 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Formally Verifiable Step-by-Step Logic Reasoning via Structured Formal Intermediaries
Mar 31, 2026Large language models (LLMs) have recently demonstrated impressive performance on complex, multi-step reasoning tasks, especially when post-trained with outcome-rewarded reinforcement learning Guo et al. 2025. However, it has been observed that outcome rewards often overlook flawed intermediate steps, leading to unreliable reasoning steps even when final answers are correct. To address this unreliable reasoning, we propose PRoSFI (Process Reward over Structured Formal Intermediates), a novel reward method that enhances reasoning reliability without compromising accuracy. Instead of generating formal proofs directly, which is rarely accomplishable for a modest-sized (7B) model, the model outputs structured intermediate steps aligned with its natural language reasoning. Each step is then verified by a formal prover. Only fully validated reasoning chains receive high rewards. The integration of formal verification guides the model towards generating step-by-step machine-checkable proofs, thereby yielding more credible final answers. PRoSFI offers a simple and effective approach to training trustworthy reasoning models.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
AdamS: Momentum Itself Can Be A Normalizer for LLM Pretraining and Post-training
May 22, 2025We introduce AdamS, a simple yet effective alternative to Adam for large language model (LLM) pretraining and post-training. By leveraging a novel denominator, i.e., the root of weighted sum of squares of the momentum and the current gradient, AdamS eliminates the need for second-moment estimates. Hence, AdamS is efficient, matching the memory and compute footprint of SGD with momentum while delivering superior optimization performance. Moreover, AdamS is easy to adopt: it can directly inherit hyperparameters of AdamW, and is entirely model-agnostic, integrating seamlessly into existing pipelines without modifications to optimizer APIs or architectures. The motivation behind AdamS stems from the observed $(L_0, L_1)$ smoothness properties in transformer objectives, where local smoothness is governed by gradient magnitudes that can be further approximated by momentum magnitudes. We establish rigorous theoretical convergence guarantees and provide practical guidelines for hyperparameter selection. Empirically, AdamS demonstrates strong performance in various tasks, including pre-training runs on GPT-2 and Llama2 (up to 13B parameters) and reinforcement learning in post-training regimes. With its efficiency, simplicity, and theoretical grounding, AdamS stands as a compelling alternative to existing optimizers.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022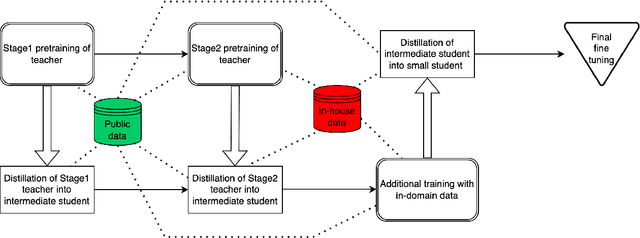
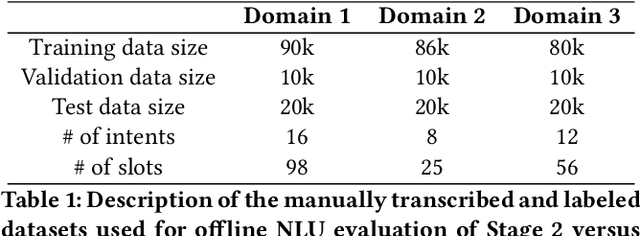
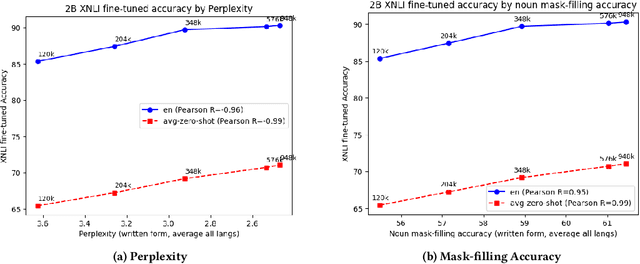
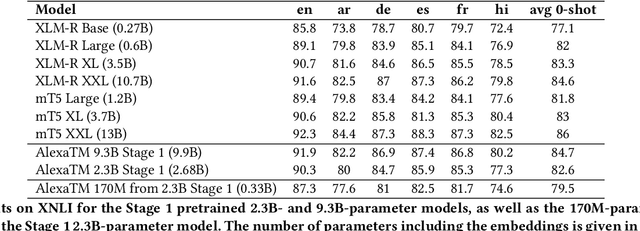
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Industry Scale Semi-Supervised Learning for Natural Language Understanding
Mar 29, 2021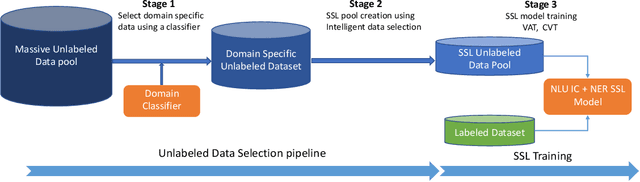

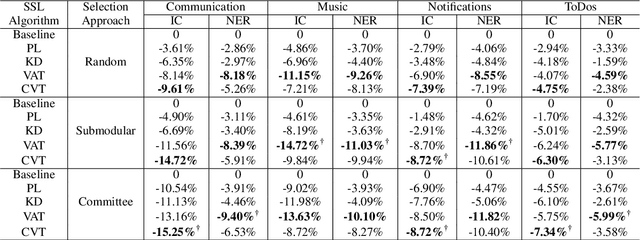
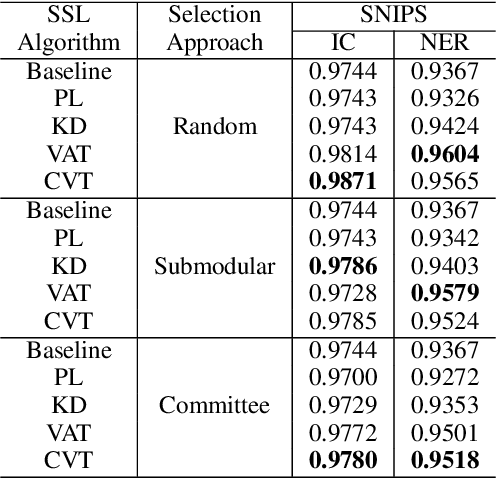
This paper presents a production Semi-Supervised Learning (SSL) pipeline based on the student-teacher framework, which leverages millions of unlabeled examples to improve Natural Language Understanding (NLU) tasks. We investigate two questions related to the use of unlabeled data in production SSL context: 1) how to select samples from a huge unlabeled data pool that are beneficial for SSL training, and 2) how do the selected data affect the performance of different state-of-the-art SSL techniques. We compare four widely used SSL techniques, Pseudo-Label (PL), Knowledge Distillation (KD), Virtual Adversarial Training (VAT) and Cross-View Training (CVT) in conjunction with two data selection methods including committee-based selection and submodular optimization based selection. We further examine the benefits and drawbacks of these techniques when applied to intent classification (IC) and named entity recognition (NER) tasks, and provide guidelines specifying when each of these methods might be beneficial to improve large scale NLU systems.