 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LLM-enabled Multi-Agent Autonomous Mechatronics Design Framework
Apr 20, 2025



Existing LLM-enabled multi-agent frameworks are predominantly limited to digital or simulated environments and confined to narrowly focused knowledge domain, constraining their applicability to complex engineering tasks that require the design of physical embodiment, cross-disciplinary integration, and constraint-aware reasoning. This work proposes a multi-agent autonomous mechatronics design framework, integrating expertise across mechanical design, optimization, electronics, and software engineering to autonomously generate functional prototypes with minimal direct human design input. Operating primarily through a language-driven workflow, the framework incorporates structured human feedback to ensure robust performance under real-world constraints. To validate its capabilities, the framework is applied to a real-world challenge involving autonomous water-quality monitoring and sampling, where traditional methods are labor-intensive and ecologically disruptive. Leveraging the proposed system, a fully functional autonomous vessel was developed with optimized propulsion, cost-effective electronics, and advanced control. The design process was carried out by specialized agents, including a high-level planning agent responsible for problem abstraction and dedicated agents for structural, electronics, control, and software development. This approach demonstrates the potential of LLM-based multi-agent systems to automate real-world engineering workflows and reduce reliance on extensive domain expertise.
Dietary Assessment with Multimodal ChatGPT: A Systematic Analysis
Dec 14, 2023



Conventional approaches to dietary assessment are primarily grounded in self-reporting methods or structured interviews conducted under the supervision of dietitians. These methods, however, are often subjective, potentially inaccurate, and time-intensive. Although artificial intelligence (AI)-based solutions have been devised to automate the dietary assessment process, these prior AI methodologies encounter challenges in their ability to generalize across a diverse range of food types, dietary behaviors, and cultural contexts. This results in AI applications in the dietary field that possess a narrow specialization and limited accuracy. Recently, the emergence of multimodal foundation models such as GPT-4V powering the latest ChatGPT has exhibited transformative potential across a wide range of tasks (e.g., Scene understanding and image captioning) in numerous research domains. These models have demonstrated remarkable generalist intelligence and accuracy, capable of processing various data modalities. In this study, we explore the application of multimodal ChatGPT within the realm of dietary assessment. Our findings reveal that GPT-4V excels in food detection under challenging conditions with accuracy up to 87.5% without any fine-tuning or adaptation using food-specific datasets. By guiding the model with specific language prompts (e.g., African cuisine), it shifts from recognizing common staples like rice and bread to accurately identifying regional dishes like banku and ugali. Another GPT-4V's standout feature is its contextual awareness. GPT-4V can leverage surrounding objects as scale references to deduce the portion sizes of food items, further enhancing its accuracy in translating food weight into nutritional content. This alignment with the USDA National Nutrient Database underscores GPT-4V's potential to advance nutritional science and dietary assessment techniques.
Generalist Vision Foundation Models for Medical Imaging: A Case Study of Segment Anything Model on Zero-Shot Medical Segmentation
Apr 25, 2023



We examine the recent Segment Anything Model (SAM) on medical images, and report both quantitative and qualitative zero-shot segmentation results on nine medical image segmentation benchmarks, covering various imaging modalities, such as optical coherence tomography (OCT), magnetic resonance imaging (MRI), and computed tomography (CT), as well as different applications including dermatology, ophthalmology, and radiology. Our experiments reveal that while SAM demonstrates stunning segmentation performance on images from the general domain, for those out-of-distribution images, e.g., medical images, its zero-shot segmentation performance is still limited. Furthermore, SAM demonstrated varying zero-shot segmentation performance across different unseen medical domains. For example, it had a 0.8704 mean Dice score on segmenting under-bruch's membrane layer of retinal OCT, whereas the segmentation accuracy drops to 0.0688 when segmenting retinal pigment epithelium. For certain structured targets, e.g., blood vessels, the zero-shot segmentation of SAM completely failed, whereas a simple fine-tuning of it with small amount of data could lead to remarkable improvements of the segmentation quality. Our study indicates the versatility of generalist vision foundation models on solving specific tasks in medical imaging, and their great potential to achieve desired performance through fine-turning and eventually tackle the challenges of accessing large diverse medical datasets and the complexity of medical domains.
Large AI Models in Health Informatics: Applications, Challenges, and the Future
Mar 21, 2023



