 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Camera View Scaling for Data-Efficient Robot Imitation Learning
Apr 01, 2026The generalization ability of imitation learning policies for robotic manipulation is fundamentally constrained by the diversity of expert demonstrations, while collecting demonstrations across varied environments is costly and difficult in practice. In this paper, we propose a practical framework that exploits inherent scene diversity without additional human effort by scaling camera views during demonstration collection. Instead of acquiring more trajectories, multiple synchronized camera perspectives are used to generate pseudo-demonstrations from each expert trajectory, which enriches the training distribution and improves viewpoint invariance in visual representations. We analyze how different action spaces interact with view scaling and show that camera-space representations further enhance diversity. In addition, we introduce a multiview action aggregation method that allows single-view policies to benefit from multiple cameras during deployment. Extensive experiments in simulation and real-world manipulation tasks demonstrate significant gains in data efficiency and generalization compared to single-view baselines. Our results suggest that scaling camera views provides a practical and scalable solution for imitation learning, which requires minimal additional hardware setup and integrates seamlessly with existing imitation learning algorithms. The website of our project is https://yichen928.github.io/robot_multiview.
Scaling Up Audio-Synchronized Visual Animation: An Efficient Training Paradigm
Aug 05, 2025Recent advances in audio-synchronized visual animation enable control of video content using audios from specific classes. However, existing methods rely heavily on expensive manual curation of high-quality, class-specific training videos, posing challenges to scaling up to diverse audio-video classes in the open world. In this work, we propose an efficient two-stage training paradigm to scale up audio-synchronized visual animation using abundant but noisy videos. In stage one, we automatically curate large-scale videos for pretraining, allowing the model to learn diverse but imperfect audio-video alignments. In stage two, we finetune the model on manually curated high-quality examples, but only at a small scale, significantly reducing the required human effort. We further enhance synchronization by allowing each frame to access rich audio context via multi-feature conditioning and window attention. To efficiently train the model, we leverage pretrained text-to-video generator and audio encoders, introducing only 1.9\% additional trainable parameters to learn audio-conditioning capability without compromising the generator's prior knowledge. For evaluation, we introduce AVSync48, a benchmark with videos from 48 classes, which is 3$\times$ more diverse than previous benchmarks. Extensive experiments show that our method significantly reduces reliance on manual curation by over 10$\times$, while generalizing to many open classes.
From Prototypes to General Distributions: An Efficient Curriculum for Masked Image Modeling
Nov 16, 2024Masked Image Modeling (MIM) has emerged as a powerful self-supervised learning paradigm for visual representation learning, enabling models to acquire rich visual representations by predicting masked portions of images from their visible regions. While this approach has shown promising results, we hypothesize that its effectiveness may be limited by optimization challenges during early training stages, where models are expected to learn complex image distributions from partial observations before developing basic visual processing capabilities. To address this limitation, we propose a prototype-driven curriculum leagrning framework that structures the learning process to progress from prototypical examples to more complex variations in the dataset. Our approach introduces a temperature-based annealing scheme that gradually expands the training distribution, enabling more stable and efficient learning trajectories. Through extensive experiments on ImageNet-1K, we demonstrate that our curriculum learning strategy significantly improves both training efficiency and representation quality while requiring substantially fewer training epochs compared to standard Masked Auto-Encoding. Our findings suggest that carefully controlling the order of training examples plays a crucial role in self-supervised visual learning, providing a practical solution to the early-stage optimization challenges in MIM.
Accelerating Augmentation Invariance Pretraining
Oct 31, 2024



