 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViEEG: Hierarchical Neural Coding with Cross-Modal Progressive Enhancement for EEG-Based Visual Decoding
May 18, 2025



Understanding and decoding brain activity into visual representations is a fundamental challenge at the intersection of neuroscience and artificial intelligence. While EEG-based visual decoding has shown promise due to its non-invasive, low-cost nature and millisecond-level temporal resolution, existing methods are limited by their reliance on flat neural representations that overlook the brain's inherent visual hierarchy. In this paper, we introduce ViEEG, a biologically inspired hierarchical EEG decoding framework that aligns with the Hubel-Wiesel theory of visual processing. ViEEG decomposes each visual stimulus into three biologically aligned components-contour, foreground object, and contextual scene-serving as anchors for a three-stream EEG encoder. These EEG features are progressively integrated via cross-attention routing, simulating cortical information flow from V1 to IT to the association cortex. We further adopt hierarchical contrastive learning to align EEG representations with CLIP embeddings, enabling zero-shot object recognition. Extensive experiments on the THINGS-EEG dataset demonstrate that ViEEG achieves state-of-the-art performance, with 40.9% Top-1 accuracy in subject-dependent and 22.9% Top-1 accuracy in cross-subject settings, surpassing existing methods by over 45%. Our framework not only advances the performance frontier but also sets a new paradigm for biologically grounded brain decoding in AI.
Directly Forecasting Belief for Reinforcement Learning with Delays
May 01, 2025Reinforcement learning (RL) with delays is challenging as sensory perceptions lag behind the actual events: the RL agent needs to estimate the real state of its environment based on past observations. State-of-the-art (SOTA) methods typically employ recursive, step-by-step forecasting of states. This can cause the accumulation of compounding errors. To tackle this problem, our novel belief estimation method, named Directly Forecasting Belief Transformer (DFBT), directly forecasts states from observations without incrementally estimating intermediate states step-by-step. We theoretically demonstrate that DFBT greatly reduces compounding errors of existing recursively forecasting methods, yielding stronger performance guarantees. In experiments with D4RL offline datasets, DFBT reduces compounding errors with remarkable prediction accuracy. DFBT's capability to forecast state sequences also facilitates multi-step bootstrapping, thus greatly improving learning efficiency. On the MuJoCo benchmark, our DFBT-based method substantially outperforms SOTA baselines.
Breaking the Box: Enhancing Remote Sensing Image Segmentation with Freehand Sketches
Mar 15, 2025This work advances zero-shot interactive segmentation for remote sensing imagery through three key contributions. First, we propose a novel sketch-based prompting method, enabling users to intuitively outline objects, surpassing traditional point or box prompts. Second, we introduce LTL-Sensing, the first dataset pairing human sketches with remote sensing imagery, setting a benchmark for future research. Third, we present LTL-Net, a model featuring a multi-input prompting transport module tailored for freehand sketches. Extensive experiments show our approach significantly improves segmentation accuracy and robustness over state-of-the-art methods like SAM, fostering more intuitive human-AI collaboration in remote sensing analysis and enhancing its applications.
DAST: Difficulty-Aware Self-Training on Large Language Models
Mar 12, 2025Present Large Language Models (LLM) self-training methods always under-sample on challenging queries, leading to inadequate learning on difficult problems which limits LLMs' ability. Therefore, this work proposes a difficulty-aware self-training (DAST) framework that focuses on improving both the quantity and quality of self-generated responses on challenging queries during self-training. DAST is specified in three components: 1) sampling-based difficulty level estimation, 2) difficulty-aware data augmentation, and 3) the self-training algorithm using SFT and DPO respectively. Experiments on mathematical tasks demonstrate the effectiveness and generalization of DAST, highlighting the critical role of difficulty-aware strategies in advancing LLM self-training.
