 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken DialogSum: An Emotion-Rich Conversational Dataset for Spoken Dialogue Summarization
Dec 17, 2025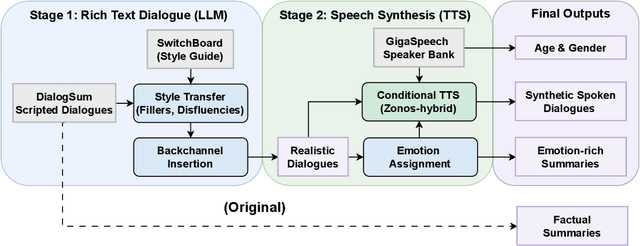

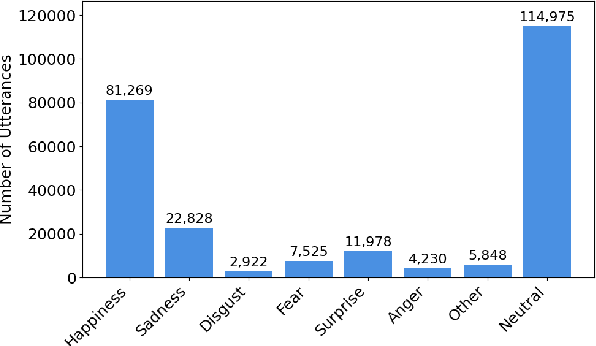
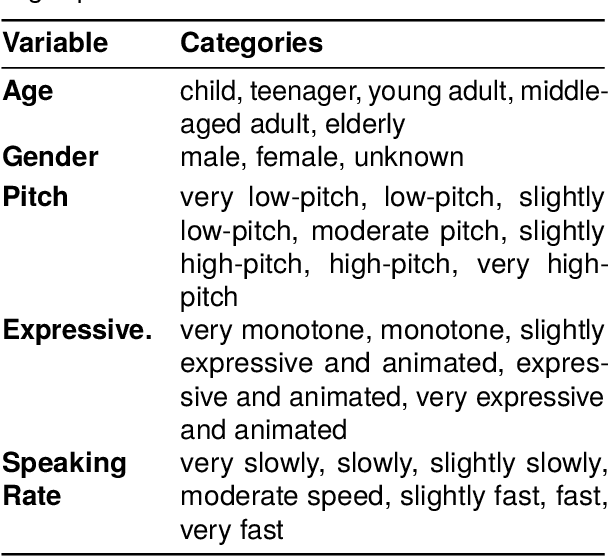
Recent audio language models can follow long conversations. However, research on emotion-aware or spoken dialogue summarization is constrained by the lack of data that links speech, summaries, and paralinguistic cues. We introduce Spoken DialogSum, the first corpus aligning raw conversational audio with factual summaries, emotion-rich summaries, and utterance-level labels for speaker age, gender, and emotion. The dataset is built in two stages: first, an LLM rewrites DialogSum scripts with Switchboard-style fillers and back-channels, then tags each utterance with emotion, pitch, and speaking rate. Second, an expressive TTS engine synthesizes speech from the tagged scripts, aligned with paralinguistic labels. Spoken DialogSum comprises 13,460 emotion-diverse dialogues, each paired with both a factual and an emotion-focused summary. We release an online demo at https://fatfat-emosum.github.io/EmoDialog-Sum-Audio-Samples/, with plans to release the full dataset in the near future. Baselines show that an Audio-LLM raises emotional-summary ROUGE-L by 28% relative to a cascaded ASR-LLM system, confirming the value of end-to-end speech modeling.
Enhancing Dialogue Annotation with Speaker Characteristics Leveraging a Frozen LLM
Aug 06, 2025In dialogue transcription pipelines, Large Language Models (LLMs) are frequently employed in post-processing to improve grammar, punctuation, and readability. We explore a complementary post-processing step: enriching transcribed dialogues by adding metadata tags for speaker characteristics such as age, gender, and emotion. Some of the tags are global to the entire dialogue, while some are time-variant. Our approach couples frozen audio foundation models, such as Whisper or WavLM, with a frozen LLAMA language model to infer these speaker attributes, without requiring task-specific fine-tuning of either model. Using lightweight, efficient connectors to bridge audio and language representations, we achieve competitive performance on speaker profiling tasks while preserving modularity and speed. Additionally, we demonstrate that a frozen LLAMA model can compare x-vectors directly, achieving an Equal Error Rate of 8.8% in some scenarios.
Mutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Feb 24, 2025In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM\'s dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
CA-SSLR: Condition-Aware Self-Supervised Learning Representation for Generalized Speech Processing
Dec 05, 2024We introduce Condition-Aware Self-Supervised Learning Representation (CA-SSLR), a generalist conditioning model broadly applicable to various speech-processing tasks. Compared to standard fine-tuning methods that optimize for downstream models, CA-SSLR integrates language and speaker embeddings from earlier layers, making the SSL model aware of the current language and speaker context. This approach reduces the reliance on input audio features while preserving the integrity of the base SSLR. CA-SSLR improves the model's capabilities and demonstrates its generality on unseen tasks with minimal task-specific tuning. Our method employs linear modulation to dynamically adjust internal representations, enabling fine-grained adaptability without significantly altering the original model behavior. Experiments show that CA-SSLR reduces the number of trainable parameters, mitigates overfitting, and excels in under-resourced and unseen tasks. Specifically, CA-SSLR achieves a 10% relative reduction in LID errors, a 37% improvement in ASR CER on the ML-SUPERB benchmark, and a 27% decrease in SV EER on VoxCeleb-1, demonstrating its effectiveness.
SoloAudio: Target Sound Extraction with Language-oriented Audio Diffusion Transformer
Sep 12, 2024In this paper, we introduce SoloAudio, a novel diffusion-based generative model for target sound extraction (TSE). Our approach trains latent diffusion models on audio, replacing the previous U-Net backbone with a skip-connected Transformer that operates on latent features. SoloAudio supports both audio-oriented and language-oriented TSE by utilizing a CLAP model as the feature extractor for target sounds. Furthermore, SoloAudio leverages synthetic audio generated by state-of-the-art text-to-audio models for training, demonstrating strong generalization to out-of-domain data and unseen sound events. We evaluate this approach on the FSD Kaggle 2018 mixture dataset and real data from AudioSet, where SoloAudio achieves the state-of-the-art results on both in-domain and out-of-domain data, and exhibits impressive zero-shot and few-shot capabilities. Source code and demos are released.
ESPnet-SE++: Speech Enhancement for Robust Speech Recognition, Translation, and Understanding
Jul 19, 2022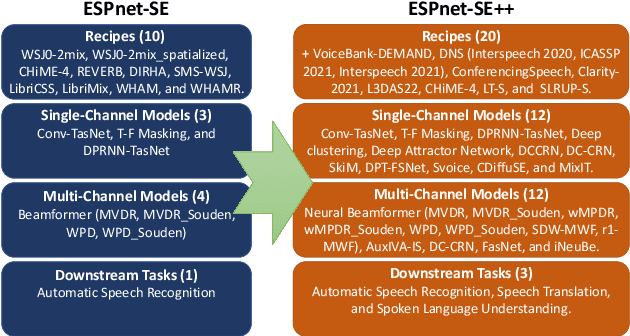
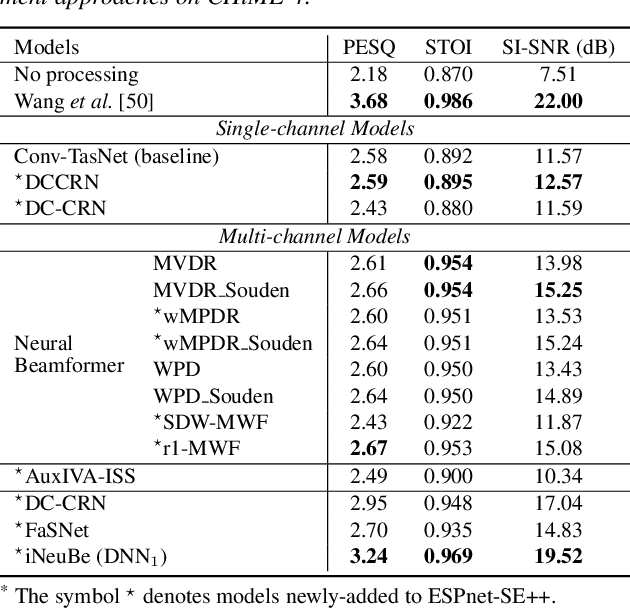
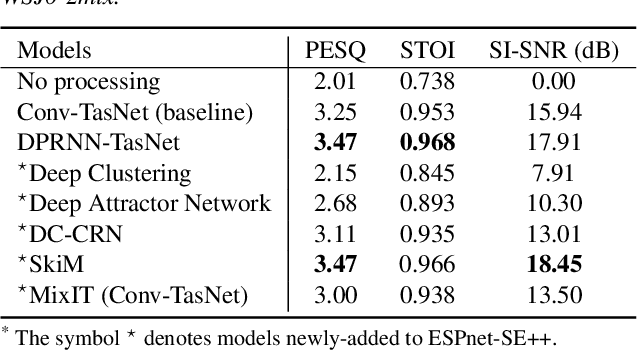
This paper presents recent progress on integrating speech separation and enhancement (SSE) into the ESPnet toolkit. Compared with the previous ESPnet-SE work, numerous features have been added, including recent state-of-the-art speech enhancement models with their respective training and evaluation recipes. Importantly, a new interface has been designed to flexibly combine speech enhancement front-ends with other tasks, including automatic speech recognition (ASR), speech translation (ST), and spoken language understanding (SLU). To showcase such integration, we performed experiments on carefully designed synthetic datasets for noisy-reverberant multi-channel ST and SLU tasks, which can be used as benchmark corpora for future research. In addition to these new tasks, we also use CHiME-4 and WSJ0-2Mix to benchmark multi- and single-channel SE approaches. Results show that the integration of SE front-ends with back-end tasks is a promising research direction even for tasks besides ASR, especially in the multi-channel scenario. The code is available online at https://github.com/ESPnet/ESPnet. The multi-channel ST and SLU datasets, which are another contribution of this work, are released on HuggingFace.
