 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAMER: Project-Level Code Framework Dataset and Benchmark on Professional Game Engines
Jun 18, 2026Current AI-driven game development has made substantial progress in asset generation, gameplay design, and web-based game coding, yet project-level code engineering on professional game engines remains largely unexplored due to the absence of large-scale datasets and deterministic evaluation methods. We present JamSet and JamBench, the first project-level game code framework dataset and benchmark built on a professional game engine. Our key insight is that Game Jam competitions, community events where developers build complete games under tight time constraints, yield thousands of open-source projects suitable for this purpose. Building on the Godot engine's text-based format and headless execution mode, we design a deterministic verification pipeline from file integrity to runtime behavior collection, distilling 8,133 verified projects from over 240,000 repositories. Of these, 300 manually verified projects form JamBench; the rest constitute JamSet. JamBench defines theme-driven generation and code completion tasks, evaluated through a pipeline combining compilation pass rates, Structural Completeness Score (SCS), and Behavioral Alignment Score (BAS). Evaluation of 9 frontier models reveals a capability cliff as project scale increases, with runtime pass rates dropping from 80.4% on small projects to 5.7% on large ones (Task2a). Code Agents improve compilation rates yet yield no gains in runtime behavioral quality, indicating that the bottleneck lies in architectural design rather than syntactic correctness. Experiments validate JamSet as effective training data. All data and code are publicly available.
Experience Makes Skillful: Enabling Generalizable Medical Agent Reasoning via Self-Evolving Skill Memory
Jun 08, 2026Medical agent systems are increasingly expected to support interactive clinical decision making rather than only static question answering. In such settings, effective agents must reuse prior experience across evolving cases, yet existing memory mechanisms often retain raw historical traces that are redundant, noisy, and difficult to govern. More importantly, they rarely distinguish which memories are truly useful for future reasoning. This limits their ability to accumulate compact and reliable experience for long-horizon clinical reasoning. To close this gap, we propose SkeMex, a post-deployment self-evolution framework that improves medical agents through a skill-based memory without updating model weights. SkeMex distills informative interaction trajectories into structured skills that encode reusable procedural knowledge, and organizes them into a multi-branch repository spanning general, task-specific, and action-level experience. To determine which memories should be reused and retained, SkeMex estimates context-dependent utility from environment feedback and uses it to guide value-aware retrieval and repository governance. A closed-loop ``Read--Write--Assess--Govern" lifecycle further supports continual evolution by writing new skills, updating utilities, promoting useful memories, and removing harmful entries. Experiments across diverse clinical tasks show that SkeMex consistently outperforms representative memory-based agents in both offline and online settings. It also generalizes across model backbones and supports transferable skill memory. All data and code will be released publicly.
VimRAG: Navigating Massive Visual Context in Retrieval-Augmented Generation via Multimodal Memory Graph
Feb 13, 2026Effectively retrieving, reasoning, and understanding multimodal information remains a critical challenge for agentic systems. Traditional Retrieval-augmented Generation (RAG) methods rely on linear interaction histories, which struggle to handle long-context tasks, especially those involving information-sparse yet token-heavy visual data in iterative reasoning scenarios. To bridge this gap, we introduce VimRAG, a framework tailored for multimodal Retrieval-augmented Reasoning across text, images, and videos. Inspired by our systematic study, we model the reasoning process as a dynamic directed acyclic graph that structures the agent states and retrieved multimodal evidence. Building upon this structured memory, we introduce a Graph-Modulated Visual Memory Encoding mechanism, with which the significance of memory nodes is evaluated via their topological position, allowing the model to dynamically allocate high-resolution tokens to pivotal evidence while compressing or discarding trivial clues. To implement this paradigm, we propose a Graph-Guided Policy Optimization strategy. This strategy disentangles step-wise validity from trajectory-level rewards by pruning memory nodes associated with redundant actions, thereby facilitating fine-grained credit assignment. Extensive experiments demonstrate that VimRAG consistently achieves state-of-the-art performance on diverse multimodal RAG benchmarks. The code is available at https://github.com/Alibaba-NLP/VRAG.
