 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIS Data-Driven Maritime Monitoring Based on Transformer: A Comprehensive Review
May 12, 2025



With the increasing demands for safety, efficiency, and sustainability in global shipping, Automatic Identification System (AIS) data plays an increasingly important role in maritime monitoring. AIS data contains spatial-temporal variation patterns of vessels that hold significant research value in the marine domain. However, due to its massive scale, the full potential of AIS data has long remained untapped. With its powerful sequence modeling capabilities, particularly its ability to capture long-range dependencies and complex temporal dynamics, the Transformer model has emerged as an effective tool for processing AIS data. Therefore, this paper reviews the research on Transformer-based AIS data-driven maritime monitoring, providing a comprehensive overview of the current applications of Transformer models in the marine field. The focus is on Transformer-based trajectory prediction methods, behavior detection, and prediction techniques. Additionally, this paper collects and organizes publicly available AIS datasets from the reviewed papers, performing data filtering, cleaning, and statistical analysis. The statistical results reveal the operational characteristics of different vessel types, providing data support for further research on maritime monitoring tasks. Finally, we offer valuable suggestions for future research, identifying two promising research directions. Datasets are available at https://github.com/eyesofworld/Maritime-Monitoring.
Towards Ultra-High-Definition Image Deraining: A Benchmark and An Efficient Method
May 27, 2024



Despite significant progress has been made in image deraining, existing approaches are mostly carried out on low-resolution images. The effectiveness of these methods on high-resolution images is still unknown, especially for ultra-high-definition (UHD) images, given the continuous advancement of imaging devices. In this paper, we focus on the task of UHD image deraining, and contribute the first large-scale UHD image deraining dataset, 4K-Rain13k, that contains 13,000 image pairs at 4K resolution. Based on this dataset, we conduct a benchmark study on existing methods for processing UHD images. Furthermore, we develop an effective and efficient vision MLP-based architecture (UDR-Mixer) to better solve this task. Specifically, our method contains two building components: a spatial feature rearrangement layer that captures long-range information of UHD images, and a frequency feature modulation layer that facilitates high-quality UHD image reconstruction. Extensive experimental results demonstrate that our method performs favorably against the state-of-the-art approaches while maintaining a lower model complexity. The code and dataset will be available at https://github.com/cschenxiang/UDR-Mixer.
Manifold-based Incomplete Multi-view Clustering via Bi-Consistency Guidance
May 16, 2024



Incomplete multi-view clustering primarily focuses on dividing unlabeled data into corresponding categories with missing instances, and has received intensive attention due to its superiority in real applications. Considering the influence of incomplete data, the existing methods mostly attempt to recover data by adding extra terms. However, for the unsupervised methods, a simple recovery strategy will cause errors and outlying value accumulations, which will affect the performance of the methods. Broadly, the previous methods have not taken the effectiveness of recovered instances into consideration, or cannot flexibly balance the discrepancies between recovered data and original data. To address these problems, we propose a novel method termed Manifold-based Incomplete Multi-view clustering via Bi-consistency guidance (MIMB), which flexibly recovers incomplete data among various views, and attempts to achieve biconsistency guidance via reverse regularization. In particular, MIMB adds reconstruction terms to representation learning by recovering missing instances, which dynamically examines the latent consensus representation. Moreover, to preserve the consistency information among multiple views, MIMB implements a biconsistency guidance strategy with reverse regularization of the consensus representation and proposes a manifold embedding measure for exploring the hidden structure of the recovered data. Notably, MIMB aims to balance the importance of different views, and introduces an adaptive weight term for each view. Finally, an optimization algorithm with an alternating iteration optimization strategy is designed for final clustering. Extensive experimental results on 6 benchmark datasets are provided to confirm that MIMB can significantly obtain superior results as compared with several state-of-the-art baselines.
Scene-Adaptive Person Search via Bilateral Modulations
May 05, 2024



Person search aims to localize specific a target person from a gallery set of images with various scenes. As the scene of moving pedestrian changes, the captured person image inevitably bring in lots of background noise and foreground noise on the person feature, which are completely unrelated to the person identity, leading to severe performance degeneration. To address this issue, we present a Scene-Adaptive Person Search (SEAS) model by introducing bilateral modulations to simultaneously eliminate scene noise and maintain a consistent person representation to adapt to various scenes. In SEAS, a Background Modulation Network (BMN) is designed to encode the feature extracted from the detected bounding box into a multi-granularity embedding, which reduces the input of background noise from multiple levels with norm-aware. Additionally, to mitigate the effect of foreground noise on the person feature, SEAS introduces a Foreground Modulation Network (FMN) to compute the clutter reduction offset for the person embedding based on the feature map of the scene image. By bilateral modulations on both background and foreground within an end-to-end manner, SEAS obtains consistent feature representations without scene noise. SEAS can achieve state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU with 97.1\% mAP and PRW with 60.5\% mAP. The code is available at https://github.com/whbdmu/SEAS.
Fast One-Stage Unsupervised Domain Adaptive Person Search
May 05, 2024