Large AI models, or foundation models, are models recently emerging with massive scales both parameter-wise and data-wise, the magnitudes of which often reach beyond billions. Once pretrained, large AI models demonstrate impressive performance in various downstream tasks. A concrete example is the recent debut of ChatGPT, whose capability has compelled people's imagination about the far-reaching influence that large AI models can have and their potential to transform different domains of our life. In health informatics, the advent of large AI models has brought new paradigms for the design of methodologies. The scale of multimodality data in the biomedical and health domain has been ever-expanding especially since the community embraced the era of deep learning, which provides the ground to develop, validate, and advance large AI models for breakthroughs in health-related areas. This article presents an up-to-date comprehensive review of large AI models, from background to their applications. We identify seven key sectors that large AI models are applicable and might have substantial influence, including 1) molecular biology and drug discovery; 2) medical diagnosis and decision-making; 3) medical imaging and vision; 4) medical informatics; 5) medical education; 6) public health; and 7) medical robotics. We examine their challenges in health informatics, followed by a critical discussion about potential future directions and pitfalls of large AI models in transforming the field of health informatics.
Clustering Egocentric Images in Passive Dietary Monitoring with Self-Supervised Learning
Aug 25, 2022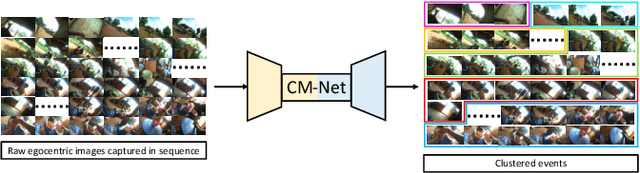
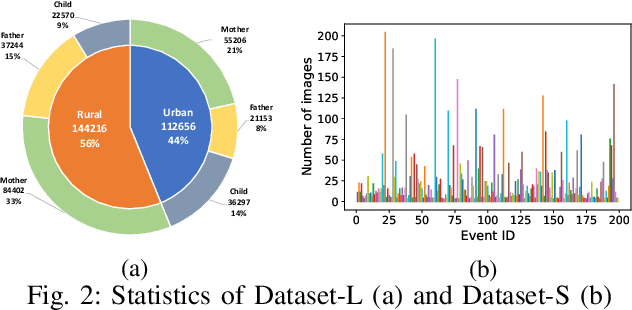

In our recent dietary assessment field studies on passive dietary monitoring in Ghana, we have collected over 250k in-the-wild images. The dataset is an ongoing effort to facilitate accurate measurement of individual food and nutrient intake in low and middle income countries with passive monitoring camera technologies. The current dataset involves 20 households (74 subjects) from both the rural and urban regions of Ghana, and two different types of wearable cameras were used in the studies. Once initiated, wearable cameras continuously capture subjects' activities, which yield massive amounts of data to be cleaned and annotated before analysis is conducted. To ease the data post-processing and annotation tasks, we propose a novel self-supervised learning framework to cluster the large volume of egocentric images into separate events. Each event consists of a sequence of temporally continuous and contextually similar images. By clustering images into separate events, annotators and dietitians can examine and analyze the data more efficiently and facilitate the subsequent dietary assessment processes. Validated on a held-out test set with ground truth labels, the proposed framework outperforms baselines in terms of clustering quality and classification accuracy.
Mining Discriminative Food Regions for Accurate Food Recognition
Jul 08, 2022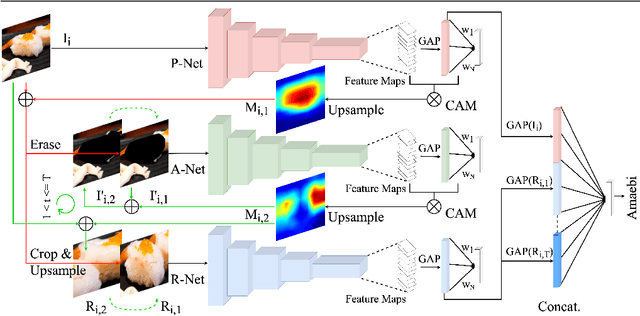
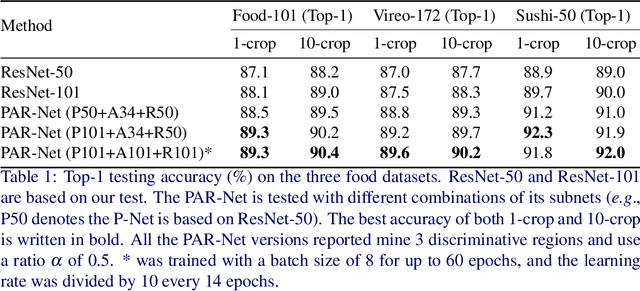

