 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
IdentifyMe: A Challenging Long-Context Mention Resolution Benchmark
Nov 12, 2024



Recent evaluations of LLMs on coreference resolution have revealed that traditional output formats and evaluation metrics do not fully capture the models' referential understanding. To address this, we introduce IdentifyMe, a new benchmark for mention resolution presented in a multiple-choice question (MCQ) format, commonly used for evaluating LLMs. IdentifyMe features long narratives and employs heuristics to exclude easily identifiable mentions, creating a more challenging task. The benchmark also consists of a curated mixture of different mention types and corresponding entities, allowing for a fine-grained analysis of model performance. We evaluate both closed- and open source LLMs on IdentifyMe and observe a significant performance gap (20-30%) between the state-of-the-art sub-10B open models vs. closed ones. We observe that pronominal mentions, which have limited surface information, are typically much harder for models to resolve than nominal mentions. Additionally, we find that LLMs often confuse entities when their mentions overlap in nested structures. The highest-scoring model, GPT-4o, achieves 81.9% accuracy, highlighting the strong referential capabilities of state-of-the-art LLMs while also indicating room for further improvement.
OpenMathInstruct-2: Accelerating AI for Math with Massive Open-Source Instruction Data
Oct 02, 2024Mathematical reasoning continues to be a critical challenge in large language model (LLM) development with significant interest. However, most of the cutting-edge progress in mathematical reasoning with LLMs has become \emph{closed-source} due to lack of access to training data. This lack of data access limits researchers from understanding the impact of different choices for synthesizing and utilizing the data. With the goal of creating a high-quality finetuning (SFT) dataset for math reasoning, we conduct careful ablation experiments on data synthesis using the recently released \texttt{Llama3.1} family of models. Our experiments show that: (a) solution format matters, with excessively verbose solutions proving detrimental to SFT performance, (b) data generated by a strong teacher outperforms \emph{on-policy} data generated by a weak student model, (c) SFT is robust to low-quality solutions, allowing for imprecise data filtering, and (d) question diversity is crucial for achieving data scaling gains. Based on these insights, we create the OpenMathInstruct-2 dataset, which consists of 14M question-solution pairs ($\approx$ 600K unique questions), making it nearly eight times larger than the previous largest open-source math reasoning dataset. Finetuning the \texttt{Llama-3.1-8B-Base} using OpenMathInstruct-2 outperforms \texttt{Llama3.1-8B-Instruct} on MATH by an absolute 15.9\% (51.9\% $\rightarrow$ 67.8\%). Finally, to accelerate the open-source efforts, we release the code, the finetuned models, and the OpenMathInstruct-2 dataset under a commercially permissive license.
Major Entity Identification: A Generalizable Alternative to Coreference Resolution
Jun 20, 2024



The limited generalization of coreference resolution (CR) models has been a major bottleneck in the task's broad application. Prior work has identified annotation differences, especially for mention detection, as one of the main reasons for the generalization gap and proposed using additional annotated target domain data. Rather than relying on this additional annotation, we propose an alternative formulation of the CR task, Major Entity Identification (MEI), where we: (a) assume the target entities to be specified in the input, and (b) limit the task to only the frequent entities. Through extensive experiments, we demonstrate that MEI models generalize well across domains on multiple datasets with supervised models and LLM-based few-shot prompting. Additionally, the MEI task fits the classification framework, which enables the use of classification-based metrics that are more robust than the current CR metrics. Finally, MEI is also of practical use as it allows a user to search for all mentions of a particular entity or a group of entities of interest.
Nemotron-4 340B Technical Report
Jun 17, 2024



We release the Nemotron-4 340B model family, including Nemotron-4-340B-Base, Nemotron-4-340B-Instruct, and Nemotron-4-340B-Reward. Our models are open access under the NVIDIA Open Model License Agreement, a permissive model license that allows distribution, modification, and use of the models and its outputs. These models perform competitively to open access models on a wide range of evaluation benchmarks, and were sized to fit on a single DGX H100 with 8 GPUs when deployed in FP8 precision. We believe that the community can benefit from these models in various research studies and commercial applications, especially for generating synthetic data to train smaller language models. Notably, over 98% of data used in our model alignment process is synthetically generated, showcasing the effectiveness of these models in generating synthetic data. To further support open research and facilitate model development, we are also open-sourcing the synthetic data generation pipeline used in our model alignment process.
Code Pretraining Improves Entity Tracking Abilities of Language Models
May 31, 2024



