 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVelox: Learning Representations of 4D Geometry and Appearance
May 06, 2026We introduce a framework for learning latent representations of 4D objects which are descriptive, faithfully capturing object geometry and appearance; compressive, aiding in downstream efficiency; and accessible, requiring minimal input, i.e., an unstructured dynamic point cloud, to construct. Specifically, Velox trains an encoder to compress spatiotemporal color point clouds into a set of dynamic shape tokens. These tokens are supervised using two complementary decoders: a 4D surface decoder, which models the time-varying surface distribution capturing the geometry; and a Gaussian decoder, which maps the tokens to 3D Gaussians, helping learn appearance. To demonstrate the utility of our representation, we evaluate it across three downstream tasks -- video-to-4D generation, 3D tracking, and cloth simulation via image-to-4D generation -- and observe strong performances in all settings.
VSAS-BENCH: Real-Time Evaluation of Visual Streaming Assistant Models
Apr 08, 2026Streaming vision-language models (VLMs) continuously generate responses given an instruction prompt and an online stream of input frames. This is a core mechanism for real-time visual assistants. Existing VLM frameworks predominantly assess models in offline settings. In contrast, the performance of a streaming VLM depends on additional metrics beyond pure video understanding, including proactiveness, which reflects the timeliness of the model's responses, and consistency, which captures the robustness of its responses over time. To address this limitation, we propose VSAS-Bench, a new framework and benchmark for Visual Streaming Assistants. In contrast to prior benchmarks that primarily employ single-turn question answering on video inputs, VSAS-Bench features temporally dense annotations with over 18,000 annotations across diverse input domains and task types. We introduce standardized synchronous and asynchronous evaluation protocols, along with metrics that isolate and measure distinct capabilities of streaming VLMs. Using this framework, we conduct large-scale evaluations of recent video and streaming VLMs, analyzing the accuracy-latency trade-off under key design factors such as memory buffer length, memory access policy, and input resolution, yielding several practical insights. Finally, we show empirically that conventional VLMs can be adapted to streaming settings without additional training, and demonstrate that these adapted models outperform recent streaming VLMs. For example, Qwen3-VL-4B surpasses Dispider, the best streaming VLM on our benchmark, by 3% under the asynchronous protocol. The benchmark and code will be available at https://github.com/apple/ml-vsas-bench.
LiTo: Surface Light Field Tokenization
Mar 11, 2026We propose a 3D latent representation that jointly models object geometry and view-dependent appearance. Most prior works focus on either reconstructing 3D geometry or predicting view-independent diffuse appearance, and thus struggle to capture realistic view-dependent effects. Our approach leverages that RGB-depth images provide samples of a surface light field. By encoding random subsamples of this surface light field into a compact set of latent vectors, our model learns to represent both geometry and appearance within a unified 3D latent space. This representation reproduces view-dependent effects such as specular highlights and Fresnel reflections under complex lighting. We further train a latent flow matching model on this representation to learn its distribution conditioned on a single input image, enabling the generation of 3D objects with appearances consistent with the lighting and materials in the input. Experiments show that our approach achieves higher visual quality and better input fidelity than existing methods.
ASTRA-bench: Evaluating Tool-Use Agent Reasoning and Action Planning with Personal User Context
Mar 02, 2026Next-generation AI must manage vast personal data, diverse tools, and multi-step reasoning, yet most benchmarks remain context-free and single-turn. We present ASTRA-bench (Assistant Skills in Tool-use, Reasoning \& Action-planning), a benchmark that uniquely unifies time-evolving personal context with an interactive toolbox and complex user intents. Our event-driven pipeline generates 2,413 scenarios across four protagonists, grounded in longitudinal life events and annotated by referential, functional, and informational complexity. Evaluation of state-of-the-art models (e.g., Claude-4.5-Opus, DeepSeek-V3.2) reveals significant performance degradation under high-complexity conditions, with argument generation emerging as the primary bottleneck. These findings expose critical limitations in current agents' ability to ground reasoning within messy personal context and orchestrate reliable multi-step plans. We release ASTRA-bench with a full execution environment and evaluation scripts to provide a diagnostic testbed for developing truly context-aware AI assistants.
