 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach-to-Reason: Competition-Guided Reasoning with a Self-Improving Teacher
Jun 24, 2026Chest X-ray visual question answering (CXR VQA) requires models not only to predict correct answers, but also to produce reliable medical reasoning. However, existing reinforcement-learning-based training typically relies on answer-level rewards, which are often too coarse to improve chain-of-thought (CoT) quality and can become ineffective when group-level advantages collapse to zero. We propose \textbf{Teach-to-Reason (T2R)}, a framework that introduces comparison-based supervision into CoT optimization through a self-improving \emph{Teacher} and a competition-guided \emph{Reasoner}. As the Teacher is iteratively strengthened via self-competition, the Reasoner is optimized against progressively stronger Teacher-generated references. We further introduce a case-wise reward design that preserves the original reward-induced positive/negative partition when it is informative, and restores supervision from competition scores when the original reward signal degenerates. Experiments on multiple CXR open-ended VQA benchmarks show that T2R consistently outperforms strong baselines, indicating that comparison-based supervision, when integrated in a controlled and principled manner, provides a more effective training signal for reasoning optimization.
ECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion
Apr 10, 2026Chest X-ray report generation (CXR-RG) has the potential to substantially alleviate radiologists' workload. However, conventional autoregressive vision--language models (VLMs) suffer from high inference latency due to sequential token decoding. Diffusion-based models offer a promising alternative through parallel generation, but they still require multiple denoising iterations. Compressing multi-step denoising to a single step could further reduce latency, but often degrades textual coherence due to the mean-field bias introduced by token-factorized denoisers. To address this challenge, we propose \textbf{ECHO}, an efficient diffusion-based VLM (dVLM) for chest X-ray report generation. ECHO enables stable one-step-per-block inference via a novel Direct Conditional Distillation (DCD) framework, which mitigates the mean-field limitation by constructing unfactorized supervision from on-policy diffusion trajectories to encode joint token dependencies. In addition, we introduce a Response-Asymmetric Diffusion (RAD) training strategy that further improves training efficiency while maintaining model effectiveness. Extensive experiments demonstrate that ECHO surpasses state-of-the-art autoregressive methods, improving RaTE and SemScore by \textbf{64.33\%} and \textbf{60.58\%} respectively, while achieving an \textbf{$8\times$} inference speedup without compromising clinical accuracy.
MotionGPT-2: A General-Purpose Motion-Language Model for Motion Generation and Understanding
Oct 29, 2024



Generating lifelike human motions from descriptive texts has experienced remarkable research focus in the recent years, propelled by the emerging requirements of digital humans.Despite impressive advances, existing approaches are often constrained by limited control modalities, task specificity, and focus solely on body motion representations.In this paper, we present MotionGPT-2, a unified Large Motion-Language Model (LMLM) that addresses these limitations. MotionGPT-2 accommodates multiple motion-relevant tasks and supporting multimodal control conditions through pre-trained Large Language Models (LLMs). It quantizes multimodal inputs-such as text and single-frame poses-into discrete, LLM-interpretable tokens, seamlessly integrating them into the LLM's vocabulary. These tokens are then organized into unified prompts, guiding the LLM to generate motion outputs through a pretraining-then-finetuning paradigm. We also show that the proposed MotionGPT-2 is highly adaptable to the challenging 3D holistic motion generation task, enabled by the innovative motion discretization framework, Part-Aware VQVAE, which ensures fine-grained representations of body and hand movements. Extensive experiments and visualizations validate the effectiveness of our method, demonstrating the adaptability of MotionGPT-2 across motion generation, motion captioning, and generalized motion completion tasks.
