 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetacognitive Self-Correction for Multi-Agent System via Prototype-Guided Next-Execution Reconstruction
Oct 16, 2025Large Language Model based multi-agent systems (MAS) excel at collaborative problem solving but remain brittle to cascading errors: a single faulty step can propagate across agents and disrupt the trajectory. In this paper, we present MASC, a metacognitive framework that endows MAS with real-time, unsupervised, step-level error detection and self-correction. MASC rethinks detection as history-conditioned anomaly scoring via two complementary designs: (1) Next-Execution Reconstruction, which predicts the embedding of the next step from the query and interaction history to capture causal consistency, and (2) Prototype-Guided Enhancement, which learns a prototype prior over normal-step embeddings and uses it to stabilize reconstruction and anomaly scoring under sparse context (e.g., early steps). When an anomaly step is flagged, MASC triggers a correction agent to revise the acting agent's output before information flows downstream. On the Who&When benchmark, MASC consistently outperforms all baselines, improving step-level error detection by up to 8.47% AUC-ROC ; When plugged into diverse MAS frameworks, it delivers consistent end-to-end gains across architectures, confirming that our metacognitive monitoring and targeted correction can mitigate error propagation with minimal overhead.
From Scores to Preferences: Redefining MOS Benchmarking for Speech Quality Reward Modeling
Oct 01, 2025Assessing the perceptual quality of synthetic speech is crucial for guiding the development and refinement of speech generation models. However, it has traditionally relied on human subjective ratings such as the Mean Opinion Score (MOS), which depend on manual annotations and often suffer from inconsistent rating standards and poor reproducibility. To address these limitations, we introduce MOS-RMBench, a unified benchmark that reformulates diverse MOS datasets into a preference-comparison setting, enabling rigorous evaluation across different datasets. Building on MOS-RMBench, we systematically construct and evaluate three paradigms for reward modeling: scalar reward models, semi-scalar reward models, and generative reward models (GRMs). Our experiments reveal three key findings: (1) scalar models achieve the strongest overall performance, consistently exceeding 74% accuracy; (2) most models perform considerably worse on synthetic speech than on human speech; and (3) all models struggle on pairs with very small MOS differences. To improve performance on these challenging pairs, we propose a MOS-aware GRM that incorporates an MOS-difference-based reward function, enabling the model to adaptively scale rewards according to the difficulty of each sample pair. Experimental results show that the MOS-aware GRM significantly improves fine-grained quality discrimination and narrows the gap with scalar models on the most challenging cases. We hope this work will establish both a benchmark and a methodological framework to foster more rigorous and scalable research in automatic speech quality assessment.
Query-Kontext: An Unified Multimodal Model for Image Generation and Editing
Sep 30, 2025



Unified Multimodal Models (UMMs) have demonstrated remarkable performance in text-to-image generation (T2I) and editing (TI2I), whether instantiated as assembled unified frameworks which couple powerful vision-language model (VLM) with diffusion-based generator, or as naive Unified Multimodal Models with an early fusion of understanding and generation modalities. We contend that in current unified frameworks, the crucial capability of multimodal generative reasoning which encompasses instruction understanding, grounding, and image referring for identity preservation and faithful reconstruction, is intrinsically entangled with high-fidelity synthesis. In this work, we introduce Query-Kontext, a novel approach that bridges the VLM and diffusion model via a multimodal ``kontext'' composed of semantic cues and coarse-grained image conditions encoded from multimodal inputs. This design delegates the complex ability of multimodal generative reasoning to powerful VLM while reserving diffusion model's role for high-quality visual synthesis. To achieve this, we propose a three-stage progressive training strategy. First, we connect the VLM to a lightweight diffusion head via multimodal kontext tokens to unleash the VLM's generative reasoning ability. Second, we scale this head to a large, pre-trained diffusion model to enhance visual detail and realism. Finally, we introduce a low-level image encoder to improve image fidelity and perform instruction tuning on downstream tasks. Furthermore, we build a comprehensive data pipeline integrating real, synthetic, and open-source datasets, covering diverse multimodal reference-to-image scenarios, including image generation, instruction-driven editing, customized generation, and multi-subject composition. Experiments show that our approach matches strong unified baselines and even outperforms task-specific state-of-the-art methods in several cases.
MDAR: A Multi-scene Dynamic Audio Reasoning Benchmark
Sep 26, 2025The ability to reason from audio, including speech, paralinguistic cues, environmental sounds, and music, is essential for AI agents to interact effectively in real-world scenarios. Existing benchmarks mainly focus on static or single-scene settings and do not fully capture scenarios where multiple speakers, unfolding events, and heterogeneous audio sources interact. To address these challenges, we introduce MDAR, a benchmark for evaluating models on complex, multi-scene, and dynamically evolving audio reasoning tasks. MDAR comprises 3,000 carefully curated question-answer pairs linked to diverse audio clips, covering five categories of complex reasoning and spanning three question types. We benchmark 26 state-of-the-art audio language models on MDAR and observe that they exhibit limitations in complex reasoning tasks. On single-choice questions, Qwen2.5-Omni (open-source) achieves 76.67% accuracy, whereas GPT-4o Audio (closed-source) reaches 68.47%; however, GPT-4o Audio substantially outperforms Qwen2.5-Omni on the more challenging multiple-choice and open-ended tasks. Across all three question types, no model achieves 80% performance. These findings underscore the unique challenges posed by MDAR and its value as a benchmark for advancing audio reasoning research.Code and benchmark can be found at https://github.com/luckyerr/MDAR.
A Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning
Sep 19, 2025Robotic real-world reinforcement learning (RL) with vision-language-action (VLA) models is bottlenecked by sparse, handcrafted rewards and inefficient exploration. We introduce VLAC, a general process reward model built upon InternVL and trained on large scale heterogeneous datasets. Given pairwise observations and a language goal, it outputs dense progress delta and done signal, eliminating task-specific reward engineering, and supports one-shot in-context transfer to unseen tasks and environments. VLAC is trained on vision-language datasets to strengthen perception, dialogic and reasoning capabilities, together with robot and human trajectories data that ground action generation and progress estimation, and additionally strengthened to reject irrelevant prompts as well as detect regression or stagnation by constructing large numbers of negative and semantically mismatched samples. With prompt control, a single VLAC model alternately generating reward and action tokens, unifying critic and policy. Deployed inside an asynchronous real-world RL loop, we layer a graded human-in-the-loop protocol (offline demonstration replay, return and explore, human guided explore) that accelerates exploration and stabilizes early learning. Across four distinct real-world manipulation tasks, VLAC lifts success rates from about 30\% to about 90\% within 200 real-world interaction episodes; incorporating human-in-the-loop interventions yields a further 50% improvement in sample efficiency and achieves up to 100% final success.
TASAM: Terrain-and-Aware Segment Anything Model for Temporal-Scale Remote Sensing Segmentation
Sep 19, 2025Segment Anything Model (SAM) has demonstrated impressive zero-shot segmentation capabilities across natural image domains, but it struggles to generalize to the unique challenges of remote sensing data, such as complex terrain, multi-scale objects, and temporal dynamics. In this paper, we introduce TASAM, a terrain and temporally-aware extension of SAM designed specifically for high-resolution remote sensing image segmentation. TASAM integrates three lightweight yet effective modules: a terrain-aware adapter that injects elevation priors, a temporal prompt generator that captures land-cover changes over time, and a multi-scale fusion strategy that enhances fine-grained object delineation. Without retraining the SAM backbone, our approach achieves substantial performance gains across three remote sensing benchmarks-LoveDA, iSAID, and WHU-CD-outperforming both zero-shot SAM and task-specific models with minimal computational overhead. Our results highlight the value of domain-adaptive augmentation for foundation models and offer a scalable path toward more robust geospatial segmentation.
CUFG: Curriculum Unlearning Guided by the Forgetting Gradient
Sep 18, 2025As privacy and security take center stage in AI, machine unlearning, the ability to erase specific knowledge from models, has garnered increasing attention. However, existing methods overly prioritize efficiency and aggressive forgetting, which introduces notable limitations. In particular, radical interventions like gradient ascent, influence functions, and random label noise can destabilize model weights, leading to collapse and reduced reliability. To address this, we propose CUFG (Curriculum Unlearning via Forgetting Gradients), a novel framework that enhances the stability of approximate unlearning through innovations in both forgetting mechanisms and data scheduling strategies. Specifically, CUFG integrates a new gradient corrector guided by forgetting gradients for fine-tuning-based unlearning and a curriculum unlearning paradigm that progressively forgets from easy to hard. These innovations narrow the gap with the gold-standard Retrain method by enabling more stable and progressive unlearning, thereby improving both effectiveness and reliability. Furthermore, we believe that the concept of curriculum unlearning has substantial research potential and offers forward-looking insights for the development of the MU field. Extensive experiments across various forgetting scenarios validate the rationale and effectiveness of our approach and CUFG. Codes are available at https://anonymous.4open.science/r/CUFG-6375.
Hint: hierarchical inter-frame correlation for one-shot point cloud sequence compression
Sep 18, 2025Deep learning has demonstrated strong capability in compressing point clouds. Within this area, entropy modeling for lossless compression is widely investigated. However, most methods rely solely on parent orsibling contexts and level-wise autoregression, which suffers from decoding latency on the order of 10 to 100 seconds. We propose HINT, a method that integrates temporal and spatial correlation for sequential point cloud compression. Specifically, it first uses a two stage temporal feature extraction: (i) a parent-level existence map and (ii) a child-level neighborhood lookup in the previous frame. These cues are fused with the spatial features via elementwise addition and encoded with a group-wise strategy. Experimental results show that HINT achieves encoding and decoding time at 105 ms and 140 ms, respectively, equivalent to 49.6x and 21.6x acceleration in comparison with G-PCC, while achieving up to bit rate reduction of 43.6%, in addition, consistently outperforming over the strong spatial only baseline (RENO).
