 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvo-MedAgent: Beyond One-Shot Diagnosis with Agents That Remember, Reflect, and Improve
Apr 15, 2026Tool-augmented large language model (LLM) agents can orchestrate specialist classifiers, segmentation models, and visual question-answering modules to interpret chest X-rays. However, these agents still solve each case in isolation: they fail to accumulate experience across cases, correct recurrent reasoning mistakes, or adapt their tool-use behavior without expensive reinforcement learning. While a radiologist naturally improves with every case, current agents remain static. In this work, we propose Evo-MedAgent, a self-evolving memory module that equips a medical agent with the capacity for inter-case learning at test time. Our memory comprises three complementary stores: (1)~\emph{Retrospective Clinical Episodes} that retrieve problem-solving experiences from similar past cases, (2)~an \emph{Adaptive Procedural Heuristics} bank curating priority-tagged diagnostic rules that evolves via reflection, much like a physician refining their internal criteria, and (3)~a \emph{Tool Reliability Controller} that tracks per-tool trustworthiness. On ChestAgentBench, Evo-MedAgent raises multiple-choice question (MCQ) accuracy from 0.68 to 0.79 on GPT-5-mini, and from 0.76 to 0.87 on Gemini-3 Flash. With a strong base model, evolving memory improves performance more effectively than orchestrating external tools on qualitative diagnostic tasks. Because Evo-MedAgent requires no training, its per-case overhead is bounded by one additional retrieval pass and a single reflection call, making it deployable on top of any frozen model.
MedMASLab: A Unified Orchestration Framework for Benchmarking Multimodal Medical Multi-Agent Systems
Mar 10, 2026While Multi-Agent Systems (MAS) show potential for complex clinical decision support, the field remains hindered by architectural fragmentation and the lack of standardized multimodal integration. Current medical MAS research suffers from non-uniform data ingestion pipelines, inconsistent visual-reasoning evaluation, and a lack of cross-specialty benchmarking. To address these challenges, we present MedMASLab, a unified framework and benchmarking platform for multimodal medical multi-agent systems. MedMASLab introduces: (1) A standardized multimodal agent communication protocol that enables seamless integration of 11 heterogeneous MAS architectures across 24 medical modalities. (2) An automated clinical reasoning evaluator, a zero-shot semantic evaluation paradigm that overcomes the limitations of lexical string-matching by leveraging large vision-language models to verify diagnostic logic and visual grounding. (3) The most extensive benchmark to date, spanning 11 organ systems and 473 diseases, standardizing data from 11 clinical benchmarks. Our systematic evaluation reveals a critical domain-specific performance gap: while MAS improves reasoning depth, current architectures exhibit significant fragility when transitioning between specialized medical sub-domains. We provide a rigorous ablation of interaction mechanisms and cost-performance trade-offs, establishing a new technical baseline for future autonomous clinical systems. The source code and data is publicly available at: https://github.com/NUS-Project/MedMASLab/
VariViT: A Vision Transformer for Variable Image Sizes
Feb 16, 2026Vision Transformers (ViTs) have emerged as the state-of-the-art architecture in representation learning, leveraging self-attention mechanisms to excel in various tasks. ViTs split images into fixed-size patches, constraining them to a predefined size and necessitating pre-processing steps like resizing, padding, or cropping. This poses challenges in medical imaging, particularly with irregularly shaped structures like tumors. A fixed bounding box crop size produces input images with highly variable foreground-to-background ratios. Resizing medical images can degrade information and introduce artefacts, impacting diagnosis. Hence, tailoring variable-sized crops to regions of interest can enhance feature representation capabilities. Moreover, large images are computationally expensive, and smaller sizes risk information loss, presenting a computation-accuracy tradeoff. We propose VariViT, an improved ViT model crafted to handle variable image sizes while maintaining a consistent patch size. VariViT employs a novel positional embedding resizing scheme for a variable number of patches. We also implement a new batching strategy within VariViT to reduce computational complexity, resulting in faster training and inference times. In our evaluations on two 3D brain MRI datasets, VariViT surpasses vanilla ViTs and ResNet in glioma genotype prediction and brain tumor classification. It achieves F1-scores of 75.5% and 76.3%, respectively, learning more discriminative features. Our proposed batching strategy reduces computation time by up to 30% compared to conventional architectures. These findings underscore the efficacy of VariViT in image representation learning. Our code can be found here: https://github.com/Aswathi-Varma/varivit
Standardized Evaluation of Automatic Methods for Perivascular Spaces Segmentation in MRI -- MICCAI 2024 Challenge Results
Dec 20, 2025