CombatVLA: An Efficient Vision-Language-Action Model for Combat Tasks in 3D Action Role-Playing Games
Mar 12, 2025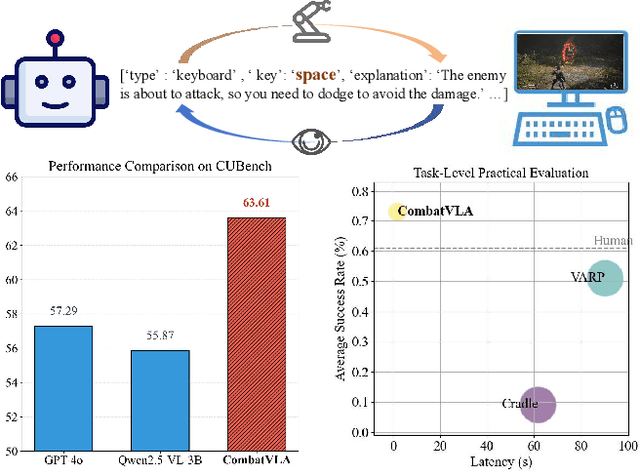
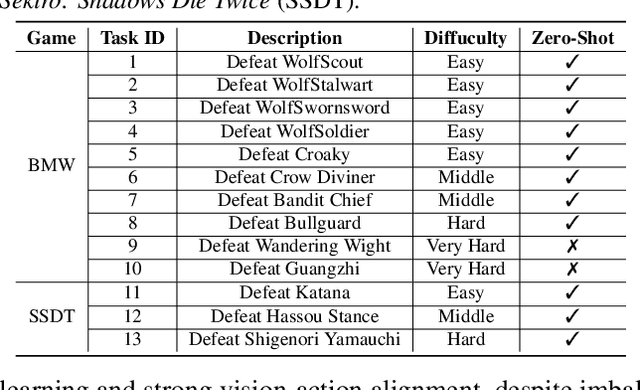
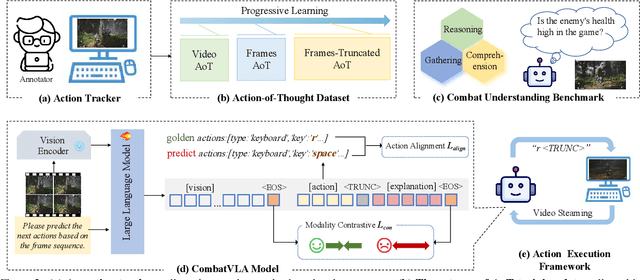
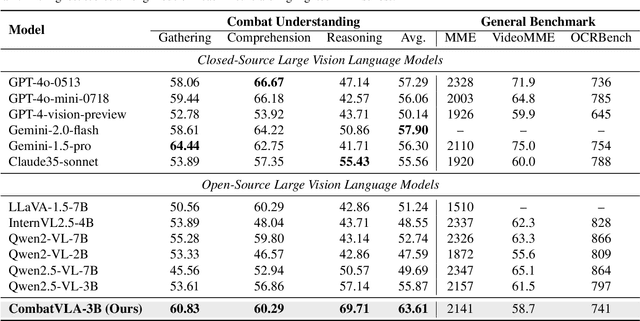
Recent advances in Vision-Language-Action models (VLAs) have expanded the capabilities of embodied intelligence. However, significant challenges remain in real-time decision-making in complex 3D environments, which demand second-level responses, high-resolution perception, and tactical reasoning under dynamic conditions. To advance the field, we introduce CombatVLA, an efficient VLA model optimized for combat tasks in 3D action role-playing games(ARPGs). Specifically, our CombatVLA is a 3B model trained on video-action pairs collected by an action tracker, where the data is formatted as action-of-thought (AoT) sequences. Thereafter, CombatVLA seamlessly integrates into an action execution framework, allowing efficient inference through our truncated AoT strategy. Experimental results demonstrate that CombatVLA not only outperforms all existing models on the combat understanding benchmark but also achieves a 50-fold acceleration in game combat. Moreover, it has a higher task success rate than human players. We will open-source all resources, including the action tracker, dataset, benchmark, model weights, training code, and the implementation of the framework at https://combatvla.github.io/.
DAMM-Diffusion: Learning Divergence-Aware Multi-Modal Diffusion Model for Nanoparticles Distribution Prediction
Mar 12, 2025



The prediction of nanoparticles (NPs) distribution is crucial for the diagnosis and treatment of tumors. Recent studies indicate that the heterogeneity of tumor microenvironment (TME) highly affects the distribution of NPs across tumors. Hence, it has become a research hotspot to generate the NPs distribution by the aid of multi-modal TME components. However, the distribution divergence among multi-modal TME components may cause side effects i.e., the best uni-modal model may outperform the joint generative model. To address the above issues, we propose a \textbf{D}ivergence-\textbf{A}ware \textbf{M}ulti-\textbf{M}odal \textbf{Diffusion} model (i.e., \textbf{DAMM-Diffusion}) to adaptively generate the prediction results from uni-modal and multi-modal branches in a unified network. In detail, the uni-modal branch is composed of the U-Net architecture while the multi-modal branch extends it by introducing two novel fusion modules i.e., Multi-Modal Fusion Module (MMFM) and Uncertainty-Aware Fusion Module (UAFM). Specifically, the MMFM is proposed to fuse features from multiple modalities, while the UAFM module is introduced to learn the uncertainty map for cross-attention computation. Following the individual prediction results from each branch, the Divergence-Aware Multi-Modal Predictor (DAMMP) module is proposed to assess the consistency of multi-modal data with the uncertainty map, which determines whether the final prediction results come from multi-modal or uni-modal predictions. We predict the NPs distribution given the TME components of tumor vessels and cell nuclei, and the experimental results show that DAMM-Diffusion can generate the distribution of NPs with higher accuracy than the comparing methods. Additional results on the multi-modal brain image synthesis task further validate the effectiveness of the proposed method.
