 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreFlow: Corrective Reflow for Sparse-Reward Embodied Video Diffusion RL
May 14, 2026Video generation models trained on heterogeneous data with likelihood-surrogate objectives can produce visually plausible rollouts that violate physical constraints in embodied manipulation. Although reinforcement-learning post-training offers a natural route to adapting VGMs, existing video-RL rewards often reduce each rollout to a low-level visual metric, whereas manipulation video evaluation requires logic-based verification of whether the rollout satisfies a compositional task specification. To fill this gap, we introduce a compositional constraint-based reward model for post-training embodied video generation models, which automatically formulates task requirements as a composition of Linear Temporal Logic constraints, providing faithful rewards and localized error information in generated videos. To achieve effective improvement in high-dimensional video generation using these reward signals, we further propose CreFlow, a novel online RL framework with two key designs: i) a credit-aware NFT loss that confines the RL update to reward-relevant regions, preventing perturbations to unrelated regions during post-training; and ii) a corrective reflow loss that leverages within-group positive samples as an explicit estimate of the correction direction, stabilizing and accelerating training. Experiments show that CreFlow yields reward judgments better aligned with human and simulator success labels than existing methods and improves downstream execution success by 23.8 percentage points across eight bimanual manipulation tasks.
LLM Agents Enable User-Governed Personalization Beyond Platform Boundaries
May 10, 2026Personalization today is fundamentally platform-centric: services build user representations from the behavioral fragments they observe. Yet no platform can construct a complete picture of the user, as competitive incentives, legal constraints, user privacy concerns, and epistemic limits create persistent data barriers. This paper argues for a shift from platform-centric personalization to user-governed personalization, where only the user can integrate fragmented contexts across platforms and the offline world. The key asymmetry lies in data access: only users can aggregate their own cross-platform and offline information. Large language model (LLM) agents make such integration practically feasible for the first time by enabling reasoning over heterogeneous personal data and transforming users' cross-context information into actionable personalization capabilities. We provide proof-of-concept evidence that users equipped with cross-platform data exports and an off-the-shelf LLM agent can outperform single-platform personalization baselines. We conclude by outlining a research agenda for building scalable user-governed personalization systems.
A Unified Framework for Rethinking Policy Divergence Measures in GRPO
Feb 05, 2026Reinforcement Learning with Verified Reward (RLVR) has emerged as a critical paradigm for advancing the reasoning capabilities of Large Language Models (LLMs). Most existing RLVR methods, such as GRPO and its variants, ensure stable updates by constraining policy divergence through clipping likelihood ratios. This paper introduces a unified clipping framework that characterizes existing methods via a general notion of policy divergence, encompassing both likelihood ratios and Kullback-Leibler (KL) divergences and extending to alternative measures. The framework provides a principled foundation for systematically analyzing how different policy divergence measures affect exploration and performance. We further identify the KL3 estimator, a variance-reduced Monte Carlo estimator of the KL divergence, as a key policy divergence constraint. We theoretically demonstrate that the KL3-based constraint is mathematically equivalent to an asymmetric ratio-based clipping that reallocates probability mass toward high-confidence actions, promoting stronger exploration while retaining the simplicity of GRPO-style methods. Empirical results on mathematical reasoning benchmarks demonstrate that incorporating the KL3 estimator into GRPO improves both training stability and final performance, highlighting the importance of principled policy divergence constraints in policy optimization.
Directly Forecasting Belief for Reinforcement Learning with Delays
May 01, 2025Reinforcement learning (RL) with delays is challenging as sensory perceptions lag behind the actual events: the RL agent needs to estimate the real state of its environment based on past observations. State-of-the-art (SOTA) methods typically employ recursive, step-by-step forecasting of states. This can cause the accumulation of compounding errors. To tackle this problem, our novel belief estimation method, named Directly Forecasting Belief Transformer (DFBT), directly forecasts states from observations without incrementally estimating intermediate states step-by-step. We theoretically demonstrate that DFBT greatly reduces compounding errors of existing recursively forecasting methods, yielding stronger performance guarantees. In experiments with D4RL offline datasets, DFBT reduces compounding errors with remarkable prediction accuracy. DFBT's capability to forecast state sequences also facilitates multi-step bootstrapping, thus greatly improving learning efficiency. On the MuJoCo benchmark, our DFBT-based method substantially outperforms SOTA baselines.