Recent work has provided indirect evidence that pretraining language models on code improves the ability of models to track state changes of discourse entities expressed in natural language. In this work, we systematically test this claim by comparing pairs of language models on their entity tracking performance. Critically, the pairs consist of base models and models trained on top of these base models with additional code data. We extend this analysis to additionally examine the effect of math training, another highly structured data type, and alignment tuning, an important step for enhancing the usability of models. We find clear evidence that models additionally trained on large amounts of code outperform the base models. On the other hand, we find no consistent benefit of additional math training or alignment tuning across various model families.
OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset
Feb 15, 2024



Recent work has shown the immense potential of synthetically generated datasets for training large language models (LLMs), especially for acquiring targeted skills. Current large-scale math instruction tuning datasets such as MetaMathQA (Yu et al., 2024) and MAmmoTH (Yue et al., 2024) are constructed using outputs from closed-source LLMs with commercially restrictive licenses. A key reason limiting the use of open-source LLMs in these data generation pipelines has been the wide gap between the mathematical skills of the best closed-source LLMs, such as GPT-4, and the best open-source LLMs. Building on the recent progress in open-source LLMs, our proposed prompting novelty, and some brute-force scaling, we construct OpenMathInstruct-1, a math instruction tuning dataset with 1.8M problem-solution pairs. The dataset is constructed by synthesizing code-interpreter solutions for GSM8K and MATH, two popular math reasoning benchmarks, using the recently released and permissively licensed Mixtral model. Our best model, OpenMath-CodeLlama-70B, trained on a subset of OpenMathInstruct-1, achieves a score of 84.6% on GSM8K and 50.7% on MATH, which is competitive with the best gpt-distilled models. We release our code, models, and the OpenMathInstruct-1 dataset under a commercially permissive license.
Learning to Reason and Memorize with Self-Notes
May 01, 2023



Large language models have been shown to struggle with limited context memory and multi-step reasoning. We propose a simple method for solving both of these problems by allowing the model to take Self-Notes. Unlike recent scratchpad approaches, the model can deviate from the input context at any time to explicitly think. This allows the model to recall information and perform reasoning on the fly as it reads the context, thus extending its memory and enabling multi-step reasoning. Our experiments on multiple tasks demonstrate that our method can successfully generalize to longer and more complicated instances from their training setup by taking Self-Notes at inference time.
Adapting Pretrained Text-to-Text Models for Long Text Sequences
Sep 21, 2022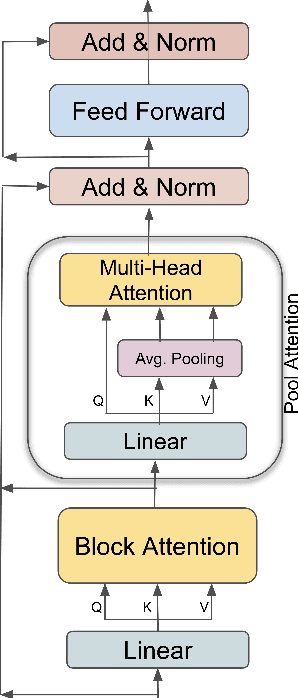
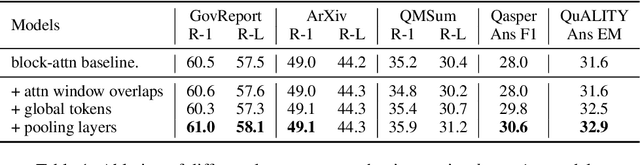
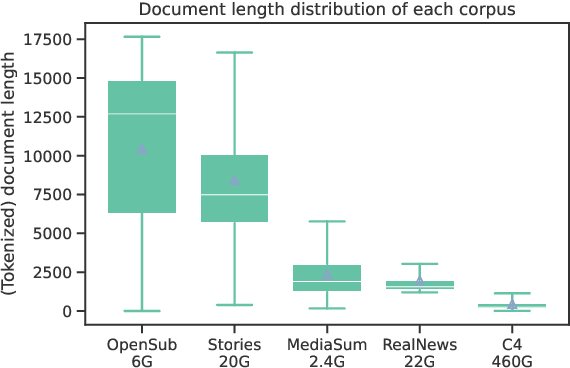
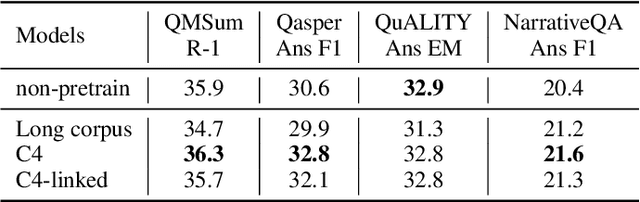
We present an empirical study of adapting an existing pretrained text-to-text model for long-sequence inputs. Through a comprehensive study along three axes of the pretraining pipeline -- model architecture, optimization objective, and pretraining corpus, we propose an effective recipe to build long-context models from existing short-context models. Specifically, we replace the full attention in transformers with pooling-augmented blockwise attention, and pretrain the model with a masked-span prediction task with spans of varying length. In terms of the pretraining corpus, we find that using randomly concatenated short-documents from a large open-domain corpus results in better performance than using existing long document corpora which are typically limited in their domain coverage. With these findings, we build a long-context model that achieves competitive performance on long-text QA tasks and establishes the new state of the art on five long-text summarization datasets, often outperforming previous methods with larger model sizes.
Efficient and Interpretable Neural Models for Entity Tracking
Aug 30, 2022

