 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplore to Evolve: Scaling Evolved Aggregation Logic via Proactive Online Exploration for Deep Research Agents
Oct 16, 2025Deep research web agents not only retrieve information from diverse sources such as web environments, files, and multimodal inputs, but more importantly, they need to rigorously analyze and aggregate knowledge for insightful research. However, existing open-source deep research agents predominantly focus on enhancing information-seeking capabilities of web agents to locate specific information, while overlooking the essential need for information aggregation, which would limit their ability to support in-depth research. We propose an Explore to Evolve paradigm to scalably construct verifiable training data for web agents. Begins with proactive online exploration, an agent sources grounded information by exploring the real web. Using the collected evidence, the agent then self-evolves an aggregation program by selecting, composing, and refining operations from 12 high-level logical types to synthesize a verifiable QA pair. This evolution from high-level guidance to concrete operations allowed us to scalably produce WebAggregatorQA, a dataset of 10K samples across 50K websites and 11 domains. Based on an open-source agent framework, SmolAgents, we collect supervised fine-tuning trajectories to develop a series of foundation models, WebAggregator. WebAggregator-8B matches the performance of GPT-4.1, while the 32B variant surpasses GPT-4.1 by more than 10% on GAIA-text and closely approaches Claude-3.7-sonnet. Moreover, given the limited availability of benchmarks that evaluate web agents' information aggregation abilities, we construct a human-annotated evaluation split of WebAggregatorQA as a challenging test set. On this benchmark, Claude-3.7-sonnet only achieves 28%, and GPT-4.1 scores 25.8%. Even when agents manage to retrieve all references, they still struggle on WebAggregatorQA, highlighting the need to strengthen the information aggregation capabilities of web agent foundations.
WithAnyone: Towards Controllable and ID Consistent Image Generation
Oct 16, 2025Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation.
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Oct 02, 2025Diffusion models have revolutionized image and video generation, achieving unprecedented visual quality. However, their reliance on transformer architectures incurs prohibitively high computational costs, particularly when extending generation to long videos. Recent work has explored autoregressive formulations for long video generation, typically by distilling from short-horizon bidirectional teachers. Nevertheless, given that teacher models cannot synthesize long videos, the extrapolation of student models beyond their training horizon often leads to pronounced quality degradation, arising from the compounding of errors within the continuous latent space. In this paper, we propose a simple yet effective approach to mitigate quality degradation in long-horizon video generation without requiring supervision from long-video teachers or retraining on long video datasets. Our approach centers on exploiting the rich knowledge of teacher models to provide guidance for the student model through sampled segments drawn from self-generated long videos. Our method maintains temporal consistency while scaling video length by up to 20x beyond teacher's capability, avoiding common issues such as over-exposure and error-accumulation without recomputing overlapping frames like previous methods. When scaling up the computation, our method shows the capability of generating videos up to 4 minutes and 15 seconds, equivalent to 99.9% of the maximum span supported by our base model's position embedding and more than 50x longer than that of our baseline model. Experiments on standard benchmarks and our proposed improved benchmark demonstrate that our approach substantially outperforms baseline methods in both fidelity and consistency. Our long-horizon videos demo can be found at https://self-forcing-plus-plus.github.io/
F2LLM Technical Report: Matching SOTA Embedding Performance with 6 Million Open-Source Data
Oct 02, 2025



We introduce F2LLM - Foundation to Feature Large Language Models, a suite of state-of-the-art embedding models in three sizes: 0.6B, 1.7B, and 4B. Unlike previous top-ranking embedding models that require massive contrastive pretraining, sophisticated training pipelines, and costly synthetic training data, F2LLM is directly finetuned from foundation models on 6 million query-document-negative tuples curated from open-source, non-synthetic datasets, striking a strong balance between training cost, model size, and embedding performance. On the MTEB English leaderboard, F2LLM-4B ranks 2nd among models with approximately 4B parameters and 7th overall, while F2LLM-1.7B ranks 1st among models in the 1B-2B size range. To facilitate future research in the field, we release the models, training dataset, and code, positioning F2LLM as a strong, reproducible, and budget-friendly baseline for future works.
Direct Simultaneous Translation Activation for Large Audio-Language Models
Sep 19, 2025



