 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient 4D Gaussian Stream with Low Rank Adaptation
Feb 23, 2025Recent methods have made significant progress in synthesizing novel views with long video sequences. This paper proposes a highly scalable method for dynamic novel view synthesis with continual learning. We leverage the 3D Gaussians to represent the scene and a low-rank adaptation-based deformation model to capture the dynamic scene changes. Our method continuously reconstructs the dynamics with chunks of video frames, reduces the streaming bandwidth by $90\%$ while maintaining high rendering quality comparable to the off-line SOTA methods.
CD-NGP: A Fast Scalable Continual Representation for Dynamic Scenes
Sep 08, 2024



We present CD-NGP, which is a fast and scalable representation for 3D reconstruction and novel view synthesis in dynamic scenes. Inspired by continual learning, our method first segments input videos into multiple chunks, followed by training the model chunk by chunk, and finally, fuses features of the first branch and subsequent branches. Experiments on the prevailing DyNeRF dataset demonstrate that our proposed novel representation reaches a great balance between memory consumption, model size, training speed, and rendering quality. Specifically, our method consumes $85\%$ less training memory ($<14$GB) than offline methods and requires significantly lower streaming bandwidth ($<0.4$MB/frame) than other online alternatives.
FASTC: A Fast Attentional Framework for Semantic Traversability Classification Using Point Cloud
Jun 24, 2024



Producing traversability maps and understanding the surroundings are crucial prerequisites for autonomous navigation. In this paper, we address the problem of traversability assessment using point clouds. We propose a novel pillar feature extraction module that utilizes PointNet to capture features from point clouds organized in vertical volume and a 2D encoder-decoder structure to conduct traversability classification instead of the widely used 3D convolutions. This results in less computational cost while even better performance is achieved at the same time. We then propose a new spatio-temporal attention module to fuse multi-frame information, which can properly handle the varying density problem of LIDAR point clouds, and this makes our module able to assess distant areas more accurately. Comprehensive experimental results on augmented Semantic KITTI and RELLIS-3D datasets show that our method is able to achieve superior performance over existing approaches both quantitatively and quantitatively.
T-Code: Simple Temporal Latent Code for Efficient Dynamic View Synthesis
Dec 18, 2023Novel view synthesis for dynamic scenes is one of the spotlights in computer vision. The key to efficient dynamic view synthesis is to find a compact representation to store the information across time. Though existing methods achieve fast dynamic view synthesis by tensor decomposition or hash grid feature concatenation, their mixed representations ignore the structural difference between time domain and spatial domain, resulting in sub-optimal computation and storage cost. This paper presents T-Code, the efficient decoupled latent code for the time dimension only. The decomposed feature design enables customizing modules to cater for different scenarios with individual specialty and yielding desired results at lower cost. Based on T-Code, we propose our highly compact hybrid neural graphics primitives (HybridNGP) for multi-camera setting and deformation neural graphics primitives with T-Code (DNGP-T) for monocular scenario. Experiments show that HybridNGP delivers high fidelity results at top processing speed with much less storage consumption, while DNGP-T achieves state-of-the-art quality and high training speed for monocular reconstruction.
Unsupervised Coherent Video Cartoonization with Perceptual Motion Consistency
Apr 02, 2022
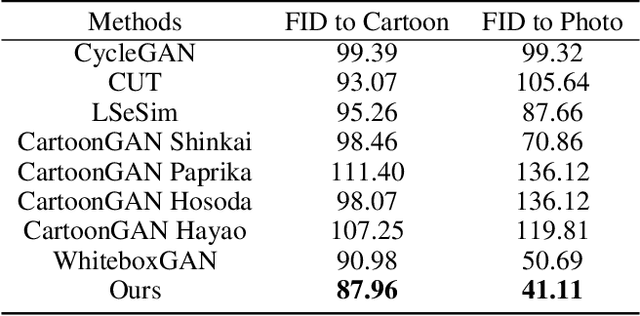

