 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Security Auditing and Robustness Enhancement for Untrusted Agent Skills
Apr 28, 2026Agent Skills package SKILL.md files, scripts, reference documents, and repository context into reusable capability units, turning pre-load auditing from single-prompt filtering into cross-file security review. Existing guardrails often flag risk but recover malicious intent inconsistently under semantics-preserving rewrites. This paper formulates pre-load auditing for untrusted Agent Skills as a robust three-way classification task and introduces SkillGuard-Robust, which combines role-aware evidence extraction, selective semantic verification, and consistency-preserving adjudication. We evaluate SkillGuard-Robust on SkillGuardBench and two public-ecosystem extensions through five large evaluation views ranging from 254 to 404 packages. On the 404-package held-out aggregate, SkillGuard-Robust reaches 97.30% overall exact match, 98.33% malicious-risk recall, and 98.89% attack exact consistency. On the 254-package external-ecosystem view, it reaches 99.66%, 100.00%, and 100.00%, respectively. These results support a bounded conclusion: factorized package auditing materially improves frozen and public-ecosystem robustness, while harsher external-source transfer remains an open challenge.
Feature-Label Modal Alignment for Robust Partial Multi-Label Learning
Apr 10, 2026In partial multi-label learning (PML), each instance is associated with a set of candidate labels containing both ground-truth and noisy labels. The presence of noisy labels disrupts the correspondence between features and labels, degrading classification performance. To address this challenge, we propose a novel PML method based on feature-label modal alignment (PML-MA), which treats features and labels as two complementary modalities and restores their consistency through systematic alignment. Specifically, PML-MA first employs low-rank orthogonal decomposition to generate pseudo-labels that approximate the true label distribution by filtering noisy labels. It then aligns features and pseudo-labels through both global projection into a common subspace and local preservation of neighborhood structures. Finally, a multi-peak class prototype learning mechanism leverages the multi-label nature where instances simultaneously belong to multiple categories, using pseudo-labels as soft membership weights to enhance discriminability. By integrating modal alignment with prototype-guided refinement, PML-MA ensures pseudo-labels better reflect the true distribution while maintaining robustness against label noise. Extensive experiments on both real-world and synthetic datasets demonstrate that PML-MA significantly outperforms state-of-the-art methods, achieving superior classification accuracy and noise robustness.
SEHFS: Structural Entropy-Guided High-Order Correlation Learning for Multi-View Multi-Label Feature Selection
Mar 03, 2026In recent years, multi-view multi-label learning (MVML) has attracted extensive attention due to its close alignment to real-world scenarios. Information-theoretic methods have gained prominence for learning nonlinear correlations. However, two key challenges persist: first, features in real-world data commonly exhibit high-order structural correlations, but existing information-theoretic methods struggle to learn such correlations; second, commonly relying on heuristic optimization, information-theoretic methods are prone to converging to local optima. To address these two challenges, we propose a novel method called Structural Entropy Guided High-Order Correlation Learning for Multi-View Multi-Label Feature Selection (SEHFS). The core idea of SEHFS is to convert the feature graph into a structural-entropy-minimizing encoding tree, quantifying the information cost of high-order dependencies and thus learning high-order feature correlations beyond pairwise correlations. Specifically, features exhibiting strong high-order redundancy are grouped into a single cluster within the encoding tree, while inter-cluster feaeture correlations are minimized, thereby eliminating redundancy both within and across clusters. Furthermore, a new framework based on the fusion of information theory and matrix methods is adopted, which learns a shared semantic matrix and view-specific contribution matrices to reconstruct a global view matrix, thereby enhancing the information-theoretic method and balancing the global and local optimization. The ability of structural entropy to learn high-order correlations is theoretically established, and and both experiments on eight datasets from various domains and ablation studies demonstrate that SEHFS achieves superior performance in feature selection.
Prompt Tuning for CLIP on the Pretrained Manifold
Feb 22, 2026Prompt tuning introduces learnable prompt vectors that adapt pretrained vision-language models to downstream tasks in a parameter-efficient manner. However, under limited supervision, prompt tuning alters pretrained representations and drives downstream features away from the pretrained manifold toward directions that are unfavorable for transfer. This drift degrades generalization. To address this limitation, we propose ManiPT, a framework that performs prompt tuning on the pretrained manifold. ManiPT introduces cosine consistency constraints in both the text and image modalities to confine the learned representations within the pretrained geometric neighborhood. Furthermore, we introduce a structural bias that enforces incremental corrections, guiding the adaptation along transferable directions to mitigate reliance on shortcut learning. From a theoretical perspective, ManiPT alleviates overfitting tendencies under limited data. Our experiments cover four downstream settings: unseen-class generalization, few-shot classification, cross-dataset transfer, and domain generalization. Across these settings, ManiPT achieves higher average performance than baseline methods. Notably, ManiPT provides an explicit perspective on how prompt tuning overfits under limited supervision.
