 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Reinforcement of LLM Dialogue Synthesis and Summarization Capabilities for Few-Shot Dialogue Summarization
Feb 24, 2025In this work, we propose Mutual Reinforcing Data Synthesis (MRDS) within LLMs to improve few-shot dialogue summarization task. Unlike prior methods that require external knowledge, we mutually reinforce the LLM\'s dialogue synthesis and summarization capabilities, allowing them to complement each other during training and enhance overall performances. The dialogue synthesis capability is enhanced by directed preference optimization with preference scoring from summarization capability. The summarization capability is enhanced by the additional high quality dialogue-summary paired data produced by the dialogue synthesis capability. By leveraging the proposed MRDS mechanism, we elicit the internal knowledge of LLM in the format of synthetic data, and use it to augment the few-shot real training dataset. Empirical results demonstrate that our method improves dialogue summarization, achieving a 1.5% increase in ROUGE scores and a 0.3% improvement in BERT scores in few-shot settings. Furthermore, our method attains the highest average scores in human evaluations, surpassing both the pre-trained models and the baselines fine-tuned solely for summarization tasks.
SAT: Data-light Uncertainty Set Merging via Synthetics, Aggregation, and Test Inversion
Oct 16, 2024



The integration of uncertainty sets has diverse applications but also presents challenges, particularly when only initial sets and their control levels are available, along with potential dependencies. Examples include merging confidence sets from different distributed sites with communication constraints, as well as combining conformal prediction sets generated by different learning algorithms or data splits. In this article, we introduce an efficient and flexible Synthetic, Aggregation, and Test inversion (SAT) approach to merge various potentially dependent uncertainty sets into a single set. The proposed method constructs a novel class of synthetic test statistics, aggregates them, and then derives merged sets through test inversion. Our approach leverages the duality between set estimation and hypothesis testing, ensuring reliable coverage in dependent scenarios. The procedure is data-light, meaning it relies solely on initial sets and control levels without requiring raw data, and it adapts to any user-specified initial uncertainty sets, accommodating potentially varying coverage levels. Theoretical analyses and numerical experiments confirm that SAT provides finite-sample coverage guarantees and achieves small set sizes.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Alteration Detection of Tensor Dependence Structure via Sparsity-Exploited Reranking Algorithm
Oct 13, 2023Tensor-valued data arise frequently from a wide variety of scientific applications, and many among them can be translated into an alteration detection problem of tensor dependence structures. In this article, we formulate the problem under the popularly adopted tensor-normal distributions and aim at two-sample correlation/partial correlation comparisons of tensor-valued observations. Through decorrelation and centralization, a separable covariance structure is employed to pool sample information from different tensor modes to enhance the power of the test. Additionally, we propose a novel Sparsity-Exploited Reranking Algorithm (SERA) to further improve the multiple testing efficiency. The algorithm is approached through reranking of the p-values derived from the primary test statistics, by incorporating a carefully constructed auxiliary tensor sequence. Besides the tensor framework, SERA is also generally applicable to a wide range of two-sample large-scale inference problems with sparsity structures, and is of independent interest. The asymptotic properties of the proposed test are derived and the algorithm is shown to control the false discovery at the pre-specified level. We demonstrate the efficacy of the proposed method through intensive simulations and two scientific applications.
Locally Adaptive Transfer Learning Algorithms for Large-Scale Multiple Testing
Mar 25, 2022


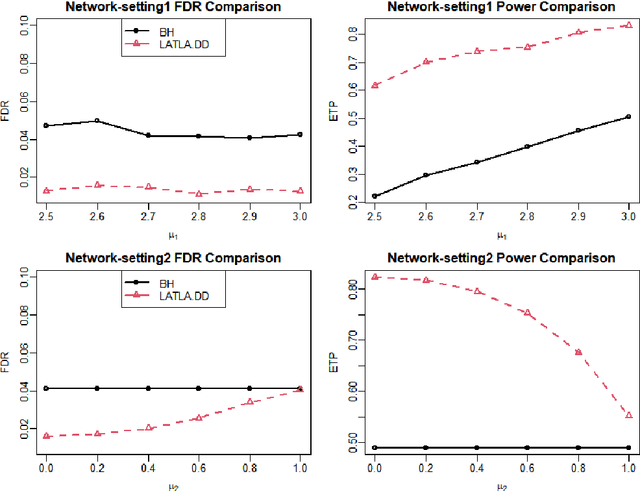
Transfer learning has enjoyed increasing popularity in a range of big data applications. In the context of large-scale multiple testing, the goal is to extract and transfer knowledge learned from related source domains to improve the accuracy of simultaneously testing of a large number of hypotheses in the target domain. This article develops a locally adaptive transfer learning algorithm (LATLA) for transfer learning for multiple testing. In contrast with existing covariate-assisted multiple testing methods that require the auxiliary covariates to be collected alongside the primary data on the same testing units, LATLA provides a principled and generic transfer learning framework that is capable of incorporating multiple samples of auxiliary data from related source domains, possibly in different dimensions/structures and from diverse populations. Both the theoretical and numerical results show that LATLA controls the false discovery rate and outperforms existing methods in power. LATLA is illustrated through an application to genome-wide association studies for the identification of disease-associated SNPs by cross-utilizing the auxiliary data from a related linkage analysis.
Fictitious GAN: Training GANs with Historical Models
Jul 11, 2018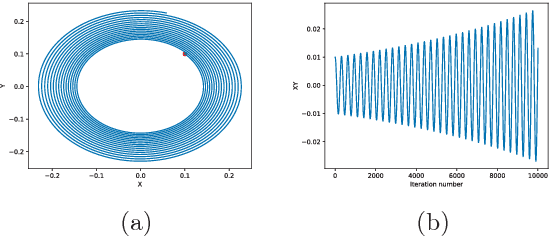