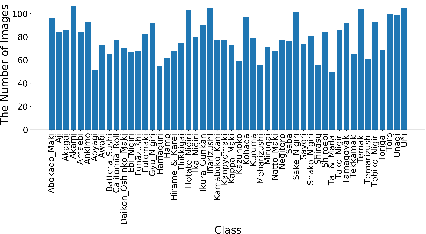
Automatic food recognition is the very first step towards passive dietary monitoring. In this paper, we address the problem of food recognition by mining discriminative food regions. Taking inspiration from Adversarial Erasing, a strategy that progressively discovers discriminative object regions for weakly supervised semantic segmentation, we propose a novel network architecture in which a primary network maintains the base accuracy of classifying an input image, an auxiliary network adversarially mines discriminative food regions, and a region network classifies the resulting mined regions. The global (the original input image) and the local (the mined regions) representations are then integrated for the final prediction. The proposed architecture denoted as PAR-Net is end-to-end trainable, and highlights discriminative regions in an online fashion. In addition, we introduce a new fine-grained food dataset named as Sushi-50, which consists of 50 different sushi categories. Extensive experiments have been conducted to evaluate the proposed approach. On three food datasets chosen (Food-101, Vireo-172, and Sushi-50), our approach performs consistently and achieves state-of-the-art results (top-1 testing accuracy of $90.4\%$, $90.2\%$, $92.0\%$, respectively) compared with other existing approaches. Dataset and code are available at https://github.com/Jianing-Qiu/PARNet
Egocentric Human Trajectory Forecasting with a Wearable Camera and Multi-Modal Fusion
Nov 04, 2021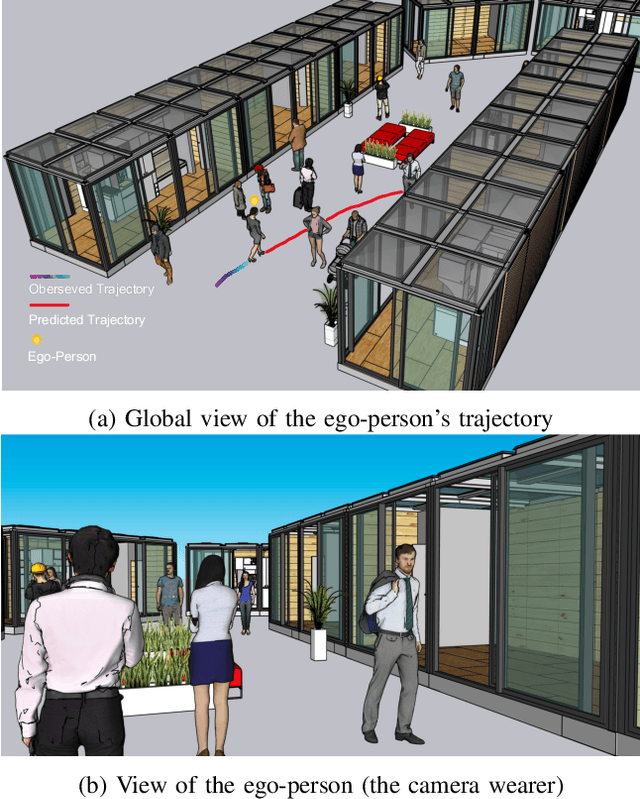