Q-Hawkeye: Reliable Visual Policy Optimization for Image Quality Assessment
Jan 30, 2026Image Quality Assessment (IQA) predicts perceptual quality scores consistent with human judgments. Recent RL-based IQA methods built on MLLMs focus on generating visual quality descriptions and scores, ignoring two key reliability limitations: (i) although the model's prediction stability varies significantly across training samples, existing GRPO-based methods apply uniform advantage weighting, thereby amplifying noisy signals from unstable samples in gradient updates; (ii) most works emphasize text-grounded reasoning over images while overlooking the model's visual perception ability of image content. In this paper, we propose Q-Hawkeye, an RL-based reliable visual policy optimization framework that redesigns the learning signal through unified Uncertainty-Aware Dynamic Optimization and Perception-Aware Optimization. Q-Hawkeye estimates predictive uncertainty using the variance of predicted scores across multiple rollouts and leverages this uncertainty to reweight each sample's update strength, stabilizing policy optimization. To strengthen perceptual reliability, we construct paired inputs of degraded images and their original images and introduce an Implicit Perception Loss that constrains the model to ground its quality judgments in genuine visual evidence. Extensive experiments demonstrate that Q-Hawkeye outperforms state-of-the-art methods and generalizes better across multiple datasets. The code and models will be made available.
Advancing Adaptive Multi-Stage Video Anomaly Reasoning: A Benchmark Dataset and Method
Jan 15, 2026Recent progress in reasoning capabilities of Multimodal Large Language Models(MLLMs) has highlighted their potential for performing complex video understanding tasks. However, in the domain of Video Anomaly Detection and Understanding (VAD&U), existing MLLM-based methods are largely limited to anomaly localization or post-hoc description, lacking explicit reasoning processes, risk awareness, and decision-oriented interpretation. To address this gap, we define a new task termed Video Anomaly Reasoning (VAR), which elevates video anomaly analysis from descriptive understanding to structured, multi-stage reasoning. VAR explicitly requires models to perform progressive reasoning over anomalous events before answering anomaly-related questions, encompassing visual perception, causal interpretation, and risk-aware decision making. To support this task, we present a new dataset with 8,641 videos, where each video is annotated with diverse question types corresponding to different reasoning depths, totaling more than 50,000 samples, making it one of the largest datasets for video anomaly. The annotations are based on a structured Perception-Cognition-Action Chain-of-Thought (PerCoAct-CoT), which formalizes domain-specific reasoning priors for video anomaly understanding. This design enables systematic evaluation of multi-stage and adaptive anomaly reasoning. In addition, we propose Anomaly-Aware Group Relative Policy Optimization to further enhance reasoning reliability under weak supervision. Building upon the proposed task and dataset, we develop an end-to-end MLLM-based VAR model termed Vad-R1-Plus, which supports adaptive hierarchical reasoning and risk-aware decision making. Extensive experiments demonstrate that the proposed benchmark and method effectively advance the reasoning capabilities of MLLMs on VAR tasks, outperforming both open-source and proprietary baselines.
Diffusion Model Regularized Implicit Neural Representation for CT Metal Artifact Reduction
Dec 09, 2025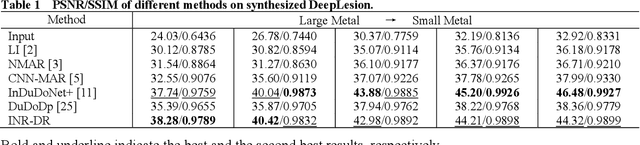
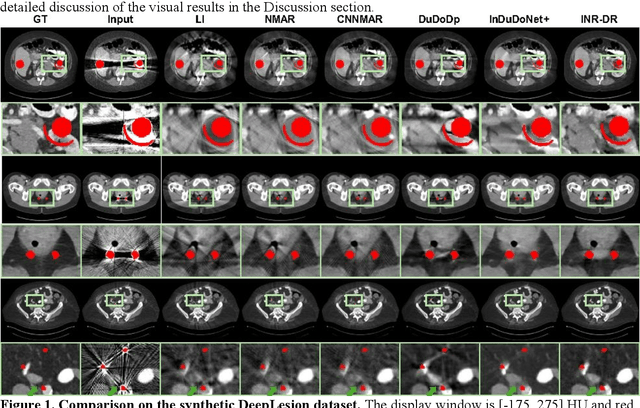
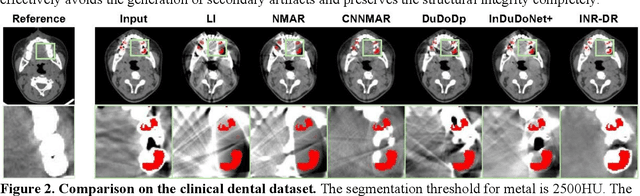

Computed tomography (CT) images are often severely corrupted by artifacts in the presence of metals. Existing supervised metal artifact reduction (MAR) approaches suffer from performance instability on known data due to their reliance on limited paired metal-clean data, which limits their clinical applicability. Moreover, existing unsupervised methods face two main challenges: 1) the CT physical geometry is not effectively incorporated into the MAR process to ensure data fidelity; 2) traditional heuristics regularization terms cannot fully capture the abundant prior knowledge available. To overcome these shortcomings, we propose diffusion model regularized implicit neural representation framework for MAR. The implicit neural representation integrates physical constraints and imposes data fidelity, while the pre-trained diffusion model provides prior knowledge to regularize the solution. Experimental results on both simulated and clinical data demonstrate the effectiveness and generalization ability of our method, highlighting its potential to be applied to clinical settings.