Inverse Delayed Reinforcement Learning
Dec 04, 2024



Inverse Reinforcement Learning (IRL) has demonstrated effectiveness in a variety of imitation tasks. In this paper, we introduce an IRL framework designed to extract rewarding features from expert trajectories affected by delayed disturbances. Instead of relying on direct observations, our approach employs an efficient off-policy adversarial training framework to derive expert features and recover optimal policies from augmented delayed observations. Empirical evaluations in the MuJoCo environment under diverse delay settings validate the effectiveness of our method. Furthermore, we provide a theoretical analysis showing that recovering expert policies from augmented delayed observations outperforms using direct delayed observations.
Model-Based Reward Shaping for Adversarial Inverse Reinforcement Learning in Stochastic Environments
Oct 04, 2024



In this paper, we aim to tackle the limitation of the Adversarial Inverse Reinforcement Learning (AIRL) method in stochastic environments where theoretical results cannot hold and performance is degraded. To address this issue, we propose a novel method which infuses the dynamics information into the reward shaping with the theoretical guarantee for the induced optimal policy in the stochastic environments. Incorporating our novel model-enhanced rewards, we present a novel Model-Enhanced AIRL framework, which integrates transition model estimation directly into reward shaping. Furthermore, we provide a comprehensive theoretical analysis of the reward error bound and performance difference bound for our method. The experimental results in MuJoCo benchmarks show that our method can achieve superior performance in stochastic environments and competitive performance in deterministic environments, with significant improvement in sample efficiency, compared to existing baselines.
Variational Delayed Policy Optimization
May 23, 2024In environments with delayed observation, state augmentation by including actions within the delay window is adopted to retrieve Markovian property to enable reinforcement learning (RL). However, state-of-the-art (SOTA) RL techniques with Temporal-Difference (TD) learning frameworks often suffer from learning inefficiency, due to the significant expansion of the augmented state space with the delay. To improve learning efficiency without sacrificing performance, this work introduces a novel framework called Variational Delayed Policy Optimization (VDPO), which reformulates delayed RL as a variational inference problem. This problem is further modelled as a two-step iterative optimization problem, where the first step is TD learning in the delay-free environment with a small state space, and the second step is behaviour cloning which can be addressed much more efficiently than TD learning. We not only provide a theoretical analysis of VDPO in terms of sample complexity and performance, but also empirically demonstrate that VDPO can achieve consistent performance with SOTA methods, with a significant enhancement of sample efficiency (approximately 50\% less amount of samples) in the MuJoCo benchmark.
Boosting Long-Delayed Reinforcement Learning with Auxiliary Short-Delayed Task
Feb 05, 2024Reinforcement learning is challenging in delayed scenarios, a common real-world situation where observations and interactions occur with delays. State-of-the-art (SOTA) state-augmentation techniques either suffer from the state-space explosion along with the delayed steps, or performance degeneration in stochastic environments. To address these challenges, our novel Auxiliary-Delayed Reinforcement Learning (AD-RL) leverages an auxiliary short-delayed task to accelerate the learning on a long-delayed task without compromising the performance in stochastic environments. Specifically, AD-RL learns the value function in the short-delayed task and then employs it with the bootstrapping and policy improvement techniques in the long-delayed task. We theoretically show that this can greatly reduce the sample complexity compared to directly learning on the original long-delayed task. On deterministic and stochastic benchmarks, our method remarkably outperforms the SOTAs in both sample efficiency and policy performance.
State-wise Safe Reinforcement Learning With Pixel Observations
Nov 03, 2023



Reinforcement Learning(RL) in the context of safe exploration has long grappled with the challenges of the delicate balance between maximizing rewards and minimizing safety violations, the complexities arising from contact-rich or non-smooth environments, and high-dimensional pixel observations. Furthermore, incorporating state-wise safety constraints in the exploration and learning process, where the agent is prohibited from accessing unsafe regions without prior knowledge, adds an additional layer of complexity. In this paper, we propose a novel pixel-observation safe RL algorithm that efficiently encodes state-wise safety constraints with unknown hazard regions through the introduction of a latent barrier function learning mechanism. As a joint learning framework, our approach first involves constructing a latent dynamics model with low-dimensional latent spaces derived from pixel observations. Subsequently, we build and learn a latent barrier function on top of the latent dynamics and conduct policy optimization simultaneously, thereby improving both safety and the total expected return. Experimental evaluations on the safety-gym benchmark suite demonstrate that our proposed method significantly reduces safety violations throughout the training process and demonstrates faster safety convergence compared to existing methods while achieving competitive results in reward return.
