 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Speech Representation Better Matches Text-Native Reasoning? A Study of Speech-Text Alignment on Frame Rate and Representation
Jun 10, 2026Spoken dialogue models typically start from text LLM backbones, yet reasoning often degrades when conditioning on speech instead of text. We attribute part of this modality gap to a temporal-granularity mismatch: speech tokens are temporally redundant and far longer than text under matched semantics, diluting per-token semantic density and weakening text-native reasoning dynamics. We study speech token design as a representation selection problem and sweep frame rates under a frozen LLM backbone with a fixed information rate. To make low frame rates feasible, we introduce factorized FSQ and a lightweight non-autoregressive audio LM head, scaling capacity to nearly 300\,bits/frame without sacrificing efficient prediction. With the bottleneck removed, we sweep frame rates (50$\rightarrow$2.08\,Hz) and alignment depth, and observe a consistent best regime for speech QA at 4.17\,Hz with intermediate-layer representation alignment.
LongSpace: Exploring Long-Horizon Spatial Memory from Perception to Recall in Video
Jun 04, 2026Multimodal Large Language Models (MLLMs) have advanced image and video understanding and can increasingly handle longer visual inputs. Long-horizon tasks such as autonomous driving and robotic navigation require more than recognizing the current view, as models must remember and retrieve previously observed spatial layouts, routes, viewpoint changes, and object states. To evaluate this capability, we introduce LongSpace-Bench, a room-tour video benchmark for long-horizon spatial memory, covering scene perception, spatial relations, and spatial memory. In this work, we further propose LongSpace, a memory framework for long-video spatial reasoning. LongSpace models long videos as sequential chunks, incorporates 3D structural cues into early decoder layers, and constructs layer-aware memory for question-guided retrieval. Experiments on multiple spatial reasoning benchmarks show that LongSpace improves long-video spatial understanding, further demonstrating explicit spatial memory as a key capability for long-horizon video MLLMs.
Benchmark Everything Everywhere All at Once
Jun 04, 2026Benchmarks are fundamental for evaluating and advancing LLMs and MLLMs by providing standardized and explicit measures of performance. However, their construction is labor-intensive and hard to reuse, raising concerns about sustainability and scalability. Moreover, existing benchmarks often quickly reach performance saturation after their release, resulting in insufficient discrimination among state-of-the-art models. To address these challenges, we introduce Benchmark Agent, a fully autonomous agentic system designed for benchmark building. Our framework orchestrates the complete benchmark construction pipeline, from user query analysis and subtask design to data annotation and quality control. To assess Benchmark Agent, we implement it to produce 15 representative benchmarks, spanning diverse evaluation scenarios, including text understanding, multimodal understanding, and domain-specific reasoning. Extensive experiments, including human evaluation, LLM-as-a-judge assessment, and consistency checks, demonstrate Benchmark Agent can generate high-quality benchmark samples with minimal human involvement. More importantly, through continual evaluation, we observe several insightful findings, including that current models struggle with certain domain-specific reasoning tasks. We believe that rapidly evolving benchmarks can contribute significantly to the research community. The preview and code will be publicly available at the demo page and code repository.
X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
Jun 01, 2026While video streaming understanding has made significant strides, real-world applications, such as live sports broadcasting, autonomous driving, and multi-screen collaboration, inherently demand continuous, multi-stream interactions. However, existing benchmarks are confined to single-stream paradigms, leaving a critical gap in evaluating online, cross-stream reasoning. To bridge this, we introduce X-Stream, the first benchmark dedicated to multi-stream streaming understanding. Comprising 4,220 rigorously curated QA pairs across 932 videos, X-Stream evaluates 11 subtasks across multi-window, multi-view, and multi-device scenarios. Crucially, our dataset is constructed using a novel dual-verification pipeline that prevents over-reliance on a single stream. Furthermore, we pioneer the conceptualization of multi-modal large language models (MLLMs) as naive multiplexers, systematically evaluating their performance through the lens of Signal Multiplexing Theory. Our extensive online inference experiments reveal a stark reality: state-of-the-art MLLMs struggle significantly with concurrent streams, achieving only about 50% score and exhibiting poor proactive ability. Ultimately, X-Stream exposes the trade-off of current multiplexing schemes, providing both a practical evaluation protocol and empirical guidance for next-generation multi-stream agents.