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
ProSoftArena: Benchmarking Hierarchical Capabilities of Multimodal Agents in Professional Software Environments
Dec 30, 2025Multimodal agents are making rapid progress on general computer-use tasks, yet existing benchmarks remain largely confined to browsers and basic desktop applications, falling short in professional software workflows that dominate real-world scientific and industrial practice. To close this gap, we introduce ProSoftArena, a benchmark and platform specifically for evaluating multimodal agents in professional software environments. We establish the first capability hierarchy tailored to agent use of professional software and construct a benchmark of 436 realistic work and research tasks spanning 6 disciplines and 13 core professional applications. To ensure reliable and reproducible assessment, we build an executable real-computer environment with an execution-based evaluation framework and uniquely incorporate a human-in-the-loop evaluation paradigm. Extensive experiments show that even the best-performing agent attains only a 24.4\% success rate on L2 tasks and completely fails on L3 multi-software workflow. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents in professional software settings. This project is available at: https://prosoftarena.github.io.
Code-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
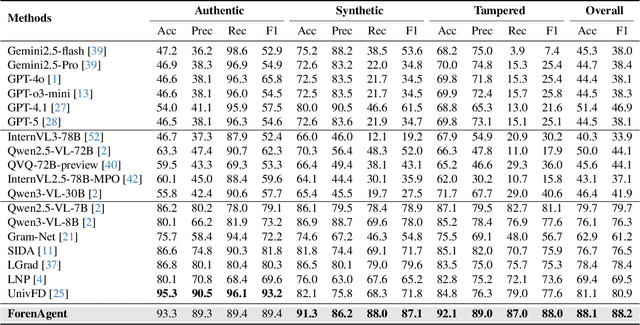
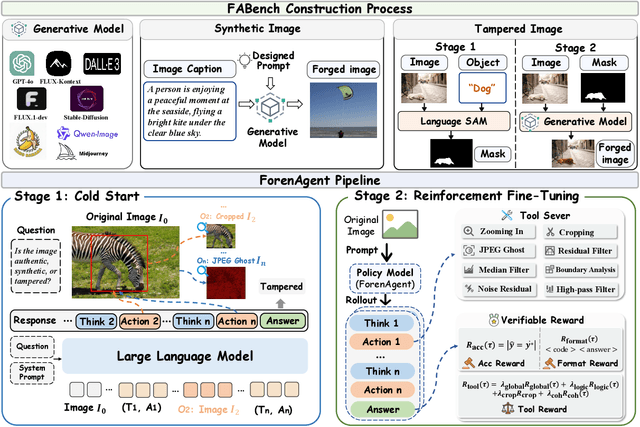
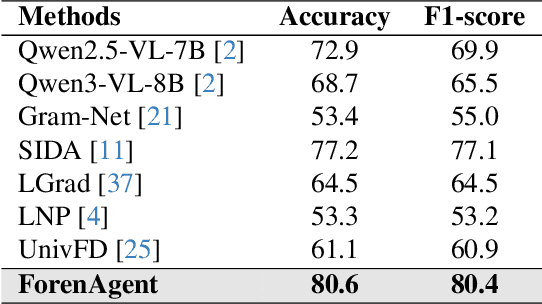
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.
Dialogue as Discovery: Navigating Human Intent Through Principled Inquiry
Oct 31, 2025A fundamental bottleneck in human-AI collaboration is the "intention expression gap," the difficulty for humans to effectively convey complex, high-dimensional thoughts to AI. This challenge often traps users in inefficient trial-and-error loops and is exacerbated by the diverse expertise levels of users. We reframe this problem from passive instruction following to a Socratic collaboration paradigm, proposing an agent that actively probes for information to resolve its uncertainty about user intent. we name the proposed agent Nous, trained to acquire proficiency in this inquiry policy. The core mechanism of Nous is a training framework grounded in the first principles of information theory. Within this framework, we define the information gain from dialogue as an intrinsic reward signal, which is fundamentally equivalent to the reduction of Shannon entropy over a structured task space. This reward design enables us to avoid reliance on costly human preference annotations or external reward models. To validate our framework, we develop an automated simulation pipeline to generate a large-scale, preference-based dataset for the challenging task of scientific diagram generation. Comprehensive experiments, including ablations, subjective and objective evaluations, and tests across user expertise levels, demonstrate the effectiveness of our proposed framework. Nous achieves leading efficiency and output quality, while remaining robust to varying user expertise. Moreover, its design is domain-agnostic, and we show evidence of generalization beyond diagram generation. Experimental results prove that our work offers a principled, scalable, and adaptive paradigm for resolving uncertainty about user intent in complex human-AI collaboration.