Enforcing Hard Constraints with Soft Barriers: Safe Reinforcement Learning in Unknown Stochastic Environments
Sep 29, 2022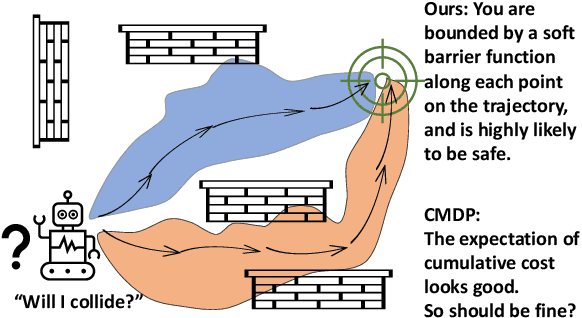
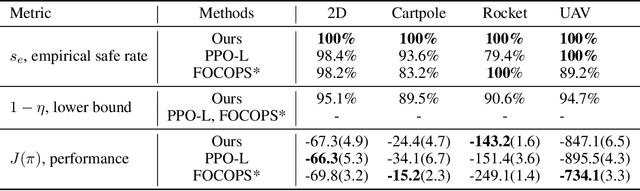
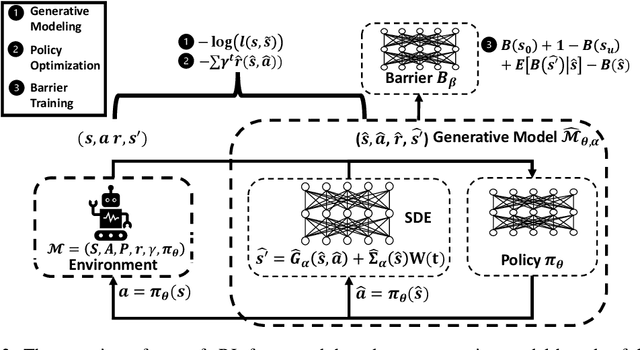
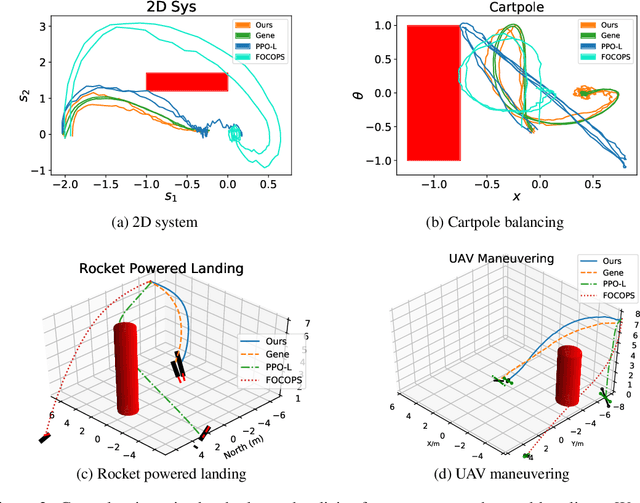
It is quite challenging to ensure the safety of reinforcement learning (RL) agents in an unknown and stochastic environment under hard constraints that require the system state not to reach certain specified unsafe regions. Many popular safe RL methods such as those based on the Constrained Markov Decision Process (CMDP) paradigm formulate safety violations in a cost function and try to constrain the expectation of cumulative cost under a threshold. However, it is often difficult to effectively capture and enforce hard reachability-based safety constraints indirectly with such constraints on safety violation costs. In this work, we leverage the notion of barrier function to explicitly encode the hard safety constraints, and given that the environment is unknown, relax them to our design of \emph{generative-model-based soft barrier functions}. Based on such soft barriers, we propose a safe RL approach that can jointly learn the environment and optimize the control policy, while effectively avoiding unsafe regions with safety probability optimization. Experiments on a set of examples demonstrate that our approach can effectively enforce hard safety constraints and significantly outperform CMDP-based baseline methods in system safe rate measured via simulations.