Talker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
Apr 26, 2026Joint audio-video generation models have shown that unified generation yields stronger cross-modal coherence than cascaded approaches. However, existing models couple modalities throughout denoising via pervasive attention, treating high-level semantics and low-level details in a fully entangled manner. This is suboptimal for talking head synthesis: while audio and facial motion are semantically correlated, their low-level realizations (acoustic signals and visual textures) follow distinct rendering processes. Enforcing joint modeling across all levels causes unnecessary entanglement and reduces efficiency. We propose Talker-T2AV, an autoregressive diffusion framework where high-level cross-modal modeling occurs in a shared backbone, while low-level refinement uses modality-specific decoders. A shared autoregressive language model jointly reasons over audio and video in a unified patch-level token space. Two lightweight diffusion transformer heads decode the hidden states into frame-level audio and video latents. Experiments on talking portrait benchmarks show Talker-T2AV outperforms dual-branch baselines in lip-sync accuracy, video quality, and audio quality, achieving stronger cross-modal consistency than cascaded pipelines.
AURA: Always-On Understanding and Real-Time Assistance via Video Streams
Apr 05, 2026Video Large Language Models (VideoLLMs) have achieved strong performance on many video understanding tasks, but most existing systems remain offline and are not well-suited for live video streams that require continuous observation and timely response. Recent streaming VideoLLMs have made progress, yet current approaches often rely on decoupled trigger-response pipelines or are limited to captioning-style narration, reducing their effectiveness for open-ended question answering and long-horizon interaction. We propose AURA (Always-On Understanding and Real-Time Assistance), an end-to-end streaming visual interaction framework that enables a unified VideoLLM to continuously process video streams and support both real-time question answering and proactive responses. AURA integrates context management, data construction, training objectives, and deployment optimization for stable long-horizon streaming interaction. It achieves state-of-the-art performance on streaming benchmarks and supports a real-time demo system with ASR and TTS running at 2 FPS on two 80G accelerators. We release the AURA model together with a real-time inference framework to facilitate future research.
PhoStream: Benchmarking Real-World Streaming for Omnimodal Assistants in Mobile Scenarios
Jan 30, 2026Multimodal Large Language Models excel at offline audio-visual understanding, but their ability to serve as mobile assistants in continuous real-world streams remains underexplored. In daily phone use, mobile assistants must track streaming audio-visual inputs and respond at the right time, yet existing benchmarks are often restricted to multiple-choice questions or use shorter videos. In this paper, we introduce PhoStream, the first mobile-centric streaming benchmark that unifies on-screen and off-screen scenarios to evaluate video, audio, and temporal reasoning. PhoStream contains 5,572 open-ended QA pairs from 578 videos across 4 scenarios and 10 capabilities. We build it with an Automated Generative Pipeline backed by rigorous human verification, and evaluate models using a realistic Online Inference Pipeline and LLM-as-a-Judge evaluation for open-ended responses. Experiments reveal a temporal asymmetry in LLM-judged scores (0-100): models perform well on Instant and Backward tasks (Gemini 3 Pro exceeds 80), but drop sharply on Forward tasks (16.40), largely due to early responses before the required visual and audio cues appear. This highlights a fundamental limitation: current MLLMs struggle to decide when to speak, not just what to say. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/PhoStream.