Our work tackles the computational challenges of contrastive learning methods, particularly for the pretraining of Vision Transformers (ViTs). Despite the effectiveness of contrastive learning, the substantial computational resources required for training often hinder their practical application. To mitigate this issue, we propose an acceleration framework, leveraging ViT's unique ability to generalize across inputs of varying sequence lengths. Our method employs a mix of sequence compression strategies, including randomized token dropout and flexible patch scaling, to reduce the cost of gradient estimation and accelerate convergence. We further provide an in-depth analysis of the gradient estimation error of various acceleration strategies as well as their impact on downstream tasks, offering valuable insights into the trade-offs between acceleration and performance. We also propose a novel procedure to identify an optimal acceleration schedule to adjust the sequence compression ratios to the training progress, ensuring efficient training without sacrificing downstream performance. Our approach significantly reduces computational overhead across various self-supervised learning algorithms on large-scale datasets. In ImageNet, our method achieves speedups of 4$\times$ in MoCo, 3.3$\times$ in SimCLR, and 2.5$\times$ in DINO, demonstrating substantial efficiency gains.
Patch Ranking: Efficient CLIP by Learning to Rank Local Patches
Sep 22, 2024Contrastive image-text pre-trained models such as CLIP have shown remarkable adaptability to downstream tasks. However, they face challenges due to the high computational requirements of the Vision Transformer (ViT) backbone. Current strategies to boost ViT efficiency focus on pruning patch tokens but fall short in addressing the multimodal nature of CLIP and identifying the optimal subset of tokens for maximum performance. To address this, we propose greedy search methods to establish a "Golden Ranking" and introduce a lightweight predictor specifically trained to approximate this Ranking. To compensate for any performance degradation resulting from token pruning, we incorporate learnable visual tokens that aid in restoring and potentially enhancing the model's performance. Our work presents a comprehensive and systematic investigation of pruning tokens within the ViT backbone of CLIP models. Through our framework, we successfully reduced 40% of patch tokens in CLIP's ViT while only suffering a minimal average accuracy loss of 0.3 across seven datasets. Our study lays the groundwork for building more computationally efficient multimodal models without sacrificing their performance, addressing a key challenge in the application of advanced vision-language models.
Block Pruning for Enhanced Efficiency in Convolutional Neural Networks
Jan 14, 2024This paper presents a novel approach to network pruning, targeting block pruning in deep neural networks for edge computing environments. Our method diverges from traditional techniques that utilize proxy metrics, instead employing a direct block removal strategy to assess the impact on classification accuracy. This hands-on approach allows for an accurate evaluation of each block's importance. We conducted extensive experiments on CIFAR-10, CIFAR-100, and ImageNet datasets using ResNet architectures. Our results demonstrate the efficacy of our method, particularly on large-scale datasets like ImageNet with ResNet50, where it excelled in reducing model size while retaining high accuracy, even when pruning a significant portion of the network. The findings underscore our method's capability in maintaining an optimal balance between model size and performance, especially in resource-constrained edge computing scenarios.
Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
Jul 22, 2023



Vision-language models such as CLIP learn a generic text-image embedding from large-scale training data. A vision-language model can be adapted to a new classification task through few-shot prompt tuning. We find that such a prompt tuning process is highly robust to label noises. This intrigues us to study the key reasons contributing to the robustness of the prompt tuning paradigm. We conducted extensive experiments to explore this property and find the key factors are: 1) the fixed classname tokens provide a strong regularization to the optimization of the model, reducing gradients induced by the noisy samples; 2) the powerful pre-trained image-text embedding that is learned from diverse and generic web data provides strong prior knowledge for image classification. Further, we demonstrate that noisy zero-shot predictions from CLIP can be used to tune its own prompt, significantly enhancing prediction accuracy in the unsupervised setting. The code is available at https://github.com/CEWu/PTNL.
Self-supervised Video Representation Learning with Cascade Positive Retrieval
Jan 21, 2022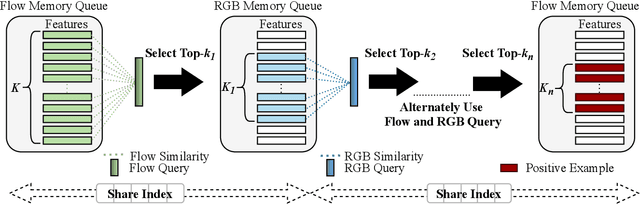
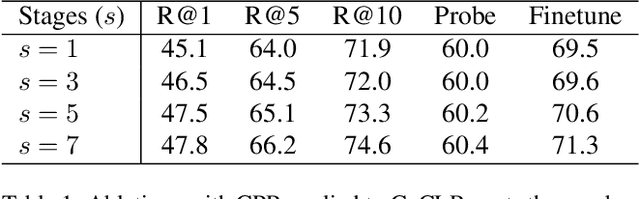