Simultaneous speech-to-text translation (Simul-S2TT) aims to translate speech into target text in real time, outputting translations while receiving source speech input, rather than waiting for the entire utterance to be spoken. Simul-S2TT research often modifies model architectures to implement read-write strategies. However, with the rise of large audio-language models (LALMs), a key challenge is how to directly activate Simul-S2TT capabilities in base models without additional architectural changes. In this paper, we introduce {\bf Simul}taneous {\bf S}elf-{\bf A}ugmentation ({\bf SimulSA}), a strategy that utilizes LALMs' inherent capabilities to obtain simultaneous data by randomly truncating speech and constructing partially aligned translation. By incorporating them into offline SFT data, SimulSA effectively bridges the distribution gap between offline translation during pretraining and simultaneous translation during inference. Experimental results demonstrate that augmenting only about {\bf 1\%} of the simultaneous data, compared to the full offline SFT data, can significantly activate LALMs' Simul-S2TT capabilities without modifications to model architecture or decoding strategy.
Large Language Model-assisted Meta-optimizer for Automated Design of Constrained Evolutionary Algorithm
Sep 16, 2025Meta-black-box optimization has been significantly advanced through the use of large language models (LLMs), yet in fancy on constrained evolutionary optimization. In this work, AwesomeDE is proposed that leverages LLMs as the strategy of meta-optimizer to generate update rules for constrained evolutionary algorithm without human intervention. On the meanwhile, $RTO^2H$ framework is introduced for standardize prompt design of LLMs. The meta-optimizer is trained on a diverse set of constrained optimization problems. Key components, including prompt design and iterative refinement, are systematically analyzed to determine their impact on design quality. Experimental results demonstrate that the proposed approach outperforms existing methods in terms of computational efficiency and solution accuracy. Furthermore, AwesomeDE is shown to generalize well across distinct problem domains, suggesting its potential for broad applicability. This research contributes to the field by providing a scalable and data-driven methodology for automated constrained algorithm design, while also highlighting limitations and directions for future work.
Beyond flattening: a geometrically principled positional encoding for vision transformers with Weierstrass elliptic functions
Aug 26, 2025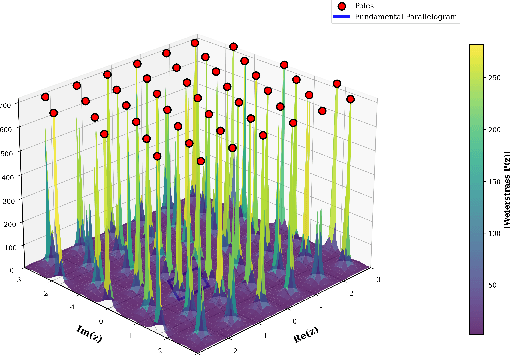