When Large Vision-Language Model Meets Large Remote Sensing Imagery: Coarse-to-Fine Text-Guided Token Pruning
Mar 10, 2025Efficient vision-language understanding of large Remote Sensing Images (RSIs) is meaningful but challenging. Current Large Vision-Language Models (LVLMs) typically employ limited pre-defined grids to process images, leading to information loss when handling gigapixel RSIs. Conversely, using unlimited grids significantly increases computational costs. To preserve image details while reducing computational complexity, we propose a text-guided token pruning method with Dynamic Image Pyramid (DIP) integration. Our method introduces: (i) a Region Focus Module (RFM) that leverages text-aware region localization capability to identify critical vision tokens, and (ii) a coarse-to-fine image tile selection and vision token pruning strategy based on DIP, which is guided by RFM outputs and avoids directly processing the entire large imagery. Additionally, existing benchmarks for evaluating LVLMs' perception ability on large RSI suffer from limited question diversity and constrained image sizes. We construct a new benchmark named LRS-VQA, which contains 7,333 QA pairs across 8 categories, with image length up to 27,328 pixels. Our method outperforms existing high-resolution strategies on four datasets using the same data. Moreover, compared to existing token reduction methods, our approach demonstrates higher efficiency under high-resolution settings. Dataset and code are in https://github.com/VisionXLab/LRS-VQA.
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Feb 24, 2025In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM\'s dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
HybGRAG: Hybrid Retrieval-Augmented Generation on Textual and Relational Knowledge Bases
Dec 20, 2024



Given a semi-structured knowledge base (SKB), where text documents are interconnected by relations, how can we effectively retrieve relevant information to answer user questions? Retrieval-Augmented Generation (RAG) retrieves documents to assist large language models (LLMs) in question answering; while Graph RAG (GRAG) uses structured knowledge bases as its knowledge source. However, many questions require both textual and relational information from SKB - referred to as "hybrid" questions - which complicates the retrieval process and underscores the need for a hybrid retrieval method that leverages both information. In this paper, through our empirical analysis, we identify key insights that show why existing methods may struggle with hybrid question answering (HQA) over SKB. Based on these insights, we propose HybGRAG for HQA consisting of a retriever bank and a critic module, with the following advantages: (1) Agentic, it automatically refines the output by incorporating feedback from the critic module, (2) Adaptive, it solves hybrid questions requiring both textual and relational information with the retriever bank, (3) Interpretable, it justifies decision making with intuitive refinement path, and (4) Effective, it surpasses all baselines on HQA benchmarks. In experiments on the STaRK benchmark, HybGRAG achieves significant performance gains, with an average relative improvement in Hit@1 of 51%.
UAlign: Leveraging Uncertainty Estimations for Factuality Alignment on Large Language Models
Dec 16, 2024



Despite demonstrating impressive capabilities, Large Language Models (LLMs) still often struggle to accurately express the factual knowledge they possess, especially in cases where the LLMs' knowledge boundaries are ambiguous. To improve LLMs' factual expressions, we propose the UAlign framework, which leverages Uncertainty estimations to represent knowledge boundaries, and then explicitly incorporates these representations as input features into prompts for LLMs to Align with factual knowledge. First, we prepare the dataset on knowledge question-answering (QA) samples by calculating two uncertainty estimations, including confidence score and semantic entropy, to represent the knowledge boundaries for LLMs. Subsequently, using the prepared dataset, we train a reward model that incorporates uncertainty estimations and then employ the Proximal Policy Optimization (PPO) algorithm for factuality alignment on LLMs. Experimental results indicate that, by integrating uncertainty representations in LLM alignment, the proposed UAlign can significantly enhance the LLMs' capacities to confidently answer known questions and refuse unknown questions on both in-domain and out-of-domain tasks, showing reliability improvements and good generalizability over various prompt- and training-based baselines.