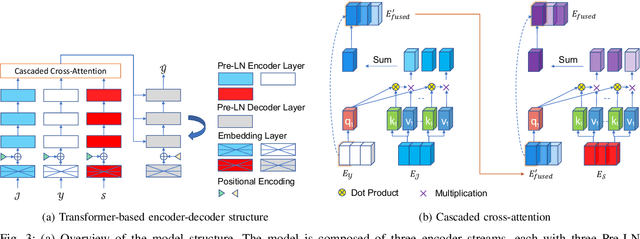

In this paper, we address the problem of forecasting the trajectory of an egocentric camera wearer (ego-person) in crowded spaces. The trajectory forecasting ability learned from the data of different camera wearers walking around in the real world can be transferred to assist visually impaired people in navigation, as well as to instill human navigation behaviours in mobile robots, enabling better human-robot interactions. To this end, a novel egocentric human trajectory forecasting dataset was constructed, containing real trajectories of people navigating in crowded spaces wearing a camera, as well as extracted rich contextual data. We extract and utilize three different modalities to forecast the trajectory of the camera wearer, i.e., his/her past trajectory, the past trajectories of nearby people, and the environment such as the scene semantics or the depth of the scene. A Transformer-based encoder-decoder neural network model, integrated with a novel cascaded cross-attention mechanism that fuses multiple modalities, has been designed to predict the future trajectory of the camera wearer. Extensive experiments have been conducted, and the results have shown that our model outperforms the state-of-the-art methods in egocentric human trajectory forecasting.
Egocentric Image Captioning for Privacy-Preserved Passive Dietary Intake Monitoring
Jul 01, 2021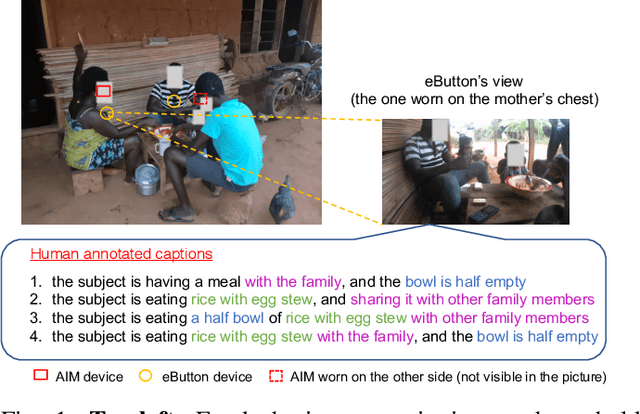
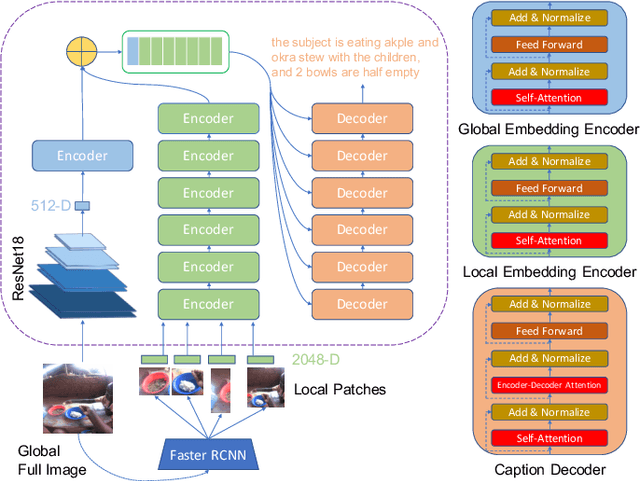
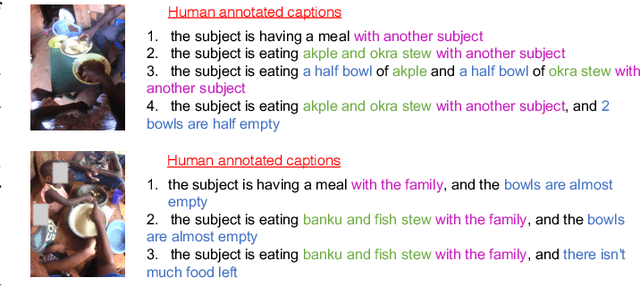
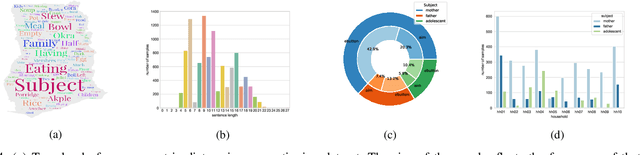
Camera-based passive dietary intake monitoring is able to continuously capture the eating episodes of a subject, recording rich visual information, such as the type and volume of food being consumed, as well as the eating behaviours of the subject. However, there currently is no method that is able to incorporate these visual clues and provide a comprehensive context of dietary intake from passive recording (e.g., is the subject sharing food with others, what food the subject is eating, and how much food is left in the bowl). On the other hand, privacy is a major concern while egocentric wearable cameras are used for capturing. In this paper, we propose a privacy-preserved secure solution (i.e., egocentric image captioning) for dietary assessment with passive monitoring, which unifies food recognition, volume estimation, and scene understanding. By converting images into rich text descriptions, nutritionists can assess individual dietary intake based on the captions instead of the original images, reducing the risk of privacy leakage from images. To this end, an egocentric dietary image captioning dataset has been built, which consists of in-the-wild images captured by head-worn and chest-worn cameras in field studies in Ghana. A novel transformer-based architecture is designed to caption egocentric dietary images. Comprehensive experiments have been conducted to evaluate the effectiveness and to justify the design of the proposed architecture for egocentric dietary image captioning. To the best of our knowledge, this is the first work that applies image captioning to dietary intake assessment in real life settings.
Indoor Future Person Localization from an Egocentric Wearable Camera
Mar 06, 2021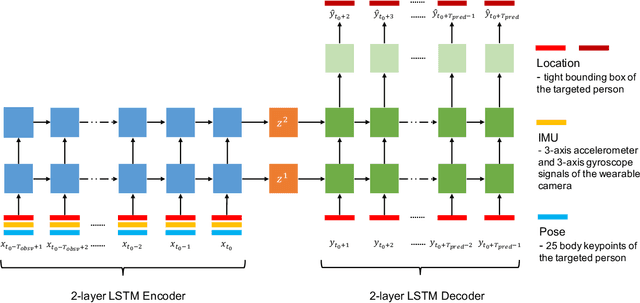