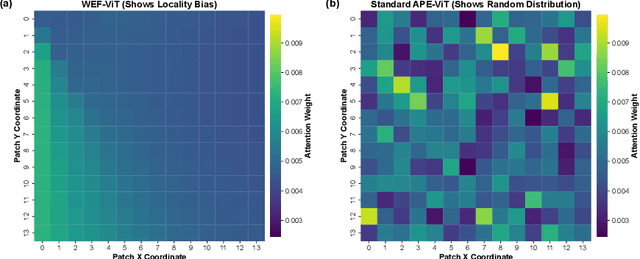

Vision Transformers have demonstrated remarkable success in computer vision tasks, yet their reliance on learnable one-dimensional positional embeddings fundamentally disrupts the inherent two-dimensional spatial structure of images through patch flattening procedures. Traditional positional encoding approaches lack geometric constraints and fail to establish monotonic correspondence between Euclidean spatial distances and sequential index distances, thereby limiting the model's capacity to leverage spatial proximity priors effectively. We propose Weierstrass Elliptic Function Positional Encoding (WEF-PE), a mathematically principled approach that directly addresses two-dimensional coordinates through natural complex domain representation, where the doubly periodic properties of elliptic functions align remarkably with translational invariance patterns commonly observed in visual data. Our method exploits the non-linear geometric nature of elliptic functions to encode spatial distance relationships naturally, while the algebraic addition formula enables direct derivation of relative positional information between arbitrary patch pairs from their absolute encodings. Comprehensive experiments demonstrate that WEF-PE achieves superior performance across diverse scenarios, including 63.78\% accuracy on CIFAR-100 from-scratch training with ViT-Tiny architecture, 93.28\% on CIFAR-100 fine-tuning with ViT-Base, and consistent improvements on VTAB-1k benchmark tasks. Theoretical analysis confirms the distance-decay property through rigorous mathematical proof, while attention visualization reveals enhanced geometric inductive bias and more coherent semantic focus compared to conventional approaches.The source code implementing the methods described in this paper is publicly available on GitHub.
Proximal Supervised Fine-Tuning
Aug 25, 2025



Supervised fine-tuning (SFT) of foundation models often leads to poor generalization, where prior capabilities deteriorate after tuning on new tasks or domains. Inspired by trust-region policy optimization (TRPO) and proximal policy optimization (PPO) in reinforcement learning (RL), we propose Proximal SFT (PSFT). This fine-tuning objective incorporates the benefits of trust-region, effectively constraining policy drift during SFT while maintaining competitive tuning. By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages. Experiments across mathematical and human-value domains show that PSFT matches SFT in-domain, outperforms it in out-of-domain generalization, remains stable under prolonged training without causing entropy collapse, and provides a stronger foundation for the subsequent optimization.
Linear Preference Optimization: Decoupled Gradient Control via Absolute Regularization
Aug 20, 2025DPO (Direct Preference Optimization) has become a widely used offline preference optimization algorithm due to its simplicity and training stability. However, DPO is prone to overfitting and collapse. To address these challenges, we propose Linear Preference Optimization (LPO), a novel alignment framework featuring three key innovations. First, we introduce gradient decoupling by replacing the log-sigmoid function with an absolute difference loss, thereby isolating the optimization dynamics. Second, we improve stability through an offset constraint combined with a positive regularization term to preserve the chosen response quality. Third, we implement controllable rejection suppression using gradient separation with straightforward estimation and a tunable coefficient that linearly regulates the descent of the rejection probability. Through extensive experiments, we demonstrate that LPO consistently improves performance on various tasks, including general text tasks, math tasks, and text-to-speech (TTS) tasks. These results establish LPO as a robust and tunable paradigm for preference alignment, and we release the source code, models, and training data publicly.
CPO: Addressing Reward Ambiguity in Role-playing Dialogue via Comparative Policy Optimization
Aug 12, 2025Reinforcement Learning Fine-Tuning (RLFT) has achieved notable success in tasks with objectively verifiable answers (e.g., code generation, mathematical reasoning), yet struggles with open-ended subjective tasks like role-playing dialogue. Traditional reward modeling approaches, which rely on independent sample-wise scoring, face dual challenges: subjective evaluation criteria and unstable reward signals.Motivated by the insight that human evaluation inherently combines explicit criteria with implicit comparative judgments, we propose Comparative Policy Optimization (CPO). CPO redefines the reward evaluation paradigm by shifting from sample-wise scoring to comparative group-wise scoring.Building on the same principle, we introduce the CharacterArena evaluation framework, which comprises two stages:(1) Contextualized Multi-turn Role-playing Simulation, and (2) Trajectory-level Comparative Evaluation. By operationalizing subjective scoring via objective trajectory comparisons, CharacterArena minimizes contextual bias and enables more robust and fair performance evaluation. Empirical results on CharacterEval, CharacterBench, and CharacterArena confirm that CPO effectively mitigates reward ambiguity and leads to substantial improvements in dialogue quality.