 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquisition through My Eyes and Steps: A Joint Predictive Agent Model in Egocentric Worlds
Feb 09, 2025This paper addresses the task of learning an agent model behaving like humans, which can jointly perceive, predict, and act in egocentric worlds. Previous methods usually train separate models for these three abilities, leading to information silos among them, which prevents these abilities from learning from each other and collaborating effectively. In this paper, we propose a joint predictive agent model, named EgoAgent, that simultaneously learns to represent the world, predict future states, and take reasonable actions with a single transformer. EgoAgent unifies the representational spaces of the three abilities by mapping them all into a sequence of continuous tokens. Learnable query tokens are appended to obtain current states, future states, and next actions. With joint supervision, our agent model establishes the internal relationship among these three abilities and effectively mimics the human inference and learning processes. Comprehensive evaluations of EgoAgent covering image classification, egocentric future state prediction, and 3D human motion prediction tasks demonstrate the superiority of our method. The code and trained model will be released for reproducibility.
Satellite Observations Guided Diffusion Model for Accurate Meteorological States at Arbitrary Resolution
Feb 09, 2025



Accurate acquisition of surface meteorological conditions at arbitrary locations holds significant importance for weather forecasting and climate simulation. Due to the fact that meteorological states derived from satellite observations are often provided in the form of low-resolution grid fields, the direct application of spatial interpolation to obtain meteorological states for specific locations often results in significant discrepancies when compared to actual observations. Existing downscaling methods for acquiring meteorological state information at higher resolutions commonly overlook the correlation with satellite observations. To bridge the gap, we propose Satellite-observations Guided Diffusion Model (SGD), a conditional diffusion model pre-trained on ERA5 reanalysis data with satellite observations (GridSat) as conditions, which is employed for sampling downscaled meteorological states through a zero-shot guided sampling strategy and patch-based methods. During the training process, we propose to fuse the information from GridSat satellite observations into ERA5 maps via the attention mechanism, enabling SGD to generate atmospheric states that align more accurately with actual conditions. In the sampling, we employed optimizable convolutional kernels to simulate the upscale process, thereby generating high-resolution ERA5 maps using low-resolution ERA5 maps as well as observations from weather stations as guidance. Moreover, our devised patch-based method promotes SGD to generate meteorological states at arbitrary resolutions. Experiments demonstrate SGD fulfills accurate meteorological states downscaling to 6.25km.
MindAligner: Explicit Brain Functional Alignment for Cross-Subject Visual Decoding from Limited fMRI Data
Feb 07, 2025



Brain decoding aims to reconstruct visual perception of human subject from fMRI signals, which is crucial for understanding brain's perception mechanisms. Existing methods are confined to the single-subject paradigm due to substantial brain variability, which leads to weak generalization across individuals and incurs high training costs, exacerbated by limited availability of fMRI data. To address these challenges, we propose MindAligner, an explicit functional alignment framework for cross-subject brain decoding from limited fMRI data. The proposed MindAligner enjoys several merits. First, we learn a Brain Transfer Matrix (BTM) that projects the brain signals of an arbitrary new subject to one of the known subjects, enabling seamless use of pre-trained decoding models. Second, to facilitate reliable BTM learning, a Brain Functional Alignment module is proposed to perform soft cross-subject brain alignment under different visual stimuli with a multi-level brain alignment loss, uncovering fine-grained functional correspondences with high interpretability. Experiments indicate that MindAligner not only outperforms existing methods in visual decoding under data-limited conditions, but also provides valuable neuroscience insights in cross-subject functional analysis. The code will be made publicly available.
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
DispFormer: Pretrained Transformer for Flexible Dispersion Curve Inversion from Global Synthesis to Regional Applications
Jan 08, 2025



Surface wave dispersion curve inversion is essential for estimating subsurface Shear-wave velocity ($v_s$), yet traditional methods often struggle to balance computational efficiency with inversion accuracy. While deep learning approaches show promise, previous studies typically require large amounts of labeled data and struggle with real-world datasets that have varying period ranges, missing data, and low signal-to-noise ratios. This study proposes DispFormer, a transformer-based neural network for inverting the $v_s$ profile from Rayleigh-wave phase and group dispersion curves. DispFormer processes dispersion data at each period independently, thereby allowing it to handle data of varying lengths without requiring network modifications or alignment between training and testing data. The performance is demonstrated by pre-training it on a global synthetic dataset and testing it on two regional synthetic datasets using zero-shot and few-shot strategies. Results indicate that zero-shot DispFormer, even without any labeled data, produces inversion profiles that match well with the ground truth, providing a deployable initial model generator to assist traditional methods. When labeled data is available, few-shot DispFormer outperforms traditional methods with only a small number of labels. Furthermore, real-world tests indicate that DispFormer effectively handles varying length data, and yields lower data residuals than reference models. These findings demonstrate that DispFormer provides a robust foundation model for dispersion curve inversion and is a promising approach for broader applications.
Dolphin: Closed-loop Open-ended Auto-research through Thinking, Practice, and Feedback
Jan 07, 2025