Unsupervised person search aims to localize a particular target person from a gallery set of scene images without annotations, which is extremely challenging due to the unexpected variations of the unlabeled domains. However, most existing methods dedicate to developing multi-stage models to adapt domain variations while using clustering for iterative model training, which inevitably increases model complexity. To address this issue, we propose a Fast One-stage Unsupervised person Search (FOUS) which complementary integrates domain adaptaion with label adaptaion within an end-to-end manner without iterative clustering. To minimize the domain discrepancy, FOUS introduced an Attention-based Domain Alignment Module (ADAM) which can not only align various domains for both detection and ReID tasks but also construct an attention mechanism to reduce the adverse impacts of low-quality candidates resulting from unsupervised detection. Moreover, to avoid the redundant iterative clustering mode, FOUS adopts a prototype-guided labeling method which minimizes redundant correlation computations for partial samples and assigns noisy coarse label groups efficiently. The coarse label groups will be continuously refined via label-flexible training network with an adaptive selection strategy. With the adapted domains and labels, FOUS can achieve the state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU and PRW. The code is available at https://github.com/whbdmu/FOUS.
IA2U: A Transfer Plugin with Multi-Prior for In-Air Model to Underwater
Dec 12, 2023



In underwater environments, variations in suspended particle concentration and turbidity cause severe image degradation, posing significant challenges to image enhancement (IE) and object detection (OD) tasks. Currently, in-air image enhancement and detection methods have made notable progress, but their application in underwater conditions is limited due to the complexity and variability of these environments. Fine-tuning in-air models saves high overhead and has more optional reference work than building an underwater model from scratch. To address these issues, we design a transfer plugin with multiple priors for converting in-air models to underwater applications, named IA2U. IA2U enables efficient application in underwater scenarios, thereby improving performance in Underwater IE and OD. IA2U integrates three types of underwater priors: the water type prior that characterizes the degree of image degradation, such as color and visibility; the degradation prior, focusing on differences in details and textures; and the sample prior, considering the environmental conditions at the time of capture and the characteristics of the photographed object. Utilizing a Transformer-like structure, IA2U employs these priors as query conditions and a joint task loss function to achieve hierarchical enhancement of task-level underwater image features, therefore considering the requirements of two different tasks, IE and OD. Experimental results show that IA2U combined with an in-air model can achieve superior performance in underwater image enhancement and object detection tasks. The code will be made publicly available.
WaterHE-NeRF: Water-ray Tracing Neural Radiance Fields for Underwater Scene Reconstruction
Dec 12, 2023