Towards Low-distortion Multi-channel Speech Enhancement: The ESPNet-SE Submission to The L3DAS22 Challenge
Feb 24, 2022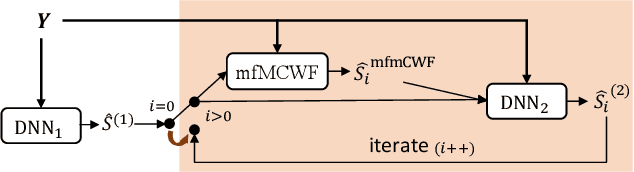
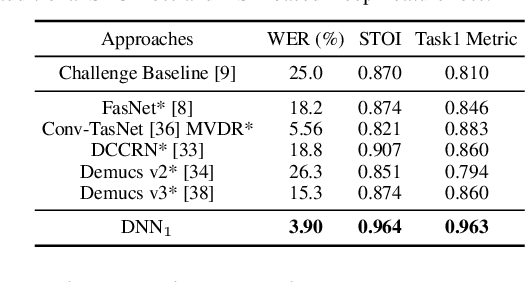
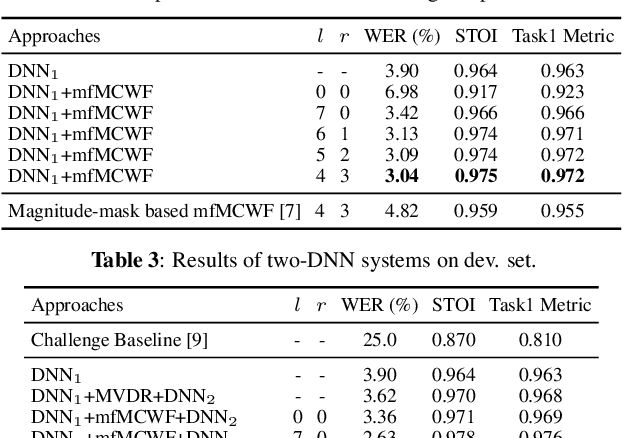
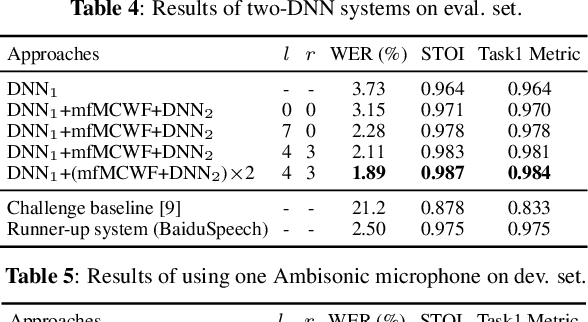
This paper describes our submission to the L3DAS22 Challenge Task 1, which consists of speech enhancement with 3D Ambisonic microphones. The core of our approach combines Deep Neural Network (DNN) driven complex spectral mapping with linear beamformers such as the multi-frame multi-channel Wiener filter. Our proposed system has two DNNs and a linear beamformer in between. Both DNNs are trained to perform complex spectral mapping, using a combination of waveform and magnitude spectrum losses. The estimated signal from the first DNN is used to drive a linear beamformer, and the beamforming result, together with this enhanced signal, are used as extra inputs for the second DNN which refines the estimation. Then, from this new estimated signal, the linear beamformer and second DNN are run iteratively. The proposed method was ranked first in the challenge, achieving, on the evaluation set, a ranking metric of 0.984, versus 0.833 of the challenge baseline.
