 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUPET: Incorporating Hierarchical Information Path into Multilingual ASR
Jan 08, 2024



Many factors have separately shown their effectiveness on improving multilingual ASR. They include language identity (LID) and phoneme information, language-specific processing modules and cross-lingual self-supervised speech representation, etc. However, few studies work on synergistically combining them to contribute a unified solution, which still remains an open question. To this end, a novel view to incorporate hierarchical information path LUPET into multilingual ASR is proposed. The LUPET is a path encoding multiple information in different granularity from shallow to deep encoder layers. Early information in this path is beneficial for deriving later occurred information. Specifically, the input goes from LID prediction to acoustic unit discovery followed by phoneme sharing, and then dynamically routed by mixture-of-expert for final token recognition. Experiments on 10 languages of Common Voice examined the superior performance of LUPET. Importantly, LUPET significantly boosts the recognition on high-resource languages, thus mitigating the compromised phenomenon towards low-resource languages in a multilingual setting.
Experiential Co-Learning of Software-Developing Agents
Dec 29, 2023


Recent advancements in large language models (LLMs) have brought significant changes to various domains, especially through LLM-driven autonomous agents. These agents are now capable of collaborating seamlessly, splitting tasks and enhancing accuracy, thus minimizing the need for human involvement. However, these agents often approach a diverse range of tasks in isolation, without benefiting from past experiences. This isolation can lead to repeated mistakes and inefficient trials in task solving. To this end, this paper introduces Experiential Co-Learning, a novel framework in which instructor and assistant agents gather shortcut-oriented experiences from their historical trajectories and use these past experiences for mutual reasoning. This paradigm, enriched with previous experiences, equips agents to more effectively address unseen tasks.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning
Dec 25, 2023Instruction tuning is a standard technique employed to align large language models to end tasks and user preferences after the initial pretraining phase. Recent research indicates the critical role of data engineering in instruction tuning -- when appropriately selected, only limited data is necessary to achieve superior performance. However, we still lack a principled understanding of what makes good instruction tuning data for alignment, and how we should select data automatically and effectively. In this work, we delve deeply into automatic data selection strategies for alignment. We start with controlled studies to measure data across three dimensions: complexity, quality, and diversity, along which we examine existing methods and introduce novel techniques for enhanced data measurement. Subsequently, we propose a simple strategy to select data samples based on the measurement. We present deita (short for Data-Efficient Instruction Tuning for Alignment), a series of models fine-tuned from LLaMA and Mistral models using data samples automatically selected with our proposed approach. Empirically, deita performs better or on par with the state-of-the-art open-source alignment models with only 6K SFT training data samples -- over 10x less than the data used in the baselines. When further trained with direct preference optimization (DPO), deita-Mistral-7B + DPO trained with 6K SFT and 10K DPO samples achieve 7.55 MT-Bench and 90.06% AlpacaEval scores. We anticipate this work to provide tools on automatic data selection, facilitating data-efficient alignment. We release our models as well as the selected datasets for future researches to effectively align models more efficiently.
DreamTuner: Single Image is Enough for Subject-Driven Generation
Dec 21, 2023Diffusion-based models have demonstrated impressive capabilities for text-to-image generation and are expected for personalized applications of subject-driven generation, which require the generation of customized concepts with one or a few reference images. However, existing methods based on fine-tuning fail to balance the trade-off between subject learning and the maintenance of the generation capabilities of pretrained models. Moreover, other methods that utilize additional image encoders tend to lose important details of the subject due to encoding compression. To address these challenges, we propose DreamTurner, a novel method that injects reference information from coarse to fine to achieve subject-driven image generation more effectively. DreamTurner introduces a subject-encoder for coarse subject identity preservation, where the compressed general subject features are introduced through an attention layer before visual-text cross-attention. We then modify the self-attention layers within pretrained text-to-image models to self-subject-attention layers to refine the details of the target subject. The generated image queries detailed features from both the reference image and itself in self-subject-attention. It is worth emphasizing that self-subject-attention is an effective, elegant, and training-free method for maintaining the detailed features of customized subjects and can serve as a plug-and-play solution during inference. Finally, with additional subject-driven fine-tuning, DreamTurner achieves remarkable performance in subject-driven image generation, which can be controlled by a text or other conditions such as pose. For further details, please visit the project page at https://dreamtuner-diffusion.github.io/.
Decoupling Representation and Knowledge for Few-Shot Intent Classification and Slot Filling
Dec 21, 2023

