 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoVoice: LLM-based Emotional Text-To-Speech Model with Freestyle Text Prompting
Apr 22, 2025Human speech goes beyond the mere transfer of information; it is a profound exchange of emotions and a connection between individuals. While Text-to-Speech (TTS) models have made huge progress, they still face challenges in controlling the emotional expression in the generated speech. In this work, we propose EmoVoice, a novel emotion-controllable TTS model that exploits large language models (LLMs) to enable fine-grained freestyle natural language emotion control, and a phoneme boost variant design that makes the model output phoneme tokens and audio tokens in parallel to enhance content consistency, inspired by chain-of-thought (CoT) and chain-of-modality (CoM) techniques. Besides, we introduce EmoVoice-DB, a high-quality 40-hour English emotion dataset featuring expressive speech and fine-grained emotion labels with natural language descriptions. EmoVoice achieves state-of-the-art performance on the English EmoVoice-DB test set using only synthetic training data, and on the Chinese Secap test set using our in-house data. We further investigate the reliability of existing emotion evaluation metrics and their alignment with human perceptual preferences, and explore using SOTA multimodal LLMs GPT-4o-audio and Gemini to assess emotional speech. Demo samples are available at https://yanghaha0908.github.io/EmoVoice/. Dataset, code, and checkpoints will be released.
DianJin-R1: Evaluating and Enhancing Financial Reasoning in Large Language Models
Apr 22, 2025



Effective reasoning remains a core challenge for large language models (LLMs) in the financial domain, where tasks often require domain-specific knowledge, precise numerical calculations, and strict adherence to compliance rules. We propose DianJin-R1, a reasoning-enhanced framework designed to address these challenges through reasoning-augmented supervision and reinforcement learning. Central to our approach is DianJin-R1-Data, a high-quality dataset constructed from CFLUE, FinQA, and a proprietary compliance corpus (Chinese Compliance Check, CCC), combining diverse financial reasoning scenarios with verified annotations. Our models, DianJin-R1-7B and DianJin-R1-32B, are fine-tuned from Qwen2.5-7B-Instruct and Qwen2.5-32B-Instruct using a structured format that generates both reasoning steps and final answers. To further refine reasoning quality, we apply Group Relative Policy Optimization (GRPO), a reinforcement learning method that incorporates dual reward signals: one encouraging structured outputs and another rewarding answer correctness. We evaluate our models on five benchmarks: three financial datasets (CFLUE, FinQA, and CCC) and two general reasoning benchmarks (MATH-500 and GPQA-Diamond). Experimental results show that DianJin-R1 models consistently outperform their non-reasoning counterparts, especially on complex financial tasks. Moreover, on the real-world CCC dataset, our single-call reasoning models match or even surpass the performance of multi-agent systems that require significantly more computational cost. These findings demonstrate the effectiveness of DianJin-R1 in enhancing financial reasoning through structured supervision and reward-aligned learning, offering a scalable and practical solution for real-world applications.
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025


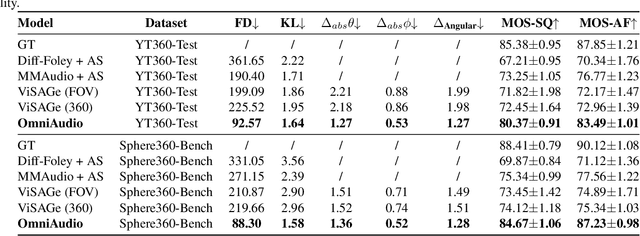
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
An LLM-enabled Multi-Agent Autonomous Mechatronics Design Framework
Apr 20, 2025