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Oct 10, 2025With the current surge in spatial reasoning explorations, researchers have made significant progress in understanding indoor scenes, but still struggle with diverse applications such as robotics and autonomous driving. This paper aims to advance all-scale spatial reasoning across diverse scenarios by tackling two key challenges: 1) the heavy reliance on indoor 3D scans and labor-intensive manual annotations for dataset curation; 2) the absence of effective all-scale scene modeling, which often leads to overfitting to individual scenes. In this paper, we introduce a holistic solution that integrates a structured spatial reasoning knowledge system, scale-aware modeling, and a progressive training paradigm, as the first attempt to broaden the all-scale spatial intelligence of MLLMs to the best of our knowledge. Using a task-specific, specialist-driven automated pipeline, we curate over 38K video scenes across 5 spatial scales to create SpaceVista-1M, a dataset comprising approximately 1M spatial QA pairs spanning 19 diverse task types. While specialist models can inject useful domain knowledge, they are not reliable for evaluation. We then build an all-scale benchmark with precise annotations by manually recording, retrieving, and assembling video-based data. However, naive training with SpaceVista-1M often yields suboptimal results due to the potential knowledge conflict. Accordingly, we introduce SpaceVista-7B, a spatial reasoning model that accepts dense inputs beyond semantics and uses scale as an anchor for scale-aware experts and progressive rewards. Finally, extensive evaluations across 5 benchmarks, including our SpaceVista-Bench, demonstrate competitive performance, showcasing strong generalization across all scales and scenarios. Our dataset, model, and benchmark will be released on https://peiwensun2000.github.io/mm2km .
OmniAudio: Generating Spatial Audio from 360-Degree Video
Apr 21, 2025


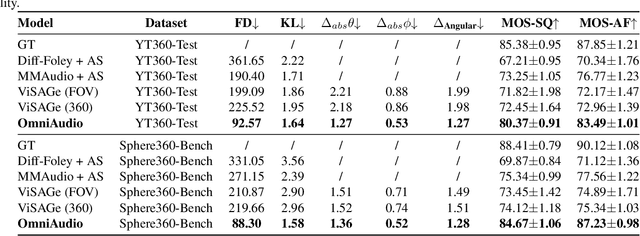
Traditional video-to-audio generation techniques primarily focus on field-of-view (FoV) video and non-spatial audio, often missing the spatial cues necessary for accurately representing sound sources in 3D environments. To address this limitation, we introduce a novel task, 360V2SA, to generate spatial audio from 360-degree videos, specifically producing First-order Ambisonics (FOA) audio - a standard format for representing 3D spatial audio that captures sound directionality and enables realistic 3D audio reproduction. We first create Sphere360, a novel dataset tailored for this task that is curated from real-world data. We also design an efficient semi-automated pipeline for collecting and cleaning paired video-audio data. To generate spatial audio from 360-degree video, we propose a novel framework OmniAudio, which leverages self-supervised pre-training using both spatial audio data (in FOA format) and large-scale non-spatial data. Furthermore, OmniAudio features a dual-branch framework that utilizes both panoramic and FoV video inputs to capture comprehensive local and global information from 360-degree videos. Experimental results demonstrate that OmniAudio achieves state-of-the-art performance across both objective and subjective metrics on Sphere360. Code and datasets will be released at https://github.com/liuhuadai/OmniAudio. The demo page is available at https://OmniAudio-360V2SA.github.io.
Both Ears Wide Open: Towards Language-Driven Spatial Audio Generation
Oct 14, 2024



Recently, diffusion models have achieved great success in mono-channel audio generation. However, when it comes to stereo audio generation, the soundscapes often have a complex scene of multiple objects and directions. Controlling stereo audio with spatial contexts remains challenging due to high data costs and unstable generative models. To the best of our knowledge, this work represents the first attempt to address these issues. We first construct a large-scale, simulation-based, and GPT-assisted dataset, BEWO-1M, with abundant soundscapes and descriptions even including moving and multiple sources. Beyond text modality, we have also acquired a set of images and rationally paired stereo audios through retrieval to advance multimodal generation. Existing audio generation models tend to generate rather random and indistinct spatial audio. To provide accurate guidance for latent diffusion models, we introduce the SpatialSonic model utilizing spatial-aware encoders and azimuth state matrices to reveal reasonable spatial guidance. By leveraging spatial guidance, our unified model not only achieves the objective of generating immersive and controllable spatial audio from text and image but also enables interactive audio generation during inference. Finally, under fair settings, we conduct subjective and objective evaluations on simulated and real-world data to compare our approach with prevailing methods. The results demonstrate the effectiveness of our method, highlighting its capability to generate spatial audio that adheres to physical rules.