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
Sep 10, 2025Developing autonomous LLM agents capable of making a series of intelligent decisions to solve complex, real-world tasks is a fast-evolving frontier. Like human cognitive development, agents are expected to acquire knowledge and skills through exploration and interaction with the environment. Despite advances, the community still lacks a unified, interactive reinforcement learning (RL) framework that can effectively train such agents from scratch -- without relying on supervised fine-tuning (SFT) -- across diverse and realistic environments. To bridge this gap, we introduce AgentGym-RL, a new framework to train LLM agents for multi-turn interactive decision-making through RL. The framework features a modular and decoupled architecture, ensuring high flexibility and extensibility. It encompasses a wide variety of real-world scenarios, and supports mainstream RL algorithms. Furthermore, we propose ScalingInter-RL, a training approach designed for exploration-exploitation balance and stable RL optimization. In early stages, it emphasizes exploitation by restricting the number of interactions, and gradually shifts towards exploration with larger horizons to encourage diverse problem-solving strategies. In this way, the agent develops more diverse behaviors and is less prone to collapse under long horizons. We perform extensive experiments to validate the stability and effectiveness of both the AgentGym-RL framework and the ScalingInter-RL approach. Our agents match or surpass commercial models on 27 tasks across diverse environments. We offer key insights and will open-source the complete AgentGym-RL framework -- including code and datasets -- to empower the research community in developing the next generation of intelligent agents.
TinySR: Pruning Diffusion for Real-World Image Super-Resolution
Aug 24, 2025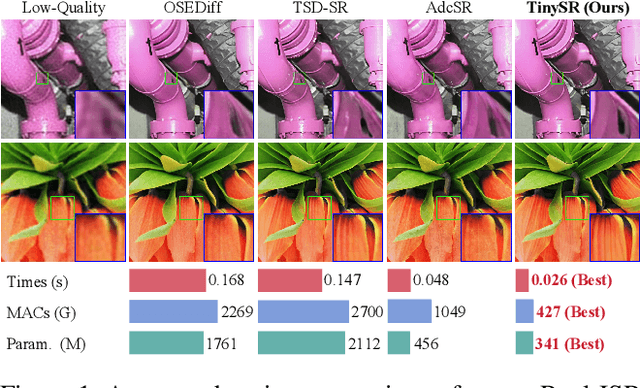
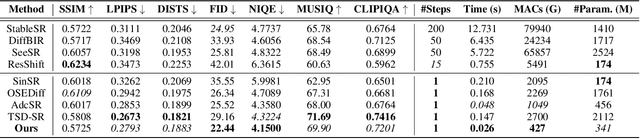
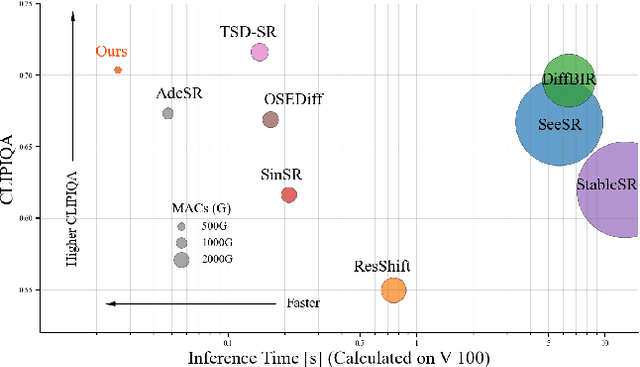
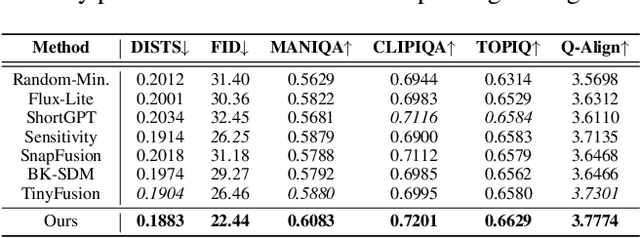
Real-world image super-resolution (Real-ISR) focuses on recovering high-quality images from low-resolution inputs that suffer from complex degradations like noise, blur, and compression. Recently, diffusion models (DMs) have shown great potential in this area by leveraging strong generative priors to restore fine details. However, their iterative denoising process incurs high computational overhead, posing challenges for real-time applications. Although one-step distillation methods, such as OSEDiff and TSD-SR, offer faster inference, they remain fundamentally constrained by their large, over-parameterized model architectures. In this work, we present TinySR, a compact yet effective diffusion model specifically designed for Real-ISR that achieves real-time performance while maintaining perceptual quality. We introduce a Dynamic Inter-block Activation and an Expansion-Corrosion Strategy to facilitate more effective decision-making in depth pruning. We achieve VAE compression through channel pruning, attention removal and lightweight SepConv. We eliminate time- and prompt-related modules and perform pre-caching techniques to further speed up the model. TinySR significantly reduces computational cost and model size, achieving up to 5.68x speedup and 83% parameter reduction compared to its teacher TSD-SR, while still providing high quality results.