Existing LLM-enabled multi-agent frameworks are predominantly limited to digital or simulated environments and confined to narrowly focused knowledge domain, constraining their applicability to complex engineering tasks that require the design of physical embodiment, cross-disciplinary integration, and constraint-aware reasoning. This work proposes a multi-agent autonomous mechatronics design framework, integrating expertise across mechanical design, optimization, electronics, and software engineering to autonomously generate functional prototypes with minimal direct human design input. Operating primarily through a language-driven workflow, the framework incorporates structured human feedback to ensure robust performance under real-world constraints. To validate its capabilities, the framework is applied to a real-world challenge involving autonomous water-quality monitoring and sampling, where traditional methods are labor-intensive and ecologically disruptive. Leveraging the proposed system, a fully functional autonomous vessel was developed with optimized propulsion, cost-effective electronics, and advanced control. The design process was carried out by specialized agents, including a high-level planning agent responsible for problem abstraction and dedicated agents for structural, electronics, control, and software development. This approach demonstrates the potential of LLM-based multi-agent systems to automate real-world engineering workflows and reduce reliance on extensive domain expertise.
Task Assignment and Exploration Optimization for Low Altitude UAV Rescue via Generative AI Enhanced Multi-agent Reinforcement Learning
Apr 18, 2025Artificial Intelligence (AI)-driven convolutional neural networks enhance rescue, inspection, and surveillance tasks performed by low-altitude uncrewed aerial vehicles (UAVs) and ground computing nodes (GCNs) in unknown environments. However, their high computational demands often exceed a single UAV's capacity, leading to system instability, further exacerbated by the limited and dynamic resources of GCNs. To address these challenges, this paper proposes a novel cooperation framework involving UAVs, ground-embedded robots (GERs), and high-altitude platforms (HAPs), which enable resource pooling through UAV-to-GER (U2G) and UAV-to-HAP (U2H) communications to provide computing services for UAV offloaded tasks. Specifically, we formulate the multi-objective optimization problem of task assignment and exploration optimization in UAVs as a dynamic long-term optimization problem. Our objective is to minimize task completion time and energy consumption while ensuring system stability over time. To achieve this, we first employ the Lyapunov optimization technique to transform the original problem, with stability constraints, into a per-slot deterministic problem. We then propose an algorithm named HG-MADDPG, which combines the Hungarian algorithm with a generative diffusion model (GDM)-based multi-agent deep deterministic policy gradient (MADDPG) approach. We first introduce the Hungarian algorithm as a method for exploration area selection, enhancing UAV efficiency in interacting with the environment. We then innovatively integrate the GDM and multi-agent deep deterministic policy gradient (MADDPG) to optimize task assignment decisions, such as task offloading and resource allocation. Simulation results demonstrate the effectiveness of the proposed approach, with significant improvements in task offloading efficiency, latency reduction, and system stability compared to baseline methods.
FHBench: Towards Efficient and Personalized Federated Learning for Multimodal Healthcare
Apr 15, 2025