Perivascular spaces (PVS), when abnormally enlarged and visible in magnetic resonance imaging (MRI) structural sequences, are important imaging markers of cerebral small vessel disease and potential indicators of neurodegenerative conditions. Despite their clinical significance, automatic enlarged PVS (EPVS) segmentation remains challenging due to their small size, variable morphology, similarity with other pathological features, and limited annotated datasets. This paper presents the EPVS Challenge organized at MICCAI 2024, which aims to advance the development of automated algorithms for EPVS segmentation across multi-site data. We provided a diverse dataset comprising 100 training, 50 validation, and 50 testing scans collected from multiple international sites (UK, Singapore, and China) with varying MRI protocols and demographics. All annotations followed the STRIVE protocol to ensure standardized ground truth and covered the full brain parenchyma. Seven teams completed the full challenge, implementing various deep learning approaches primarily based on U-Net architectures with innovations in multi-modal processing, ensemble strategies, and transformer-based components. Performance was evaluated using dice similarity coefficient, absolute volume difference, recall, and precision metrics. The winning method employed MedNeXt architecture with a dual 2D/3D strategy for handling varying slice thicknesses. The top solutions showed relatively good performance on test data from seen datasets, but significant degradation of performance was observed on the previously unseen Shanghai cohort, highlighting cross-site generalization challenges due to domain shift. This challenge establishes an important benchmark for EPVS segmentation methods and underscores the need for the continued development of robust algorithms that can generalize in diverse clinical settings.
Template-Guided Reconstruction of Pulmonary Segments with Neural Implicit Functions
May 13, 2025



High-quality 3D reconstruction of pulmonary segments plays a crucial role in segmentectomy and surgical treatment planning for lung cancer. Due to the resolution requirement of the target reconstruction, conventional deep learning-based methods often suffer from computational resource constraints or limited granularity. Conversely, implicit modeling is favored due to its computational efficiency and continuous representation at any resolution. We propose a neural implicit function-based method to learn a 3D surface to achieve anatomy-aware, precise pulmonary segment reconstruction, represented as a shape by deforming a learnable template. Additionally, we introduce two clinically relevant evaluation metrics to assess the reconstruction comprehensively. Further, due to the absence of publicly available shape datasets to benchmark reconstruction algorithms, we developed a shape dataset named Lung3D, including the 3D models of 800 labeled pulmonary segments and the corresponding airways, arteries, veins, and intersegmental veins. We demonstrate that the proposed approach outperforms existing methods, providing a new perspective for pulmonary segment reconstruction. Code and data will be available at https://github.com/M3DV/ImPulSe.
Advances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025


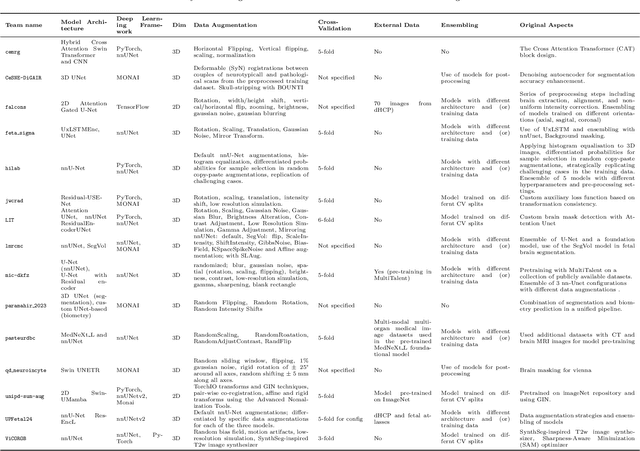
Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
Analysis of the MICCAI Brain Tumor Segmentation -- Metastases (BraTS-METS) 2025 Lighthouse Challenge: Brain Metastasis Segmentation on Pre- and Post-treatment MRI
Apr 16, 2025Despite continuous advancements in cancer treatment, brain metastatic disease remains a significant complication of primary cancer and is associated with an unfavorable prognosis. One approach for improving diagnosis, management, and outcomes is to implement algorithms based on artificial intelligence for the automated segmentation of both pre- and post-treatment MRI brain images. Such algorithms rely on volumetric criteria for lesion identification and treatment response assessment, which are still not available in clinical practice. Therefore, it is critical to establish tools for rapid volumetric segmentations methods that can be translated to clinical practice and that are trained on high quality annotated data. The BraTS-METS 2025 Lighthouse Challenge aims to address this critical need by establishing inter-rater and intra-rater variability in dataset annotation by generating high quality annotated datasets from four individual instances of segmentation by neuroradiologists while being recorded on video (two instances doing "from scratch" and two instances after AI pre-segmentation). This high-quality annotated dataset will be used for testing phase in 2025 Lighthouse challenge and will be publicly released at the completion of the challenge. The 2025 Lighthouse challenge will also release the 2023 and 2024 segmented datasets that were annotated using an established pipeline of pre-segmentation, student annotation, two neuroradiologists checking, and one neuroradiologist finalizing the process. It builds upon its previous edition by including post-treatment cases in the dataset. Using these high-quality annotated datasets, the 2025 Lighthouse challenge plans to test benchmark algorithms for automated segmentation of pre-and post-treatment brain metastases (BM), trained on diverse and multi-institutional datasets of MRI images obtained from patients with brain metastases.
MedVLM-R1: Incentivizing Medical Reasoning Capability of Vision-Language Models (VLMs) via Reinforcement Learning
Feb 26, 2025