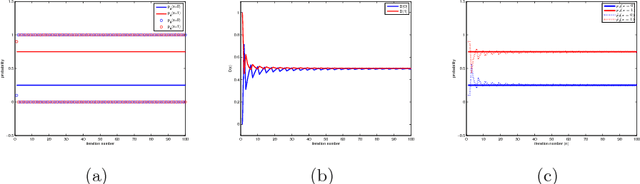

Generative adversarial networks (GANs) are powerful tools for learning generative models. In practice, the training may suffer from lack of convergence. GANs are commonly viewed as a two-player zero-sum game between two neural networks. Here, we leverage this game theoretic view to study the convergence behavior of the training process. Inspired by the fictitious play learning process, a novel training method, referred to as Fictitious GAN, is introduced. Fictitious GAN trains the deep neural networks using a mixture of historical models. Specifically, the discriminator (resp. generator) is updated according to the best-response to the mixture outputs from a sequence of previously trained generators (resp. discriminators). It is shown that Fictitious GAN can effectively resolve some convergence issues that cannot be resolved by the standard training approach. It is proved that asymptotically the average of the generator outputs has the same distribution as the data samples.
Cross-view Action Modeling, Learning and Recognition
May 12, 2014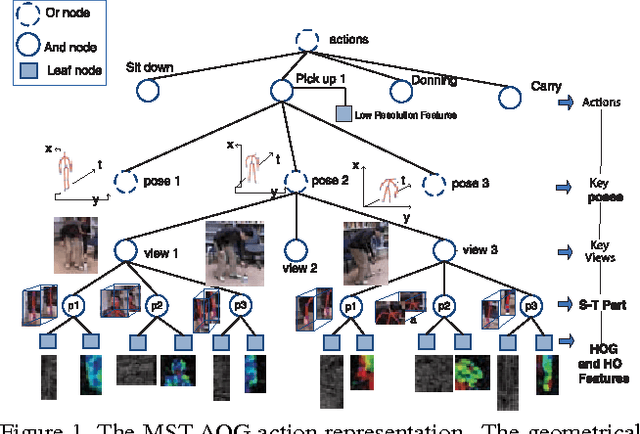
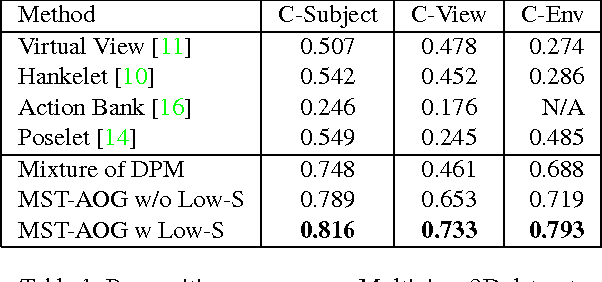
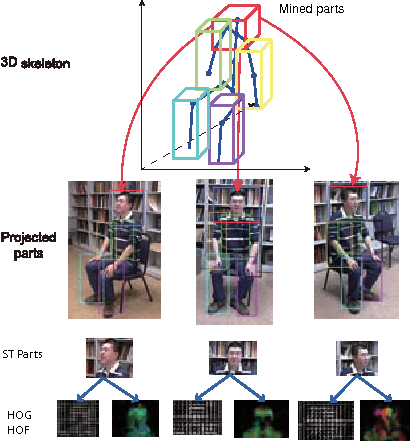

Existing methods on video-based action recognition are generally view-dependent, i.e., performing recognition from the same views seen in the training data. We present a novel multiview spatio-temporal AND-OR graph (MST-AOG) representation for cross-view action recognition, i.e., the recognition is performed on the video from an unknown and unseen view. As a compositional model, MST-AOG compactly represents the hierarchical combinatorial structures of cross-view actions by explicitly modeling the geometry, appearance and motion variations. This paper proposes effective methods to learn the structure and parameters of MST-AOG. The inference based on MST-AOG enables action recognition from novel views. The training of MST-AOG takes advantage of the 3D human skeleton data obtained from Kinect cameras to avoid annotating enormous multi-view video frames, which is error-prone and time-consuming, but the recognition does not need 3D information and is based on 2D video input. A new Multiview Action3D dataset has been created and will be released. Extensive experiments have demonstrated that this new action representation significantly improves the accuracy and robustness for cross-view action recognition on 2D videos.