Federated Learning (FL) has emerged as an effective solution for multi-institutional collaborations without sharing patient data, offering a range of methods tailored for diverse applications. However, real-world medical datasets are often multimodal, and computational resources are limited, posing significant challenges for existing FL approaches. Recognizing these limitations, we developed the Federated Healthcare Benchmark(FHBench), a benchmark specifically designed from datasets derived from real-world healthcare applications. FHBench encompasses critical diagnostic tasks across domains such as the nervous, cardiovascular, and respiratory systems and general pathology, providing comprehensive support for multimodal healthcare evaluations and filling a significant gap in existing benchmarks. Building on FHBench, we introduced Efficient Personalized Federated Learning with Adaptive LoRA(EPFL), a personalized FL framework that demonstrates superior efficiency and effectiveness across various healthcare modalities. Our results highlight the robustness of FHBench as a benchmarking tool and the potential of EPFL as an innovative approach to advancing healthcare-focused FL, addressing key limitations of existing methods.
AI Agents in Engineering Design: A Multi-Agent Framework for Aesthetic and Aerodynamic Car Design
Mar 30, 2025We introduce the concept of "Design Agents" for engineering applications, particularly focusing on the automotive design process, while emphasizing that our approach can be readily extended to other engineering and design domains. Our framework integrates AI-driven design agents into the traditional engineering workflow, demonstrating how these specialized computational agents interact seamlessly with engineers and designers to augment creativity, enhance efficiency, and significantly accelerate the overall design cycle. By automating and streamlining tasks traditionally performed manually, such as conceptual sketching, styling enhancements, 3D shape retrieval and generative modeling, computational fluid dynamics (CFD) meshing, and aerodynamic simulations, our approach reduces certain aspects of the conventional workflow from weeks and days down to minutes. These agents leverage state-of-the-art vision-language models (VLMs), large language models (LLMs), and geometric deep learning techniques, providing rapid iteration and comprehensive design exploration capabilities. We ground our methodology in industry-standard benchmarks, encompassing a wide variety of conventional automotive designs, and utilize high-fidelity aerodynamic simulations to ensure practical and applicable outcomes. Furthermore, we present design agents that can swiftly and accurately predict simulation outcomes, empowering engineers and designers to engage in more informed design optimization and exploration. This research underscores the transformative potential of integrating advanced generative AI techniques into complex engineering tasks, paving the way for broader adoption and innovation across multiple engineering disciplines.
PartialLoading: User Scheduling and Bandwidth Allocation for Parameter-sharing Edge Inference
Mar 29, 2025By provisioning inference offloading services, edge inference drives the rapid growth of AI applications at the network edge. However, achieving high task throughput with stringent latency requirements remains a significant challenge. To address this issue, we develop a parameter-sharing AI model loading (PartialLoading) framework for multi-user edge inference, which exploits two key insights: 1) the majority of latency arises from loading AI models into server GPU memory, and 2) different AI models can share a significant number of parameters, for which redundant loading should be avoided. Towards this end, we formulate a joint multi-user scheduling and spectrum bandwidth allocation problem to maximize task throughput by exploiting shared parameter blocks across models. The intuition is to judiciously schedule user requests to reuse the shared parameter blocks between consecutively loaded models, thereby reducing model loading time substantially. To facilitate solution finding, we decouple the problem into two sub-problems, i.e., user scheduling and bandwidth allocation, showing that solving them sequentially is equivalent to solving the original problem. Due to the NP-hardness of the problem, we first study an important special case called the "bottom-layer-sharing" case, where AI models share some bottom layers within clusters, and design a dynamic programming-based algorithm to obtain the optimal solution in polynomial time. For the general case, where shared parameter blocks appear at arbitrary positions within AI models, we propose a greedy heuristic to obtain the sub-optimal solution efficiently. Simulation results demonstrate that the proposed framework significantly improves task throughput under deadline constraints compared with user scheduling without exploiting parameter sharing.
Process Reward Modeling with Entropy-Driven Uncertainty
Mar 28, 2025



This paper presents the Entropy-Driven Unified Process Reward Model (EDU-PRM), a novel framework that approximates state-of-the-art performance in process supervision while drastically reducing training costs. EDU-PRM introduces an entropy-guided dynamic step partitioning mechanism, using logit distribution entropy to pinpoint high-uncertainty regions during token generation dynamically. This self-assessment capability enables precise step-level feedback without manual fine-grained annotation, addressing a critical challenge in process supervision. Experiments on the Qwen2.5-72B model with only 7,500 EDU-PRM-generated training queries demonstrate accuracy closely approximating the full Qwen2.5-72B-PRM (71.1% vs. 71.6%), achieving a 98% reduction in query cost compared to prior methods. This work establishes EDU-PRM as an efficient approach for scalable process reward model training.
UniCodec: Unified Audio Codec with Single Domain-Adaptive Codebook
Feb 27, 2025The emergence of audio language models is empowered by neural audio codecs, which establish critical mappings between continuous waveforms and discrete tokens compatible with language model paradigms. The evolutionary trends from multi-layer residual vector quantizer to single-layer quantizer are beneficial for language-autoregressive decoding. However, the capability to handle multi-domain audio signals through a single codebook remains constrained by inter-domain distribution discrepancies. In this work, we introduce UniCodec, a unified audio codec with a single codebook to support multi-domain audio data, including speech, music, and sound. To achieve this, we propose a partitioned domain-adaptive codebook method and domain Mixture-of-Experts strategy to capture the distinct characteristics of each audio domain. Furthermore, to enrich the semantic density of the codec without auxiliary modules, we propose a self-supervised mask prediction modeling approach. Comprehensive objective and subjective evaluations demonstrate that UniCodec achieves excellent audio reconstruction performance across the three audio domains, outperforming existing unified neural codecs with a single codebook, and even surpasses state-of-the-art domain-specific codecs on both acoustic and semantic representation capabilities.