Conditional Diffusion Probabilistic Model for Speech Enhancement
Feb 10, 2022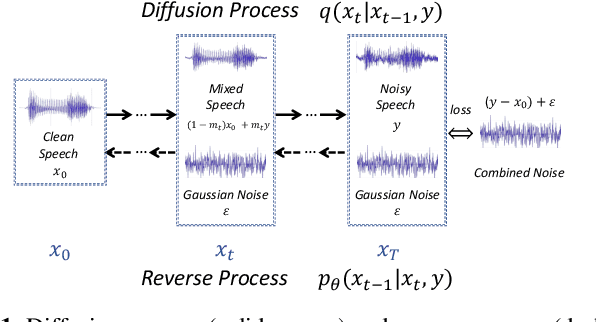
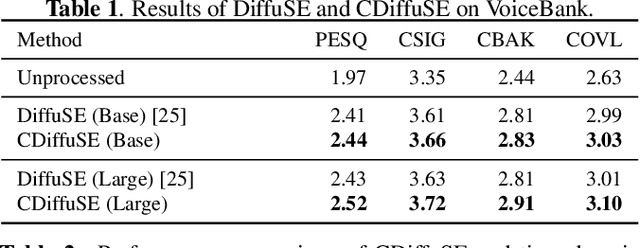
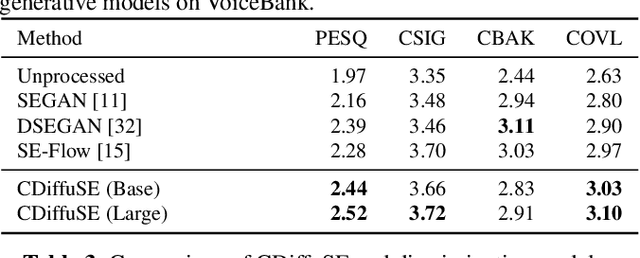
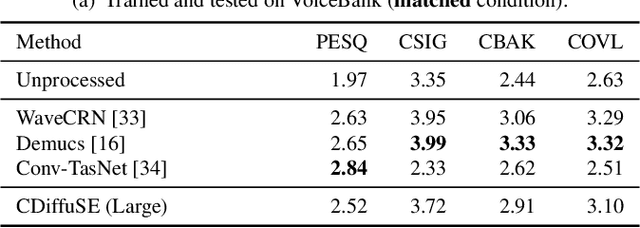
Speech enhancement is a critical component of many user-oriented audio applications, yet current systems still suffer from distorted and unnatural outputs. While generative models have shown strong potential in speech synthesis, they are still lagging behind in speech enhancement. This work leverages recent advances in diffusion probabilistic models, and proposes a novel speech enhancement algorithm that incorporates characteristics of the observed noisy speech signal into the diffusion and reverse processes. More specifically, we propose a generalized formulation of the diffusion probabilistic model named conditional diffusion probabilistic model that, in its reverse process, can adapt to non-Gaussian real noises in the estimated speech signal. In our experiments, we demonstrate strong performance of the proposed approach compared to representative generative models, and investigate the generalization capability of our models to other datasets with noise characteristics unseen during training.
Discretization and Re-synthesis: an alternative method to solve the Cocktail Party Problem
Jan 09, 2022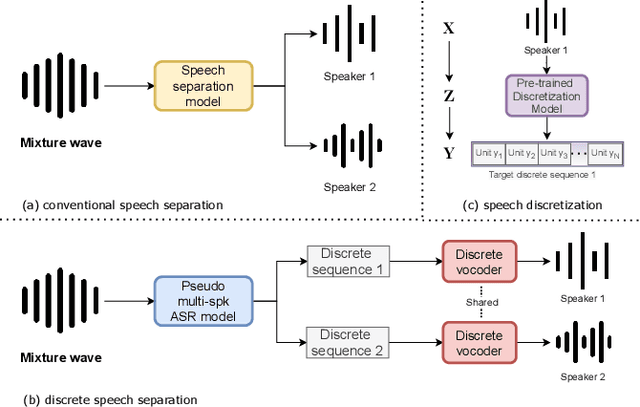

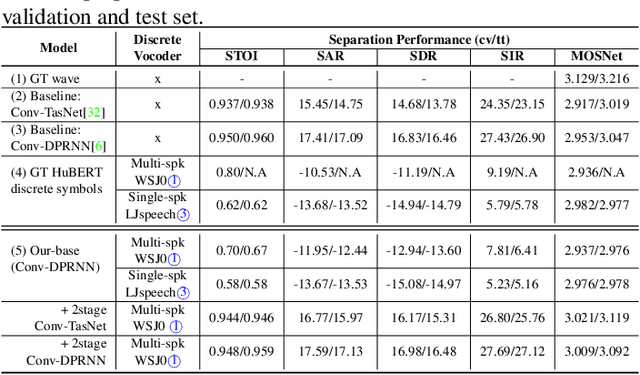
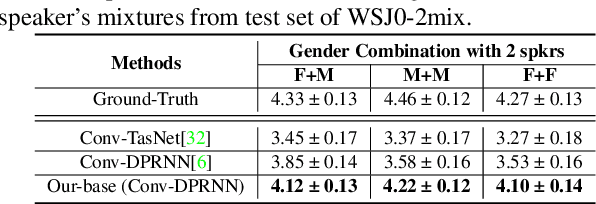
Deep learning based models have significantly improved the performance of speech separation with input mixtures like the cocktail party. Prominent methods (e.g., frequency-domain and time-domain speech separation) usually build regression models to predict the ground-truth speech from the mixture, using the masking-based design and the signal-level loss criterion (e.g., MSE or SI-SNR). This study demonstrates, for the first time, that the synthesis-based approach can also perform well on this problem, with great flexibility and strong potential. Specifically, we propose a novel speech separation/enhancement model based on the recognition of discrete symbols, and convert the paradigm of the speech separation/enhancement