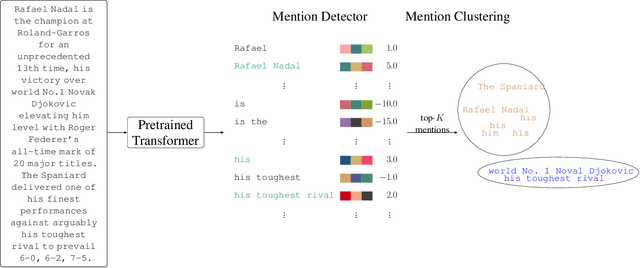
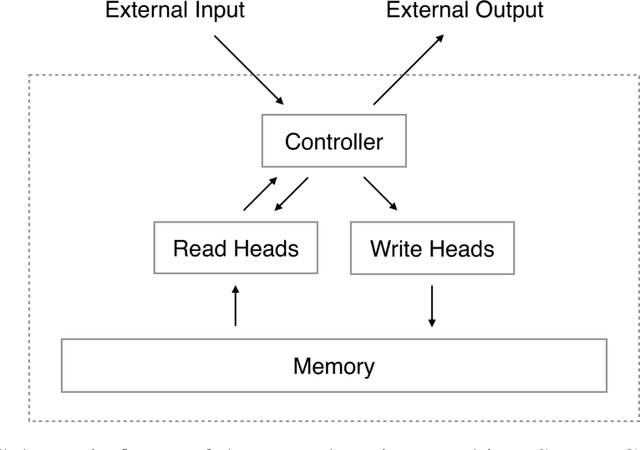
What would it take for a natural language model to understand a novel, such as The Lord of the Rings? Among other things, such a model must be able to: (a) identify and record new characters (entities) and their attributes as they are introduced in the text, and (b) identify subsequent references to the characters previously introduced and update their attributes. This problem of entity tracking is essential for language understanding, and thus, useful for a wide array of downstream applications in NLP such as question-answering, summarization. In this thesis, we focus on two key problems in relation to facilitating the use of entity tracking models: (i) scaling entity tracking models to long documents, such as a novel, and (ii) integrating entity tracking into language models. Applying language technologies to long documents has garnered interest recently, but computational constraints are a significant bottleneck in scaling up current methods. In this thesis, we argue that computationally efficient entity tracking models can be developed by representing entities with rich, fixed-dimensional vector representations derived from pretrained language models, and by exploiting the ephemeral nature of entities. We also argue for the integration of entity tracking into language models as it will allow for: (i) wider application given the current ubiquitous use of pretrained language models in NLP applications, and (ii) easier adoption since it is much easier to swap in a new pretrained language model than to integrate a separate standalone entity tracking model.