Neural Radiance Field (NeRF) technology demonstrates immense potential in novel viewpoint synthesis tasks, due to its physics-based volumetric rendering process, which is particularly promising in underwater scenes. Addressing the limitations of existing underwater NeRF methods in handling light attenuation caused by the water medium and the lack of real Ground Truth (GT) supervision, this study proposes WaterHE-NeRF. We develop a new water-ray tracing field by Retinex theory that precisely encodes color, density, and illuminance attenuation in three-dimensional space. WaterHE-NeRF, through its illuminance attenuation mechanism, generates both degraded and clear multi-view images and optimizes image restoration by combining reconstruction loss with Wasserstein distance. Additionally, the use of histogram equalization (HE) as pseudo-GT enhances the network's accuracy in preserving original details and color distribution. Extensive experiments on real underwater datasets and synthetic datasets validate the effectiveness of WaterHE-NeRF. Our code will be made publicly available.
DGNet: Dynamic Gradient-guided Network with Noise Suppression for Underwater Image Enhancement
Dec 12, 2023Underwater image enhancement (UIE) is a challenging task due to the complex degradation caused by underwater environments. To solve this issue, previous methods often idealize the degradation process, and neglect the impact of medium noise and object motion on the distribution of image features, limiting the generalization and adaptability of the model. Previous methods use the reference gradient that is constructed from original images and synthetic ground-truth images. This may cause the network performance to be influenced by some low-quality training data. Our approach utilizes predicted images to dynamically update pseudo-labels, adding a dynamic gradient to optimize the network's gradient space. This process improves image quality and avoids local optima. Moreover, we propose a Feature Restoration and Reconstruction module (FRR) based on a Channel Combination Inference (CCI) strategy and a Frequency Domain Smoothing module (FRS). These modules decouple other degradation features while reducing the impact of various types of noise on network performance. Experiments on multiple public datasets demonstrate the superiority of our method over existing state-of-the-art approaches, especially in achieving performance milestones: PSNR of 25.6dB and SSIM of 0.93 on the UIEB dataset. Its efficiency in terms of parameter size and inference time further attests to its broad practicality. The code will be made publicly available.
Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering
Jan 06, 2023Unsupervised hashing methods have attracted widespread attention with the explosive growth of large-scale data, which can greatly reduce storage and computation by learning compact binary codes. Existing unsupervised hashing methods attempt to exploit the valuable information from samples, which fails to take the local geometric structure of unlabeled samples into consideration. Moreover, hashing based on auto-encoders aims to minimize the reconstruction loss between the input data and binary codes, which ignores the potential consistency and complementarity of multiple sources data. To address the above issues, we propose a hashing algorithm based on auto-encoders for multi-view binary clustering, which dynamically learns affinity graphs with low-rank constraints and adopts collaboratively learning between auto-encoders and affinity graphs to learn a unified binary code, called Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering (GCAE). Specifically, we propose a multi-view affinity graphs learning model with low-rank constraint, which can mine the underlying geometric information from multi-view data. Then, we design an encoder-decoder paradigm to collaborate the multiple affinity graphs, which can learn a unified binary code effectively. Notably, we impose the decorrelation and code balance constraints on binary codes to reduce the quantization errors. Finally, we utilize an alternating iterative optimization scheme to obtain the multi-view clustering results. Extensive experimental results on $5$ public datasets are provided to reveal the effectiveness of the algorithm and its superior performance over other state-of-the-art alternatives.
Unsupervised Vehicle Re-identification with Progressive Adaptation
Jun 20, 2020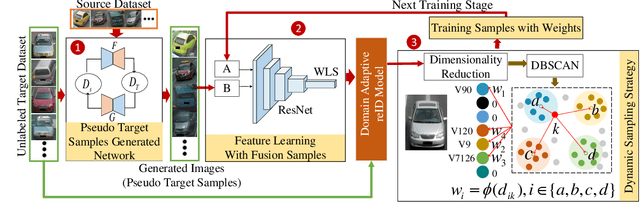
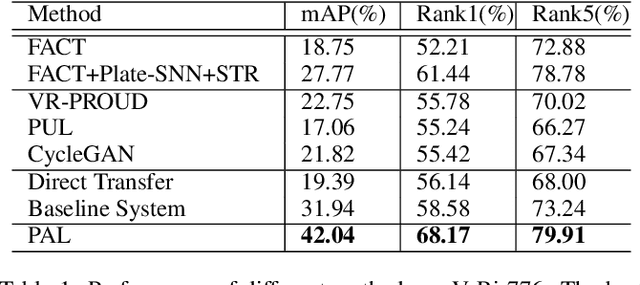
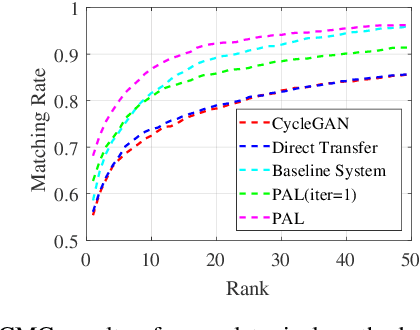

Vehicle re-identification (reID) aims at identifying vehicles across different non-overlapping cameras views. The existing methods heavily relied on well-labeled datasets for ideal performance, which inevitably causes fateful drop due to the severe domain bias between the training domain and the real-world scenes; worse still, these approaches required full annotations, which is labor-consuming. To tackle these challenges, we propose a novel progressive adaptation learning method for vehicle reID, named PAL, which infers from the abundant data without annotations. For PAL, a data adaptation module is employed for source domain, which generates the images with similar data distribution to unlabeled target domain as ``pseudo target samples''. These pseudo samples are combined with the unlabeled samples that are selected by a dynamic sampling strategy to make training faster. We further proposed a weighted label smoothing (WLS) loss, which considers the similarity between samples with different clusters to balance the confidence of pseudo labels. Comprehensive experimental results validate the advantages of PAL on both VehicleID and VeRi-776 dataset.