The scientific research paradigm is undergoing a profound transformation owing to the development of Artificial Intelligence (AI). Recent works demonstrate that various AI-assisted research methods can largely improve research efficiency by improving data analysis, accelerating computation, and fostering novel idea generation. To further move towards the ultimate goal (i.e., automatic scientific research), in this paper, we propose Dolphin, the first closed-loop open-ended auto-research framework to further build the entire process of human scientific research. Dolphin can generate research ideas, perform experiments, and get feedback from experimental results to generate higher-quality ideas. More specifically, Dolphin first generates novel ideas based on relevant papers which are ranked by the topic and task attributes. Then, the codes are automatically generated and debugged with the exception-traceback-guided local code structure. Finally, Dolphin automatically analyzes the results of each idea and feeds the results back to the next round of idea generation. Experiments are conducted on the benchmark datasets of different topics and results show that Dolphin can generate novel ideas continuously and complete the experiment in a loop. We highlight that Dolphin can automatically propose methods that are comparable to the state-of-the-art in some tasks such as 2D image classification and 3D point classification.
Biology Instructions: A Dataset and Benchmark for Multi-Omics Sequence Understanding Capability of Large Language Models
Dec 26, 2024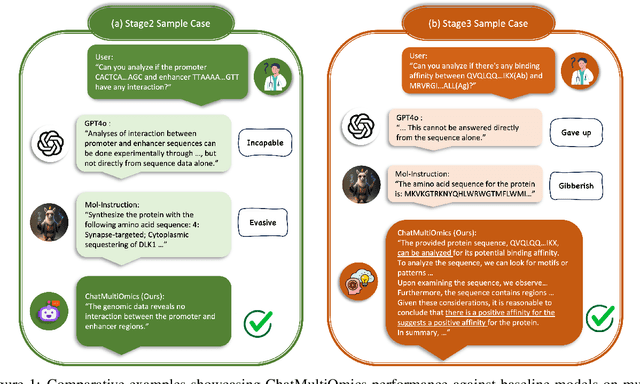
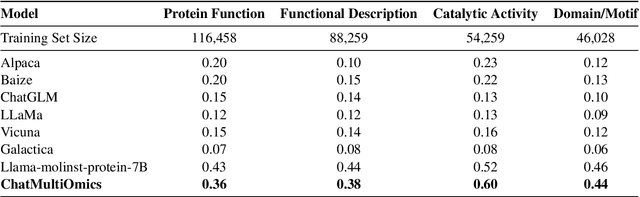
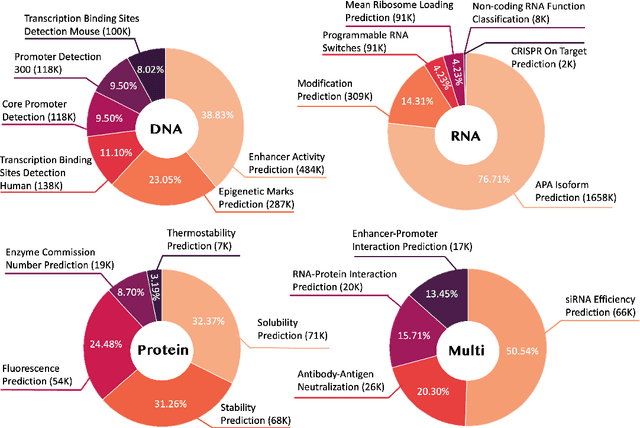
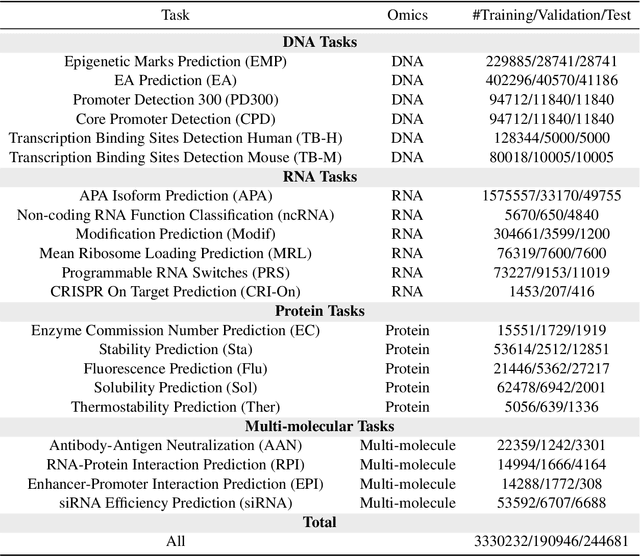
Large language models have already demonstrated their formidable capabilities in general domains, ushering in a revolutionary transformation. However, exploring and exploiting the extensive knowledge of these models to comprehend multi-omics biology remains underexplored. To fill this research gap, we first introduce Biology-Instructions, the first large-scale multi-omics biological sequences-related instruction-tuning dataset including DNA, RNA, proteins, and multi-molecules, designed to bridge the gap between large language models (LLMs) and complex biological sequences-related tasks. This dataset can enhance the versatility of LLMs by integrating diverse biological sequenced-based prediction tasks with advanced reasoning capabilities, while maintaining conversational fluency. Additionally, we reveal significant performance limitations in even state-of-the-art LLMs on biological sequence-related multi-omics tasks without specialized pre-training and instruction-tuning. We further develop a strong baseline called ChatMultiOmics with a novel three-stage training pipeline, demonstrating the powerful ability to understand biology by using Biology-Instructions. Biology-Instructions and ChatMultiOmics are publicly available and crucial resources for enabling more effective integration of LLMs with multi-omics sequence analysis.
TAR3D: Creating High-Quality 3D Assets via Next-Part Prediction
Dec 22, 2024