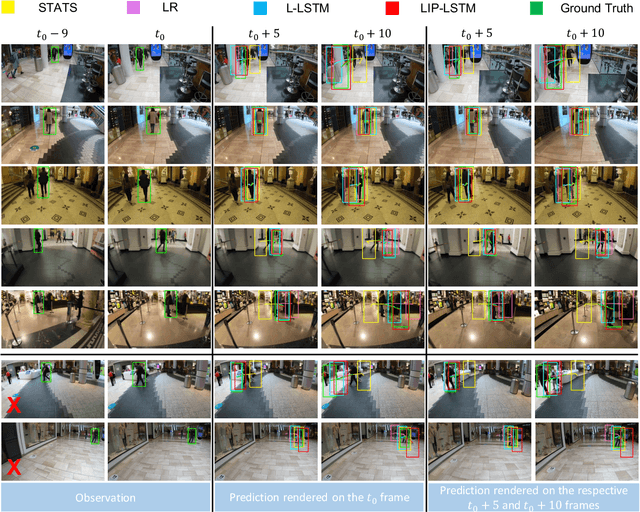

Accurate prediction of future person location and movement trajectory from an egocentric wearable camera can benefit a wide range of applications, such as assisting visually impaired people in navigation, and the development of mobility assistance for people with disability. In this work, a new egocentric dataset was constructed using a wearable camera, with 8,250 short clips of a targeted person either walking 1) toward, 2) away, or 3) across the camera wearer in indoor environments, or 4) staying still in the scene, and 13,817 person bounding boxes were manually labelled. Apart from the bounding boxes, the dataset also contains the estimated pose of the targeted person as well as the IMU signal of the wearable camera at each time point. An LSTM-based encoder-decoder framework was designed to predict the future location and movement trajectory of the targeted person in this egocentric setting. Extensive experiments have been conducted on the new dataset, and have shown that the proposed method is able to reliably and better predict future person location and trajectory in egocentric videos captured by the wearable camera compared to three baselines.