Reasoning is a critical frontier for advancing medical image analysis, where transparency and trustworthiness play a central role in both clinician trust and regulatory approval. Although Medical Visual Language Models (VLMs) show promise for radiological tasks, most existing VLMs merely produce final answers without revealing the underlying reasoning. To address this gap, we introduce MedVLM-R1, a medical VLM that explicitly generates natural language reasoning to enhance transparency and trustworthiness. Instead of relying on supervised fine-tuning (SFT), which often suffers from overfitting to training distributions and fails to foster genuine reasoning, MedVLM-R1 employs a reinforcement learning framework that incentivizes the model to discover human-interpretable reasoning paths without using any reasoning references. Despite limited training data (600 visual question answering samples) and model parameters (2B), MedVLM-R1 boosts accuracy from 55.11% to 78.22% across MRI, CT, and X-ray benchmarks, outperforming larger models trained on over a million samples. It also demonstrates robust domain generalization under out-of-distribution tasks. By unifying medical image analysis with explicit reasoning, MedVLM-R1 marks a pivotal step toward trustworthy and interpretable AI in clinical practice.
TV-based Deep 3D Self Super-Resolution for fMRI
Oct 05, 2024



While functional Magnetic Resonance Imaging (fMRI) offers valuable insights into cognitive processes, its inherent spatial limitations pose challenges for detailed analysis of the fine-grained functional architecture of the brain. More specifically, MRI scanner and sequence specifications impose a trade-off between temporal resolution, spatial resolution, signal-to-noise ratio, and scan time. Deep Learning (DL) Super-Resolution (SR) methods have emerged as a promising solution to enhance fMRI resolution, generating high-resolution (HR) images from low-resolution (LR) images typically acquired with lower scanning times. However, most existing SR approaches depend on supervised DL techniques, which require training ground truth (GT) HR data, which is often difficult to acquire and simultaneously sets a bound for how far SR can go. In this paper, we introduce a novel self-supervised DL SR model that combines a DL network with an analytical approach and Total Variation (TV) regularization. Our method eliminates the need for external GT images, achieving competitive performance compared to supervised DL techniques and preserving the functional maps.
Learning Brain Tumor Representation in 3D High-Resolution MR Images via Interpretable State Space Models
Sep 12, 2024



Learning meaningful and interpretable representations from high-dimensional volumetric magnetic resonance (MR) images is essential for advancing personalized medicine. While Vision Transformers (ViTs) have shown promise in handling image data, their application to 3D multi-contrast MR images faces challenges due to computational complexity and interpretability. To address this, we propose a novel state-space-model (SSM)-based masked autoencoder which scales ViT-like models to handle high-resolution data effectively while also enhancing the interpretability of learned representations. We propose a latent-to-spatial mapping technique that enables direct visualization of how latent features correspond to specific regions in the input volumes in the context of SSM. We validate our method on two key neuro-oncology tasks: identification of isocitrate dehydrogenase mutation status and 1p/19q co-deletion classification, achieving state-of-the-art accuracy. Our results highlight the potential of SSM-based self-supervised learning to transform radiomics analysis by combining efficiency and interpretability.