore, applying ChARM-generated rewards to preference learning techniques (e.g., direct preference optimization) achieves state-of-the-art results on CharacterEval and RoleplayEval. Code and dataset are available at https://github.com/calubkk/ChARM.
From Generic Empathy to Personalized Emotional Support: A Self-Evolution Framework for User Preference Alignment
May 22, 2025Effective emotional support hinges on understanding users' emotions and needs to provide meaningful comfort during multi-turn interactions. Large Language Models (LLMs) show great potential for expressing empathy; however, they often deliver generic and one-size-fits-all responses that fail to address users' specific needs. To tackle this issue, we propose a self-evolution framework designed to help LLMs improve their responses to better align with users' implicit preferences concerning user profiles (personalities), emotional states, and specific situations. Our framework consists of two distinct phases: \textit{(1)} \textit{Emotional Support Experience Acquisition}, where LLMs are fine-tuned on limited emotional support conversation data to provide basic support, and \textit{(2)} \textit{Self-Improvement for Personalized Emotional Support}, where LLMs leverage self-reflection and self-refinement to generate personalized responses. Through iterative direct preference optimization between the pre- and post-refined responses, our model generates responses that reflect a better understanding of the user's implicit preferences. Extensive experiments and evaluations demonstrate that our method significantly enhances the model's performance in emotional support, reducing unhelpful responses and minimizing discrepancies between user preferences and model outputs.
SweetieChat: A Strategy-Enhanced Role-playing Framework for Diverse Scenarios Handling Emotional Support Agent
Dec 11, 2024



Large Language Models (LLMs) have demonstrated promising potential in providing empathetic support during interactions. However, their responses often become verbose or overly formulaic, failing to adequately address the diverse emotional support needs of real-world scenarios. To tackle this challenge, we propose an innovative strategy-enhanced role-playing framework, designed to simulate authentic emotional support conversations. Specifically, our approach unfolds in two steps: (1) Strategy-Enhanced Role-Playing Interactions, which involve three pivotal roles -- Seeker, Strategy Counselor, and Supporter -- engaging in diverse scenarios to emulate real-world interactions and promote a broader range of dialogues; and (2) Emotional Support Agent Training, achieved through fine-tuning LLMs using our specially constructed dataset. Within this framework, we develop the \textbf{ServeForEmo} dataset, comprising an extensive collection of 3.7K+ multi-turn dialogues and 62.8K+ utterances. We further present \textbf{SweetieChat}, an emotional support agent capable of handling diverse open-domain scenarios. Extensive experiments and human evaluations confirm the framework's effectiveness in enhancing emotional support, highlighting its unique ability to provide more nuanced and tailored assistance.
Upper-Limb Rehabilitation with a Dual-Mode Individualized Exoskeleton Robot: A Generative-Model-Based Solution
Sep 05, 2024



Several upper-limb exoskeleton robots have been developed for stroke rehabilitation, but their rather low level of individualized assistance typically limits their effectiveness and practicability. Individualized assistance involves an upper-limb exoskeleton robot continuously assessing feedback from a stroke patient and then meticulously adjusting interaction forces to suit specific conditions and online changes. This paper describes the development of a new upper-limb exoskeleton robot with a novel online generative capability that allows it to provide individualized assistance to support the rehabilitation training of stroke patients. Specifically, the upper-limb exoskeleton robot exploits generative models to customize the fine and fit trajectory for the patient, as medical conditions, responses, and comfort feedback during training generally differ between patients. This generative capability is integrated into the two working modes of the upper-limb exoskeleton robot: an active mirroring mode for patients who retain motor abilities on one side of the body and a passive following mode for patients who lack motor ability on both sides of the body. The performance of the upper-limb exoskeleton robot was illustrated in experiments involving healthy subjects and stroke patients.