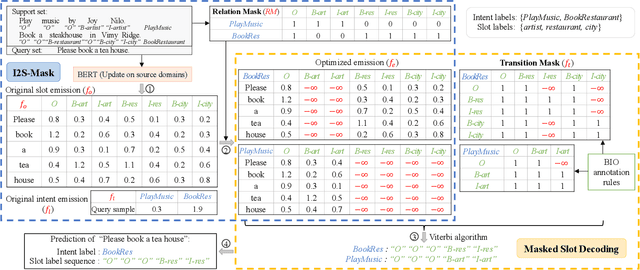
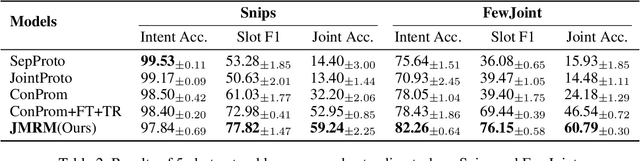
Few-shot intent classification and slot filling are important but challenging tasks due to the scarcity of finely labeled data. Therefore, current works first train a model on source domains with sufficiently labeled data, and then transfer the model to target domains where only rarely labeled data is available. However, experience transferring as a whole usually suffers from gaps that exist among source domains and target domains. For instance, transferring domain-specific-knowledge-related experience is difficult. To tackle this problem, we propose a new method that explicitly decouples the transferring of general-semantic-representation-related experience and the domain-specific-knowledge-related experience. Specifically, for domain-specific-knowledge-related experience, we design two modules to capture intent-slot relation and slot-slot relation respectively. Extensive experiments on Snips and FewJoint datasets show that our method achieves state-of-the-art performance. The method improves the joint accuracy metric from 27.72% to 42.20% in the 1-shot setting, and from 46.54% to 60.79% in the 5-shot setting.
Robot Crowd Navigation in Dynamic Environment with Offline Reinforcement Learning
Dec 18, 2023Robot crowd navigation has been gaining increasing attention and popularity in various practical applications. In existing research, deep reinforcement learning has been applied to robot crowd navigation by training policies in an online mode. However, this inevitably leads to unsafe exploration, and consequently causes low sampling efficiency during pedestrian-robot interaction. To this end, we propose an offline reinforcement learning based robot crowd navigation algorithm by utilizing pre-collected crowd navigation experience. Specifically, this algorithm integrates a spatial-temporal state into implicit Q-Learning to avoid querying out-of-distribution robot actions of the pre-collected experience, while capturing spatial-temporal features from the offline pedestrian-robot interactions. Experimental results demonstrate that the proposed algorithm outperforms the state-of-the-art methods by means of qualitative and quantitative analysis.
T-Code: Simple Temporal Latent Code for Efficient Dynamic View Synthesis
Dec 18, 2023Novel view synthesis for dynamic scenes is one of the spotlights in computer vision. The key to efficient dynamic view synthesis is to find a compact representation to store the information across time. Though existing methods achieve fast dynamic view synthesis by tensor decomposition or hash grid feature concatenation, their mixed representations ignore the structural difference between time domain and spatial domain, resulting in sub-optimal computation and storage cost. This paper presents T-Code, the efficient decoupled latent code for the time dimension only. The decomposed feature design enables customizing modules to cater for different scenarios with individual specialty and yielding desired results at lower cost. Based on T-Code, we propose our highly compact hybrid neural graphics primitives (HybridNGP) for multi-camera setting and deformation neural graphics primitives with T-Code (DNGP-T) for monocular scenario. Experiments show that HybridNGP delivers high fidelity results at top processing speed with much less storage consumption, while DNGP-T achieves state-of-the-art quality and high training speed for monocular reconstruction.
Enhancing the Rationale-Input Alignment for Self-explaining Rationalization
Dec 15, 2023



Rationalization empowers deep learning models with self-explaining capabilities through a cooperative game, where a generator selects a semantically consistent subset of the input as a rationale, and a subsequent predictor makes predictions based on the selected rationale. In this paper, we discover that rationalization is prone to a problem named \emph{rationale shift}, which arises from the algorithmic bias of the cooperative game. Rationale shift refers to a situation where the semantics of the selected rationale may deviate from the original input, but the predictor still produces accurate predictions based on the deviation, resulting in a compromised generator with misleading feedback. To address this issue, we first demonstrate the importance of the alignment between the rationale and the full input through both empirical observations and theoretical analysis. Subsequently, we introduce a novel approach called DAR (\textbf{D}iscriminatively \textbf{A}ligned \textbf{R}ationalization), which utilizes an auxiliary module pretrained on the full input to discriminatively align the selected rationale and the original input. We theoretically illustrate how DAR accomplishes the desired alignment, thereby overcoming the rationale shift problem. The experiments on two widely used real-world benchmarks show that the proposed method significantly improves the explanation quality (measured by the overlap between the model-selected explanation and the human-annotated rationale) as compared to state-of-the-art techniques. Additionally, results on two synthetic settings further validate the effectiveness of DAR in addressing the rationale shift problem.
Local Conditional Controlling for Text-to-Image Diffusion Models
Dec 14, 2023Diffusion models have exhibited impressive prowess in the text-to-image task. Recent methods add image-level controls, e.g., edge and depth maps, to manipulate the generation process together with text prompts to obtain desired images. This controlling process is globally operated on the entire image, which limits the flexibility of control regions. In this paper, we introduce a new simple yet practical task setting: local control. It focuses on controlling specific local areas according to user-defined image conditions, where the rest areas are only conditioned by the original text prompt. This manner allows the users to flexibly control the image generation in a fine-grained way. However, it is non-trivial to achieve this goal. The naive manner of directly adding local conditions may lead to the local control dominance problem. To mitigate this problem, we propose a training-free method that leverages the updates of noised latents and parameters in the cross-attention map during the denosing process to promote concept generation in non-control areas. Moreover, we use feature mask constraints to mitigate the degradation of synthesized image quality caused by information differences inside and outside the local control area. Extensive experiments demonstrate that our method can synthesize high-quality images to the prompt under local control conditions. Code is available at https://github.com/YibooZhao/Local-Control.