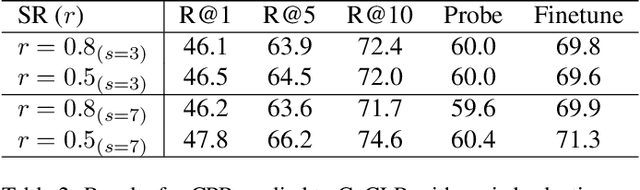
Self-supervised video representation learning has been shown to effectively improve downstream tasks such as video retrieval and action recognition. In this paper, we present the Cascade Positive Retrieval (CPR) that successively mines positive examples w.r.t. the query for contrastive learning in a cascade of stages. Specifically, CPR exploits multiple views of a query example in different modalities, where an alternative view may help find another positive example dissimilar in the query view. We explore the effects of possible CPR configurations in ablations including the number of mining stages, the top similar example selection ratio in each stage, and progressive training with an incremental number of the final Top-k selection. The overall mining quality is measured to reflect the recall across training set classes. CPR reaches a median class mining recall of 83.3%, outperforming previous work by 5.5%. Implementation-wise, CPR is complementary to pretext tasks and can be easily applied to previous work. In the evaluation of pretraining on UCF101, CPR consistently improves existing work and even achieves state-of-the-art R@1 of 56.7% and 24.4% in video retrieval as well as 83.8% and 54.8% in action recognition on UCF101 and HMDB51. For transfer from large video dataset Kinetics400 to UCF101 and HDMB, CPR benefits existing work, showing competitive Top-1 accuracies of 85.1% and 57.4% despite pretraining at a lower resolution and frame sampling rate. The code will be released soon for reproducing the results. The code is available at https://github.com/necla-ml/CPR.
Compacting, Picking and Growing for Unforgetting Continual Learning
Oct 30, 2019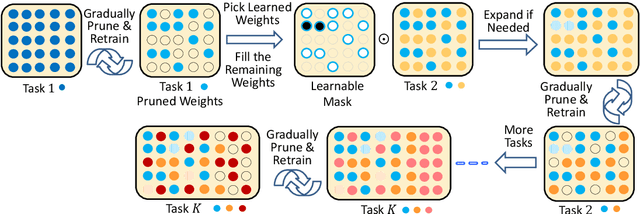

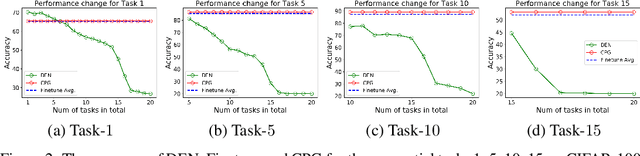
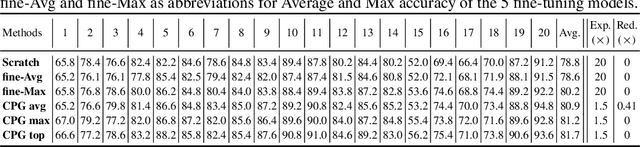
Continual lifelong learning is essential to many applications. In this paper, we propose a simple but effective approach to continual deep learning. Our approach leverages the principles of deep model compression, critical weights selection, and progressive networks expansion. By enforcing their integration in an iterative manner, we introduce an incremental learning method that is scalable to the number of sequential tasks in a continual learning process. Our approach is easy to implement and owns several favorable characteristics. First, it can avoid forgetting (i.e., learn new tasks while remembering all previous tasks). Second, it allows model expansion but can maintain the model compactness when handling sequential tasks. Besides, through our compaction and selection/expansion mechanism, we show that the knowledge accumulated through learning previous tasks is helpful to build a better model for the new tasks compared to training the models independently with tasks. Experimental results show that our approach can incrementally learn a deep model tackling multiple tasks without forgetting, while the model compactness is maintained with the performance more satisfiable than individual task training.
IMMVP: An Efficient Daytime and Nighttime On-Road Object Detector
Oct 28, 2019

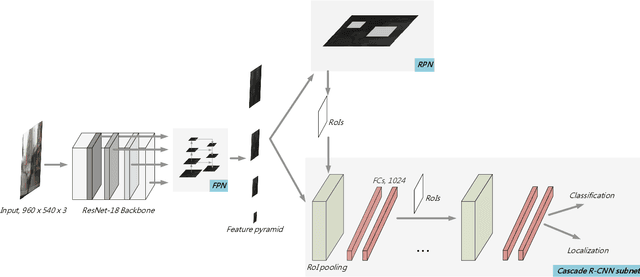

It is hard to detect on-road objects under various lighting conditions. To improve the quality of the classifier, three techniques are used. We define subclasses to separate daytime and nighttime samples. Then we skip similar samples in the training set to prevent overfitting. With the help of the outside training samples, the detection accuracy is also improved. To detect objects in an edge device, Nvidia Jetson TX2 platform, we exert the lightweight model ResNet-18 FPN as the backbone feature extractor. The FPN (Feature Pyramid Network) generates good features for detecting objects over various scales. With Cascade R-CNN technique, the bounding boxes are iteratively refined for better results.