TrajTok: Learning Trajectory Tokens enables better Video Understanding
Feb 26, 2026Tokenization in video models, typically through patchification, generates an excessive and redundant number of tokens. This severely limits video efficiency and scalability. While recent trajectory-based tokenizers offer a promising solution by decoupling video duration from token count, they rely on complex external segmentation and tracking pipelines that are slow and task-agnostic. We propose TrajTok, an end-to-end video tokenizer module that is fully integrated and co-trained with video models for a downstream objective, dynamically adapting its token granularity to semantic complexity, independent of video duration. TrajTok contains a unified segmenter that performs implicit clustering over pixels in both space and time to directly produce object trajectories in a single forward pass. By prioritizing downstream adaptability over pixel-perfect segmentation fidelity, TrajTok is lightweight and efficient, yet empirically improves video understanding performance. With TrajTok, we implement a video CLIP model trained from scratch (TrajViT2). It achieves the best accuracy at scale across both classification and retrieval benchmarks, while maintaining efficiency comparable to the best token-merging methods. TrajTok also proves to be a versatile component beyond its role as a tokenizer. We show that it can be seamlessly integrated as either a probing head for pretrained visual features (TrajAdapter) or an alignment connector in vision-language models (TrajVLM) with especially strong performance in long-video reasoning.
Beyond a Single Extractor: Re-thinking HTML-to-Text Extraction for LLM Pretraining
Feb 23, 2026One of the first pre-processing steps for constructing web-scale LLM pretraining datasets involves extracting text from HTML. Despite the immense diversity of web content, existing open-source datasets predominantly apply a single fixed extractor to all webpages. In this work, we investigate whether this practice leads to suboptimal coverage and utilization of Internet data. We first show that while different extractors may lead to similar model performance on standard language understanding tasks, the pages surviving a fixed filtering pipeline can differ substantially. This suggests a simple intervention: by taking a Union over different extractors, we can increase the token yield of DCLM-Baseline by up to 71% while maintaining benchmark performance. We further show that for structured content such as tables and code blocks, extractor choice can significantly impact downstream task performance, with differences of up to 10 percentage points (p.p.) on WikiTQ and 3 p.p. on HumanEval.
RayRoPE: Projective Ray Positional Encoding for Multi-view Attention
Jan 21, 2026We study positional encodings for multi-view transformers that process tokens from a set of posed input images, and seek a mechanism that encodes patches uniquely, allows SE(3)-invariant attention with multi-frequency similarity, and can be adaptive to the geometry of the underlying scene. We find that prior (absolute or relative) encoding schemes for multi-view attention do not meet the above desiderata, and present RayRoPE to address this gap. RayRoPE represents patch positions based on associated rays but leverages a predicted point along the ray instead of the direction for a geometry-aware encoding. To achieve SE(3) invariance, RayRoPE computes query-frame projective coordinates for computing multi-frequency similarity. Lastly, as the 'predicted' 3D point along a ray may not be precise, RayRoPE presents a mechanism to analytically compute the expected position encoding under uncertainty. We validate RayRoPE on the tasks of novel-view synthesis and stereo depth estimation and show that it consistently improves over alternate position encoding schemes (e.g. 15% relative improvement on LPIPS in CO3D). We also show that RayRoPE can seamlessly incorporate RGB-D input, resulting in even larger gains over alternatives that cannot positionally encode this information.