From Pixels to Paths: A Multi-Agent Framework for Editable Scientific Illustration
Oct 31, 2025Scientific illustrations demand both high information density and post-editability. However, current generative models have two major limitations: Frist, image generation models output rasterized images lacking semantic structure, making it impossible to access, edit, or rearrange independent visual components in the images. Second, code-based generation methods (TikZ or SVG), although providing element-level control, force users into the cumbersome cycle of "writing-compiling-reviewing" and lack the intuitiveness of manipulation. Neither of these two approaches can well meet the needs for efficiency, intuitiveness, and iterative modification in scientific creation. To bridge this gap, we introduce VisPainter, a multi-agent framework for scientific illustration built upon the model context protocol. VisPainter orchestrates three specialized modules-a Manager, a Designer, and a Toolbox-to collaboratively produce diagrams compatible with standard vector graphics software. This modular, role-based design allows each element to be explicitly represented and manipulated, enabling true element-level control and any element can be added and modified later. To systematically evaluate the quality of scientific illustrations, we introduce VisBench, a benchmark with seven-dimensional evaluation metrics. It assesses high-information-density scientific illustrations from four aspects: content, layout, visual perception, and interaction cost. To this end, we conducted extensive ablation experiments to verify the rationality of our architecture and the reliability of our evaluation methods. Finally, we evaluated various vision-language models, presenting fair and credible model rankings along with detailed comparisons of their respective capabilities. Additionally, we isolated and quantified the impacts of role division, step control,and description on the quality of illustrations.
MDK12-Bench: A Comprehensive Evaluation of Multimodal Large Language Models on Multidisciplinary Exams
Aug 09, 2025Multimodal large language models (MLLMs), which integrate language and visual cues for problem-solving, are crucial for advancing artificial general intelligence (AGI). However, current benchmarks for measuring the intelligence of MLLMs suffer from limited scale, narrow coverage, and unstructured knowledge, offering only static and undifferentiated evaluations. To bridge this gap, we introduce MDK12-Bench, a large-scale multidisciplinary benchmark built from real-world K-12 exams spanning six disciplines with 141K instances and 6,225 knowledge points organized in a six-layer taxonomy. Covering five question formats with difficulty and year annotations, it enables comprehensive evaluation to capture the extent to which MLLMs perform over four dimensions: 1) difficulty levels, 2) temporal (cross-year) shifts, 3) contextual shifts, and 4) knowledge-driven reasoning. We propose a novel dynamic evaluation framework that introduces unfamiliar visual, textual, and question form shifts to challenge model generalization while improving benchmark objectivity and longevity by mitigating data contamination. We further evaluate knowledge-point reference-augmented generation (KP-RAG) to examine the role of knowledge in problem-solving. Key findings reveal limitations in current MLLMs in multiple aspects and provide guidance for enhancing model robustness, interpretability, and AI-assisted education.
Sekai: A Video Dataset towards World Exploration
Jun 18, 2025Video generation techniques have made remarkable progress, promising to be the foundation of interactive world exploration. However, existing video generation datasets are not well-suited for world exploration training as they suffer from some limitations: limited locations, short duration, static scenes, and a lack of annotations about exploration and the world. In this paper, we introduce Sekai (meaning ``world'' in Japanese), a high-quality first-person view worldwide video dataset with rich annotations for world exploration. It consists of over 5,000 hours of walking or drone view (FPV and UVA) videos from over 100 countries and regions across 750 cities. We develop an efficient and effective toolbox to collect, pre-process and annotate videos with location, scene, weather, crowd density, captions, and camera trajectories. Experiments demonstrate the quality of the dataset. And, we use a subset to train an interactive video world exploration model, named YUME (meaning ``dream'' in Japanese). We believe Sekai will benefit the area of video generation and world exploration, and motivate valuable applications.