 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR-VAE: Structured Topology-Aware Regularization for Audio Reconstruction and Generation
Jun 22, 2026Continuous Variational Autoencoders (VAEs) serve as the fundamental continuous tokenizer for modern neural audio generation systems, enabling high-fidelity reconstruction while providing a compact, smooth latent space for downstream generative priors. However, continuous VAEs face a fundamental conflict among compression rate, reconstruction fidelity, and latent space topology, which we formalize as the Rate-Distortion-Regularity Trilemma. This trilemma stems from a topological mismatch: the isotropic Gaussian prior in standard VAEs imposes a flat latent geometry that fails to accommodate audio's hierarchical nature, where low-frequency components are structured and compressible while high-frequency components are stochastic and incompressible, leading to disordered information packing in which crucial semantic features are interleaved with high-entropy noise. To address this challenge, we propose Structured Topology-Aware Regularization (STAR), a general training strategy that reshapes latent space geometry by imposing a growth-based constraint field, routing structural and textural information into channel subspaces with matching capacities. STAR is applicable to any VAE architecture and effectively resolves the trilemma, as demonstrated in CNN-based VAEs. We further present STAR-VAE, which combines STAR with a hybrid CNN-Mamba architecture for local feature extraction and linear-complexity global context modeling, and STAR-Gen, an LLM-based Flow Matching framework that leverages STAR-VAE's structured latent space for high-fidelity generation without vector quantization artifacts. Experiments across diverse audio domains show that STAR-VAE achieves state-of-the-art reconstruction fidelity and enhanced semantic information preservation, while the structured latent space improves both traditional diffusion models and STAR-Gen for text-to-audio generation.
AudioCALM: Continuous Autoregressive Language Modeling for Universal Audio Generation
Jun 22, 2026Unifying speech, sound, and music generation in one model is hindered by tradeoffs between fidelity, end-to-end training, in-context conditioning, and variable-length synthesis that no current paradigm fully resolves. To address this challenge, we present AudioCALM, a universal audio generation framework that extends autoregressive (AR) next-token prediction from discrete tokens to continuous audio latents: a thin flow-matching head replaces the softmax to predict rectified-flow velocities at each position, and a block-causal AR-Flow attention pattern produces arbitrary-length output. Joint training of multiple audio generation tasks faces an asymmetric text--audio mismatch: speech transcripts align to specific time spans and demand tight, time-aligned attention, whereas sound and music captions describe only overall semantics and rely on diffuse, holistic attention; mixing the two disproportionately degrades sound and music generation. We address this asymmetry at two levels: a data reformulation strategy that unifies all three tasks under a single description-style conditioning interface, and a novel architecture Asymmetric Mixture-of-Modality-Experts (A-MoME), which adds a dedicated residual expert for speech while sound and music share the backbone, incurring no inference overhead on non-speech inputs. Experimental results demonstrate that AudioCALM matches modality-specific state-of-the-art and outperforms prior unified baselines on speech, sound, and music generation benchmarks.
X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
Jun 01, 2026While video streaming understanding has made significant strides, real-world applications, such as live sports broadcasting, autonomous driving, and multi-screen collaboration, inherently demand continuous, multi-stream interactions. However, existing benchmarks are confined to single-stream paradigms, leaving a critical gap in evaluating online, cross-stream reasoning. To bridge this, we introduce X-Stream, the first benchmark dedicated to multi-stream streaming understanding. Comprising 4,220 rigorously curated QA pairs across 932 videos, X-Stream evaluates 11 subtasks across multi-window, multi-view, and multi-device scenarios. Crucially, our dataset is constructed using a novel dual-verification pipeline that prevents over-reliance on a single stream. Furthermore, we pioneer the conceptualization of multi-modal large language models (MLLMs) as naive multiplexers, systematically evaluating their performance through the lens of Signal Multiplexing Theory. Our extensive online inference experiments reveal a stark reality: state-of-the-art MLLMs struggle significantly with concurrent streams, achieving only about 50% score and exhibiting poor proactive ability. Ultimately, X-Stream exposes the trade-off of current multiplexing schemes, providing both a practical evaluation protocol and empirical guidance for next-generation multi-stream agents.
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
ThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Jun 26, 2025



While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, such generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present \textbf{ThinkSound}, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal large language model generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce \textbf{AudioCoT}, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics and excels in out-of-distribution Movie Gen Audio benchmark. The demo page is available at https://ThinkSound-Demo.github.io.
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025