Enhancing Multimodal Protein Function Prediction Through Dual-Branch Dynamic Selection with Reconstructive Pre-Training
Nov 06, 2025Multimodal protein features play a crucial role in protein function prediction. However, these features encompass a wide range of information, ranging from structural data and sequence features to protein attributes and interaction networks, making it challenging to decipher their complex interconnections. In this work, we propose a multimodal protein function prediction method (DSRPGO) by utilizing dynamic selection and reconstructive pre-training mechanisms. To acquire complex protein information, we introduce reconstructive pre-training to mine more fine-grained information with low semantic levels. Moreover, we put forward the Bidirectional Interaction Module (BInM) to facilitate interactive learning among multimodal features. Additionally, to address the difficulty of hierarchical multi-label classification in this task, a Dynamic Selection Module (DSM) is designed to select the feature representation that is most conducive to current protein function prediction. Our proposed DSRPGO model improves significantly in BPO, MFO, and CCO on human datasets, thereby outperforming other benchmark models.
PVNet: Point-Voxel Interaction LiDAR Scene Upsampling Via Diffusion Models
Aug 23, 2025Accurate 3D scene understanding in outdoor environments heavily relies on high-quality point clouds. However, LiDAR-scanned data often suffer from extreme sparsity, severely hindering downstream 3D perception tasks. Existing point cloud upsampling methods primarily focus on individual objects, thus demonstrating limited generalization capability for complex outdoor scenes. To address this issue, we propose PVNet, a diffusion model-based point-voxel interaction framework to perform LiDAR point cloud upsampling without dense supervision. Specifically, we adopt the classifier-free guidance-based DDPMs to guide the generation, in which we employ a sparse point cloud as the guiding condition and the synthesized point clouds derived from its nearby frames as the input. Moreover, we design a voxel completion module to refine and complete the coarse voxel features for enriching the feature representation. In addition, we propose a point-voxel interaction module to integrate features from both points and voxels, which efficiently improves the environmental perception capability of each upsampled point. To the best of our knowledge, our approach is the first scene-level point cloud upsampling method supporting arbitrary upsampling rates. Extensive experiments on various benchmarks demonstrate that our method achieves state-of-the-art performance. The source code will be available at https://github.com/chengxianjing/PVNet.
HeLo: Heterogeneous Multi-Modal Fusion with Label Correlation for Emotion Distribution Learning
Jul 09, 2025Multi-modal emotion recognition has garnered increasing attention as it plays a significant role in human-computer interaction (HCI) in recent years. Since different discrete emotions may exist at the same time, compared with single-class emotion recognition, emotion distribution learning (EDL) that identifies a mixture of basic emotions has gradually emerged as a trend. However, existing EDL methods face challenges in mining the heterogeneity among multiple modalities. Besides, rich semantic correlations across arbitrary basic emotions are not fully exploited. In this paper, we propose a multi-modal emotion distribution learning framework, named HeLo, aimed at fully exploring the heterogeneity and complementary information in multi-modal emotional data and label correlation within mixed basic emotions. Specifically, we first adopt cross-attention to effectively fuse the physiological data. Then, an optimal transport (OT)-based heterogeneity mining module is devised to mine the interaction and heterogeneity between the physiological and behavioral representations. To facilitate label correlation learning, we introduce a learnable label embedding optimized by correlation matrix alignment. Finally, the learnable label embeddings and label correlation matrices are integrated with the multi-modal representations through a novel label correlation-driven cross-attention mechanism for accurate emotion distribution learning. Experimental results on two publicly available datasets demonstrate the superiority of our proposed method in emotion distribution learning.