Holistic-Motion2D: Scalable Whole-body Human Motion Generation in 2D Space
Jun 17, 2024



In this paper, we introduce a novel path to $\textit{general}$ human motion generation by focusing on 2D space. Traditional methods have primarily generated human motions in 3D, which, while detailed and realistic, are often limited by the scope of available 3D motion data in terms of both the size and the diversity. To address these limitations, we exploit extensive availability of 2D motion data. We present $\textbf{Holistic-Motion2D}$, the first comprehensive and large-scale benchmark for 2D whole-body motion generation, which includes over 1M in-the-wild motion sequences, each paired with high-quality whole-body/partial pose annotations and textual descriptions. Notably, Holistic-Motion2D is ten times larger than the previously largest 3D motion dataset. We also introduce a baseline method, featuring innovative $\textit{whole-body part-aware attention}$ and $\textit{confidence-aware modeling}$ techniques, tailored for 2D $\underline{\text T}$ext-driv$\underline{\text{EN}}$ whole-bo$\underline{\text D}$y motion gen$\underline{\text{ER}}$ation, namely $\textbf{Tender}$. Extensive experiments demonstrate the effectiveness of $\textbf{Holistic-Motion2D}$ and $\textbf{Tender}$ in generating expressive, diverse, and realistic human motions. We also highlight the utility of 2D motion for various downstream applications and its potential for lifting to 3D motion. The page link is: https://holistic-motion2d.github.io.
Dual-Tuning: Joint Prototype Transfer and Structure Regularization for Compatible Feature Learning
Aug 06, 2021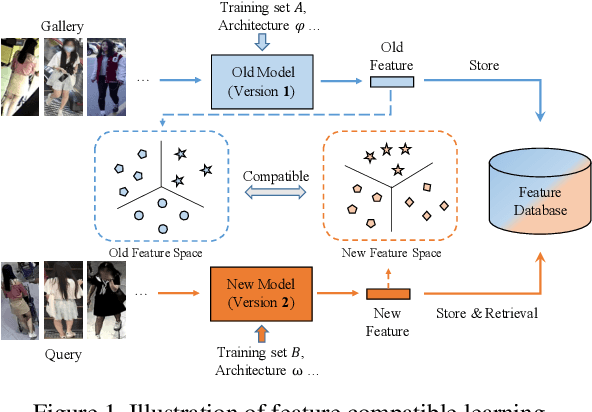
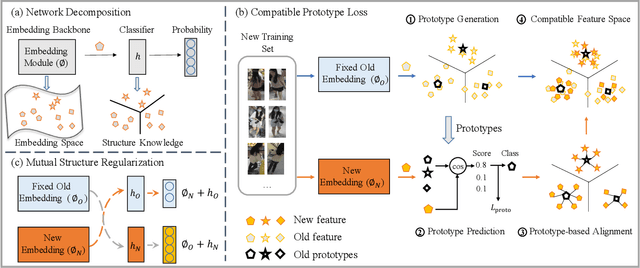
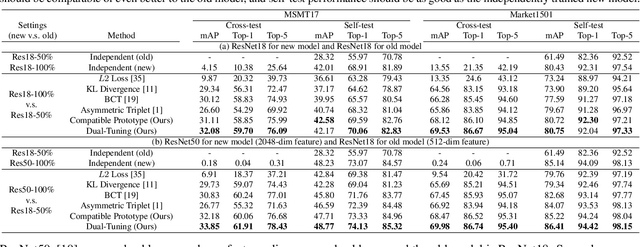
Visual retrieval system faces frequent model update and deployment. It is a heavy workload to re-extract features of the whole database every time.Feature compatibility enables the learned new visual features to be directly compared with the old features stored in the database. In this way, when updating the deployed model, we can bypass the inflexible and time-consuming feature re-extraction process. However, the old feature space that needs to be compatible is not ideal and faces the distribution discrepancy problem with the new space caused by different supervision losses. In this work, we propose a global optimization Dual-Tuning method to obtain feature compatibility against different networks and losses. A feature-level prototype loss is proposed to explicitly align two types of embedding features, by transferring global prototype information. Furthermore, we design a component-level mutual structural regularization to implicitly optimize the feature intrinsic structure. Experimental results on million-scale datasets demonstrate that our Dual-Tuning is able to obtain feature compatibility without sacrificing performance. (Our code will be avaliable at https://github.com/yanbai1993/Dual-Tuning)