related tasks from regression to classification. By utilizing the synthesis model with the input of discrete symbols, after the prediction of discrete symbol sequence, each target speech could be re-synthesized. Evaluation results based on the WSJ0-2mix and VCTK-noisy corpora in various settings show that our proposed method can steadily synthesize the separated speech with high speech quality and without any interference, which is difficult to avoid in regression-based methods. In addition, with negligible loss of listening quality, the speaker conversion of enhanced/separated speech could be easily realized through our method.
An Exploration of Self-Supervised Pretrained Representations for End-to-End Speech Recognition
Oct 09, 2021
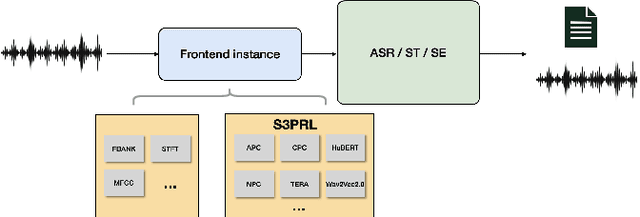
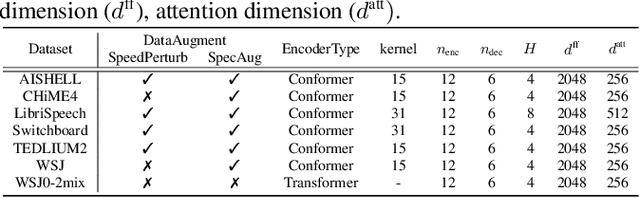
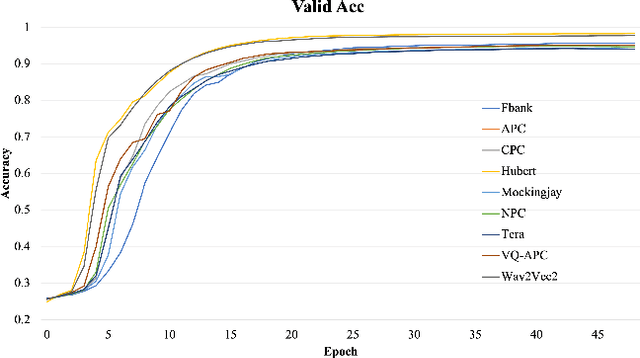
Self-supervised pretraining on speech data has achieved a lot of progress. High-fidelity representation of the speech signal is learned from a lot of untranscribed data and shows promising performance. Recently, there are several works focusing on evaluating the quality of self-supervised pretrained representations on various tasks without domain restriction, e.g. SUPERB. However, such evaluations do not provide a comprehensive comparison among many ASR benchmark corpora. In this paper, we focus on the general applications of pretrained speech representations, on advanced end-to-end automatic speech recognition (E2E-ASR) models. We select several pretrained speech representations and present the experimental results on various open-source and publicly available corpora for E2E-ASR. Without any modification of the back-end model architectures or training strategy, some of the experiments with pretrained representations, e.g., WSJ, WSJ0-2mix with HuBERT, reach or outperform current state-of-the-art (SOTA) recognition performance. Moreover, we further explore more scenarios for whether the pretraining representations are effective, such as the cross-language or overlapped speech. The scripts, configuratons and the trained models have been released in ESPnet to let the community reproduce our experiments and improve them.