AMUSE: Audio-Visual Benchmark and Alignment Framework for Agentic Multi-Speaker Understanding
Dec 18, 2025

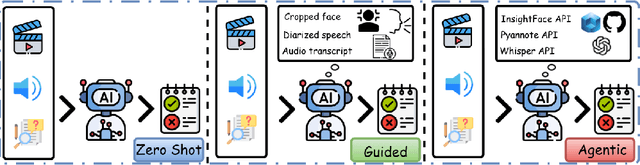
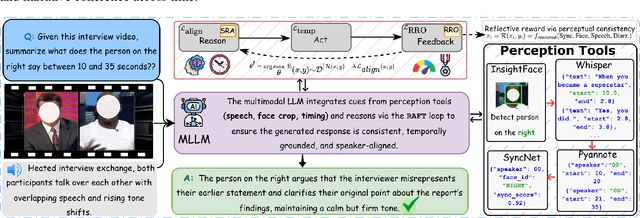
Recent multimodal large language models (MLLMs) such as GPT-4o and Qwen3-Omni show strong perception but struggle in multi-speaker, dialogue-centric settings that demand agentic reasoning tracking who speaks, maintaining roles, and grounding events across time. These scenarios are central to multimodal audio-video understanding, where models must jointly reason over audio and visual streams in applications such as conversational video assistants and meeting analytics. We introduce AMUSE, a benchmark designed around tasks that are inherently agentic, requiring models to decompose complex audio-visual interactions into planning, grounding, and reflection steps. It evaluates MLLMs across three modes zero-shot, guided, and agentic and six task families, including spatio-temporal speaker grounding and multimodal dialogue summarization. Across all modes, current models exhibit weak multi-speaker reasoning and inconsistent behavior under both non-agentic and agentic evaluation. Motivated by the inherently agentic nature of these tasks and recent advances in LLM agents, we propose RAFT, a data-efficient agentic alignment framework that integrates reward optimization with intrinsic multimodal self-evaluation as reward and selective parameter adaptation for data and parameter efficient updates. Using RAFT, we achieve up to 39.52\% relative improvement in accuracy on our benchmark. Together, AMUSE and RAFT provide a practical platform for examining agentic reasoning in multimodal models and improving their capabilities.
Learning to Reason for Hallucination Span Detection
Oct 02, 2025



Large language models (LLMs) often generate hallucinations -- unsupported content that undermines reliability. While most prior works frame hallucination detection as a binary task, many real-world applications require identifying hallucinated spans, which is a multi-step decision making process. This naturally raises the question of whether explicit reasoning can help the complex task of detecting hallucination spans. To answer this question, we first evaluate pretrained models with and without Chain-of-Thought (CoT) reasoning, and show that CoT reasoning has the potential to generate at least one correct answer when sampled multiple times. Motivated by this, we propose RL4HS, a reinforcement learning framework that incentivizes reasoning with a span-level reward function. RL4HS builds on Group Relative Policy Optimization and introduces Class-Aware Policy Optimization to mitigate reward imbalance issue. Experiments on the RAGTruth benchmark (summarization, question answering, data-to-text) show that RL4HS surpasses pretrained reasoning models and supervised fine-tuning, demonstrating the necessity of reinforcement learning with span-level rewards for detecting hallucination spans.
MobileCLIP2: Improving Multi-Modal Reinforced Training
Aug 28, 2025Foundation image-text models such as CLIP with zero-shot capabilities enable a wide array of applications. MobileCLIP is a recent family of image-text models at 3-15ms latency and 50-150M parameters with state-of-the-art zero-shot accuracy. The main ingredients in MobileCLIP were its low-latency and light architectures and a novel multi-modal reinforced training that made knowledge distillation from multiple caption-generators and CLIP teachers efficient, scalable, and reproducible. In this paper, we improve the multi-modal reinforced training of MobileCLIP through: 1) better CLIP teacher ensembles trained on the DFN dataset, 2) improved captioner teachers trained on the DFN dataset and fine-tuned on a diverse selection of high-quality image-caption datasets. We discover new insights through ablations such as the importance of temperature tuning in contrastive knowledge distillation, the effectiveness of caption-generator fine-tuning for caption diversity, and the additive improvement from combining synthetic captions generated by multiple models. We train a new family of models called MobileCLIP2 and achieve state-of-the-art ImageNet-1k zero-shot accuracies at low latencies. In particular, we observe 2.2% improvement in ImageNet-1k accuracy for MobileCLIP2-B compared with MobileCLIP-B architecture. Notably, MobileCLIP2-S4 matches the zero-shot accuracy of SigLIP-SO400M/14 on ImageNet-1k while being 2$\times$ smaller and improves on DFN ViT-L/14 at 2.5$\times$ lower latency. We release our pretrained models (https://github.com/apple/ml-mobileclip) and the data generation code (https://github.com/apple/ml-mobileclip-dr). The data generation code makes it easy to create new reinforced datasets with arbitrary teachers using distributed scalable processing.