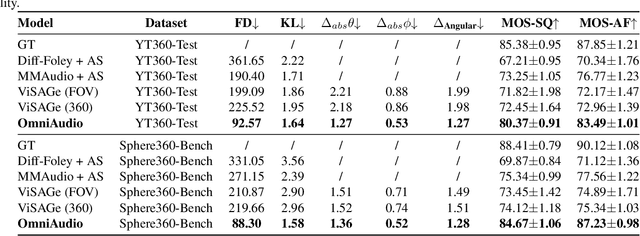
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024



In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
FlashAudio: Rectified Flows for Fast and High-Fidelity Text-to-Audio Generation
Oct 16, 2024



Recent advancements in latent diffusion models (LDMs) have markedly enhanced text-to-audio generation, yet their iterative sampling processes impose substantial computational demands, limiting practical deployment. While recent methods utilizing consistency-based distillation aim to achieve few-step or single-step inference, their one-step performance is constrained by curved trajectories, preventing them from surpassing traditional diffusion models. In this work, we introduce FlashAudio with rectified flows to learn straight flow for fast simulation. To alleviate the inefficient timesteps allocation and suboptimal distribution of noise, FlashAudio optimizes the time distribution of rectified flow with Bifocal Samplers and proposes immiscible flow to minimize the total distance of data-noise pairs in a batch vias assignment. Furthermore, to address the amplified accumulation error caused by the classifier-free guidance (CFG), we propose Anchored Optimization, which refines the guidance scale by anchoring it to a reference trajectory. Experimental results on text-to-audio generation demonstrate that FlashAudio's one-step generation performance surpasses the diffusion-based models with hundreds of sampling steps on audio quality and enables a sampling speed of 400x faster than real-time on a single NVIDIA 4090Ti GPU.
Both Ears Wide Open: Towards Language-Driven Spatial Audio Generation
Oct 14, 2024



Recently, diffusion models have achieved great success in mono-channel audio generation. However, when it comes to stereo audio generation, the soundscapes often have a complex scene of multiple objects and directions. Controlling stereo audio with spatial contexts remains challenging due to high data costs and unstable generative models. To the best of our knowledge, this work represents the first attempt to address these issues. We first construct a large-scale, simulation-based, and GPT-assisted dataset, BEWO-1M, with abundant soundscapes and descriptions even including moving and multiple sources. Beyond text modality, we have also acquired a set of images and rationally paired stereo audios through retrieval to advance multimodal generation. Existing audio generation models tend to generate rather random and indistinct spatial audio. To provide accurate guidance for latent diffusion models, we introduce the SpatialSonic model utilizing spatial-aware encoders and azimuth state matrices to reveal reasonable spatial guidance. By leveraging spatial guidance, our unified model not only achieves the objective of generating immersive and controllable spatial audio from text and image but also enables interactive audio generation during inference. Finally, under fair settings, we conduct subjective and objective evaluations on simulated and real-world data to compare our approach with prevailing methods. The results demonstrate the effectiveness of our method, highlighting its capability to generate spatial audio that adheres to physical rules.
MEDIC: Zero-shot Music Editing with Disentangled Inversion Control
Jul 18, 2024Text-guided diffusion models catalyze a paradigm shift in audio generation, facilitating the adaptability of source audio to conform to specific textual prompts. Recent advancements introduce inversion techniques, like DDIM inversion, to zero-shot editing, exploiting pre-trained diffusion models for audio modification. Nonetheless, our investigation exposes that DDIM inversion suffers from an accumulation of errors across each diffusion step, undermining its efficacy. And the lack of attention control hinders the fine-grained manipulations of music. To counteract these limitations, we introduce the \textit{Disentangled Inversion} technique, which is designed to disentangle the diffusion process into triple branches, thereby magnifying their individual capabilities for both precise editing and preservation. Furthermore, we propose the \textit{Harmonized Attention Control} framework, which unifies the mutual self-attention and cross-attention with an additional Harmonic Branch to achieve the desired composition and structural information in the target music. Collectively, these innovations comprise the \textit{Disentangled Inversion Control (DIC)} framework, enabling accurate music editing whilst safeguarding structural integrity. To benchmark audio editing efficacy, we introduce \textit{ZoME-Bench}, a comprehensive music editing benchmark hosting 1,100 samples spread across 10 distinct editing categories, which facilitates both zero-shot and instruction-based music editing tasks. Our method demonstrates unparalleled performance in edit fidelity and essential content preservation, outperforming contemporary state-of-the-art inversion techniques.