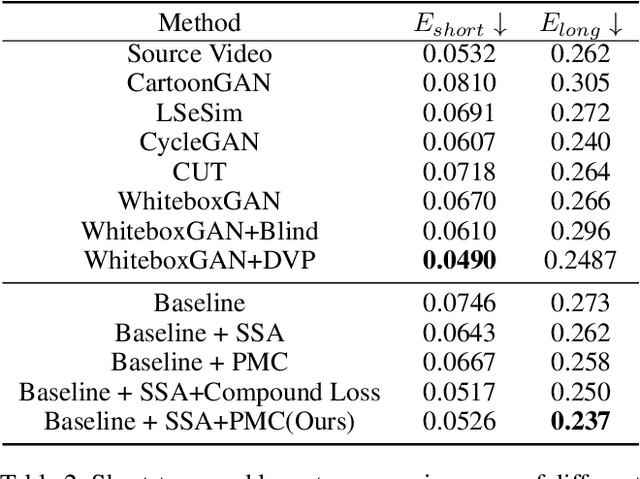
In recent years, creative content generations like style transfer and neural photo editing have attracted more and more attention. Among these, cartoonization of real-world scenes has promising applications in entertainment and industry. Different from image translations focusing on improving the style effect of generated images, video cartoonization has additional requirements on the temporal consistency. In this paper, we propose a spatially-adaptive semantic alignment framework with perceptual motion consistency for coherent video cartoonization in an unsupervised manner. The semantic alignment module is designed to restore deformation of semantic structure caused by spatial information lost in the encoder-decoder architecture. Furthermore, we devise the spatio-temporal correlative map as a style-independent, global-aware regularization on the perceptual motion consistency. Deriving from similarity measurement of high-level features in photo and cartoon frames, it captures global semantic information beyond raw pixel-value in optical flow. Besides, the similarity measurement disentangles temporal relationships from domain-specific style properties, which helps regularize the temporal consistency without hurting style effects of cartoon images. Qualitative and quantitative experiments demonstrate our method is able to generate highly stylistic and temporal consistent cartoon videos.
IR-GAN: Image Manipulation with Linguistic Instruction by Increment Reasoning
Apr 02, 2022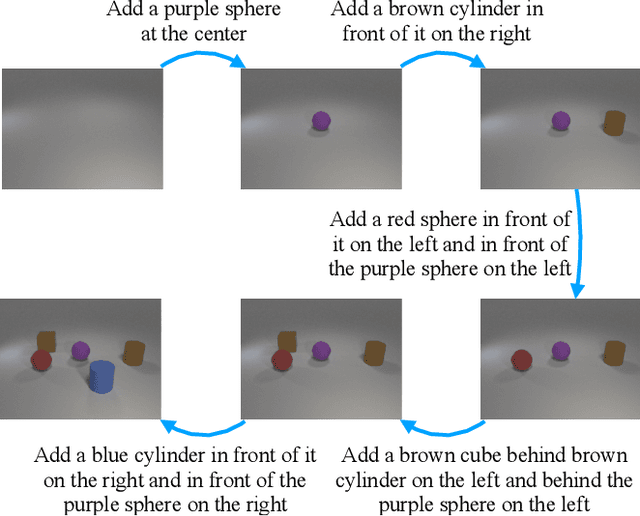
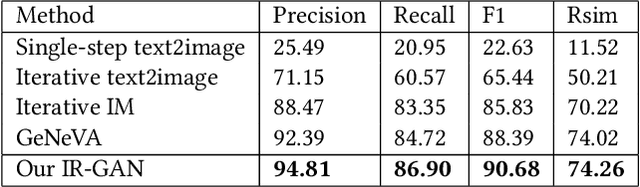
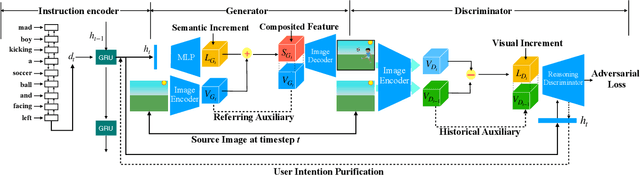
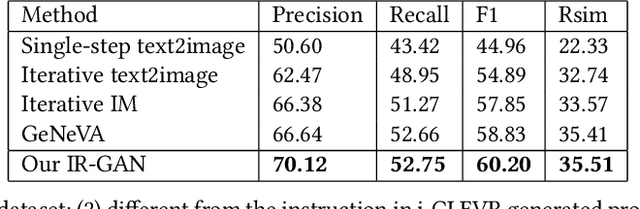
Conditional image generation is an active research topic including text2image and image translation. Recently image manipulation with linguistic instruction brings new challenges of multimodal conditional generation. However, traditional conditional image generation models mainly focus on generating high-quality and visually realistic images, and lack resolving the partial consistency between image and instruction. To address this issue, we propose an Increment Reasoning Generative Adversarial Network (IR-GAN), which aims to reason the consistency between visual increment in images and semantic increment in instructions. First, we introduce the word-level and instruction-level instruction encoders to learn user's intention from history-correlated instructions as semantic increment. Second, we embed the representation of semantic increment into that of source image for generating target image, where source image plays the role of referring auxiliary. Finally, we propose a reasoning discriminator to measure the consistency between visual increment and semantic increment, which purifies user's intention and guarantees the good logic of generated target image. Extensive experiments and visualization conducted on two datasets show the effectiveness of IR-GAN.