We present TAR3D, a novel framework that consists of a 3D-aware Vector Quantized-Variational AutoEncoder (VQ-VAE) and a Generative Pre-trained Transformer (GPT) to generate high-quality 3D assets. The core insight of this work is to migrate the multimodal unification and promising learning capabilities of the next-token prediction paradigm to conditional 3D object generation. To achieve this, the 3D VQ-VAE first encodes a wide range of 3D shapes into a compact triplane latent space and utilizes a set of discrete representations from a trainable codebook to reconstruct fine-grained geometries under the supervision of query point occupancy. Then, the 3D GPT, equipped with a custom triplane position embedding called TriPE, predicts the codebook index sequence with prefilling prompt tokens in an autoregressive manner so that the composition of 3D geometries can be modeled part by part. Extensive experiments on ShapeNet and Objaverse demonstrate that TAR3D can achieve superior generation quality over existing methods in text-to-3D and image-to-3D tasks
Model Decides How to Tokenize: Adaptive DNA Sequence Tokenization with MxDNA
Dec 18, 2024Foundation models have made significant strides in understanding the genomic language of DNA sequences. However, previous models typically adopt the tokenization methods designed for natural language, which are unsuitable for DNA sequences due to their unique characteristics. In addition, the optimal approach to tokenize DNA remains largely under-explored, and may not be intuitively understood by humans even if discovered. To address these challenges, we introduce MxDNA, a novel framework where the model autonomously learns an effective DNA tokenization strategy through gradient decent. MxDNA employs a sparse Mixture of Convolution Experts coupled with a deformable convolution to model the tokenization process, with the discontinuous, overlapping, and ambiguous nature of meaningful genomic segments explicitly considered. On Nucleotide Transformer Benchmarks and Genomic Benchmarks, MxDNA demonstrates superior performance to existing methods with less pretraining data and time, highlighting its effectiveness. Finally, we show that MxDNA learns unique tokenization strategy distinct to those of previous methods and captures genomic functionalities at a token level during self-supervised pretraining. Our MxDNA aims to provide a new perspective on DNA tokenization, potentially offering broad applications in various domains and yielding profound insights.
COMET: Benchmark for Comprehensive Biological Multi-omics Evaluation Tasks and Language Models
Dec 13, 2024



As key elements within the central dogma, DNA, RNA, and proteins play crucial roles in maintaining life by guaranteeing accurate genetic expression and implementation. Although research on these molecules has profoundly impacted fields like medicine, agriculture, and industry, the diversity of machine learning approaches-from traditional statistical methods to deep learning models and large language models-poses challenges for researchers in choosing the most suitable models for specific tasks, especially for cross-omics and multi-omics tasks due to the lack of comprehensive benchmarks. To address this, we introduce the first comprehensive multi-omics benchmark COMET (Benchmark for Biological COmprehensive Multi-omics Evaluation Tasks and Language Models), designed to evaluate models across single-omics, cross-omics, and multi-omics tasks. First, we curate and develop a diverse collection of downstream tasks and datasets covering key structural and functional aspects in DNA, RNA, and proteins, including tasks that span multiple omics levels. Then, we evaluate existing foundational language models for DNA, RNA, and proteins, as well as the newly proposed multi-omics method, offering valuable insights into their performance in integrating and analyzing data from different biological modalities. This benchmark aims to define critical issues in multi-omics research and guide future directions, ultimately promoting advancements in understanding biological processes through integrated and different omics data analysis.