 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow RL Unlocks the Aha Moment in Geometric Interleaved Reasoning
Mar 01, 2026Solving complex geometric problems inherently requires interleaved reasoning: a tight alternation between constructing diagrams and performing logical deductions. Although recent Multimodal Large Language Models (MLLMs) have demonstrated strong capabilities in visual generation and plotting, we identify a counter-intuitive and underexplored phenomenon. Naively applying Supervised Fine-Tuning (SFT) on interleaved plot-solution data leads to a substantial degradation in reasoning performance compared to text-only baselines. We argue that this failure stems from a fundamental limitation of SFT, which primarily induces distributional alignment: the model learns to reproduce the surface format of interleaved plotting but fails to internalize the causal dependency between the generated plot and reasoning steps. To overcome this limitation, we propose Faire (Functional alignment for interleaved reasoning), a reinforcement learning framework that enforces three casual constraints to move beyond superficial imitation toward functional alignment. Extensive experiments show that Faire induces a qualitative shift in model behavior in which the plotting is effectively internalized, yielding competitive performance on challenging geometric reasoning benchmarks.
Thinking with Drafting: Optical Decompression via Logical Reconstruction
Feb 12, 2026Existing multimodal large language models have achieved high-fidelity visual perception and exploratory visual generation. However, a precision paradox persists in complex reasoning tasks: optical perception systems transcribe symbols without capturing logical topology, while pixel-based generative models produce visual artifacts lacking mathematical exactness. To bridge this gap, we propose that reasoning over visual inputs be reconceptualized as optical decompression-the process of reconstructing latent logical structures from compressed visual tokens. Guided by the axiom that Parsing is Reasoning, we introduce Thinking with Drafting (TwD), which utilizes a minimalist Domain-Specific Language (DSL) as a grounding intermediate representation. Unlike standard approaches that hallucinate answers directly, TwD forces the model to draft its mental model into executable code, rendering deterministic visual proofs for self-verification. To validate this, we present VisAlg, a visual algebra benchmark. Experiments demonstrate that TwD serve as a superior cognitive scaffold. Our work establishes a closed-loop system where visual generation acts not as a creative output but as a logical verifier, offering a generalizable path for visual reasoning.
Canvas-of-Thought: Grounding Reasoning via Mutable Structured States
Feb 11, 2026While Chain-of-Thought (CoT) prompting has significantly advanced the reasoning capabilities of Multimodal Large Language Models (MLLMs), relying solely on linear text sequences remains a bottleneck for complex tasks. We observe that even when auxiliary visual elements are interleaved, they are often treated as static snapshots within a one-dimensional, unstructured reasoning chain. We argue that such approaches treat reasoning history as an immutable stream: correcting a local error necessitates either generating verbose downstream corrections or regenerating the entire context. This forces the model to implicitly maintain and track state updates, significantly increasing token consumption and cognitive load. This limitation is particularly acute in high-dimensional domains, such as geometry and SVG design, where the textual expression of CoT lacks explicit visual guidance, further constraining the model's reasoning precision. To bridge this gap, we introduce \textbf{Canvas-of-Thought (Canvas-CoT)}. By leveraging a HTML Canvas as an external reasoning substrate, Canvas-CoT empowers the model to perform atomic, DOM-based CRUD operations. This architecture enables in-place state revisions without disrupting the surrounding context, allowing the model to explicitly maintain the "ground truth". Furthermore, we integrate a rendering-based critique loop that serves as a hard constraint validator, providing explicit visual feedback to resolve complex tasks that are difficult to articulate through text alone. Extensive experiments on VCode, RBench-V, and MathVista demonstrate that Canvas-CoT significantly outperforms existing baselines, establishing a new paradigm for context-efficient multimodal reasoning.
Guided Verifier: Collaborative Multimodal Reasoning via Dynamic Process Supervision
Feb 04, 2026Reinforcement Learning (RL) has emerged as a pivotal mechanism for enhancing the complex reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevailing paradigms typically rely on solitary rollout strategies where the model works alone. This lack of intermediate oversight renders the reasoning process susceptible to error propagation, where early logical deviations cascade into irreversible failures, resulting in noisy optimization signals. In this paper, we propose the \textbf{Guided Verifier} framework to address these structural limitations. Moving beyond passive terminal rewards, we introduce a dynamic verifier that actively co-solves tasks alongside the policy. During the rollout phase, this verifier interacts with the policy model in real-time, detecting inconsistencies and providing directional signals to steer the model toward valid trajectories. To facilitate this, we develop a specialized data synthesis pipeline targeting multimodal hallucinations, constructing \textbf{CoRe} dataset of process-level negatives and \textbf{Co}rrect-guide \textbf{Re}asoning trajectories to train the guided verifier. Extensive experiments on MathVista, MathVerse and MMMU indicate that by allocating compute to collaborative inference and dynamic verification, an 8B-parameter model can achieve strong performance.
StructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025



Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
CMSN: Continuous Multi-stage Network and Variable Margin Cosine Loss for Temporal Action Proposal Generation
Nov 20, 2019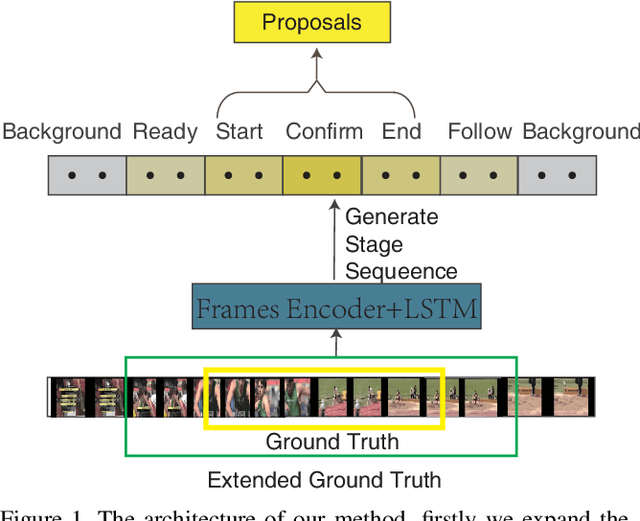
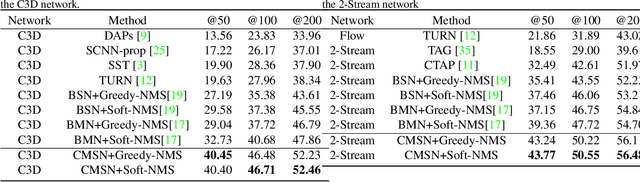
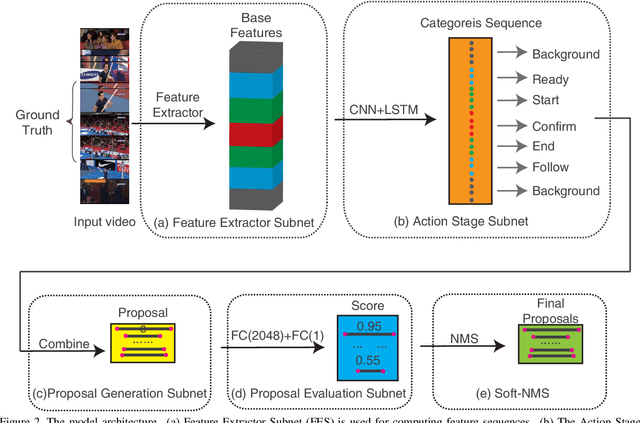
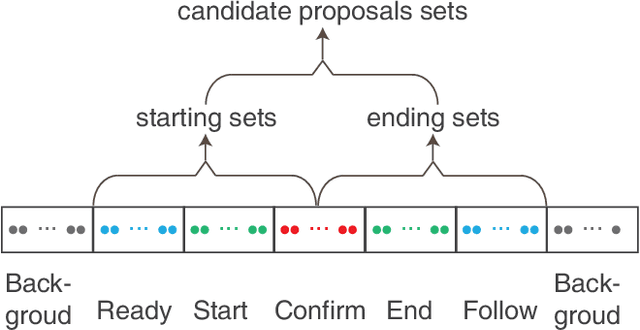
Accurately locating the start and end time of an action in untrimmed videos is a challenging task. One of the important reasons is the boundary of action is not highly distinguishable, and the features around the boundary are difficult to discriminate. To address this problem, we propose a novel framework for temporal action proposal generation, namely Continuous Multi-stage Network (CMSN), which divides a video that contains a complete action instance into six stages, namely Backgroud, Ready, Start, Confirm, End, Follow. To distinguish between Ready and Start, End and Follow more accurately, we propose a novel loss function, Variable Margin Cosine Loss (VMCL), which allows for different margins between different categories. Our experiments on THUMOS14 show that the proposed method for temporal proposal generation performs better than the state-of-the-art methods using the same network architecture and training dataset.