 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Unfaithful Chain-of-Thought via Circuit-Guided Internal-External Discrepancy
May 25, 2026Chain-of-thought (CoT) reasoning improves the problem-solving ability of large language models (LLMs), but generated reasoning traces may not faithfully reflect the model's actual decision process. Existing CoT unfaithfulness detectors mainly rely on external signals from generated rationales, such as textual plausibility or answer consistency, while overlooking evidence from the model's internal computation. Although recent circuit tracing methods provide a way to obtain model-internal evidence by tracing how information flows through model components during reasoning, constructing full reasoning circuits for long CoTs is costly and difficult to scale. To address these challenges, we propose Circuit-guided Internal-External Discrepancy Scorer (CIE-Scorer), a framework for instance-level CoT unfaithfulness detection. The key idea is that faithful reasoning traces should align with the model's computational process, whereas unfaithful traces may diverge from it. CIE-Scorer efficiently traces compact sentence-level circuits from informative reasoning tokens, constructs internal and external reasoning graphs, and measures their discrepancy using Fused Gromov--Wasserstein distance. Experiments on four datasets from FaithCoT-Bench show that CIE-Scorer achieves state-of-the-art performance while reducing the cost of circuit construction, demonstrating the effectiveness of combining mechanistic interpretability signals with external reasoning traces for CoT unfaithfulness detection.
HyperD: Hybrid Periodicity Decoupling Framework for Traffic Forecasting
Nov 16, 2025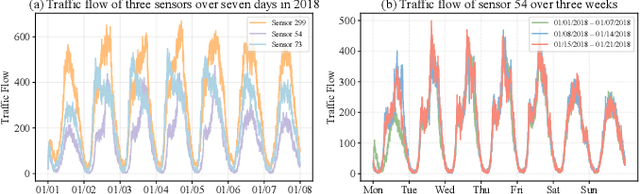
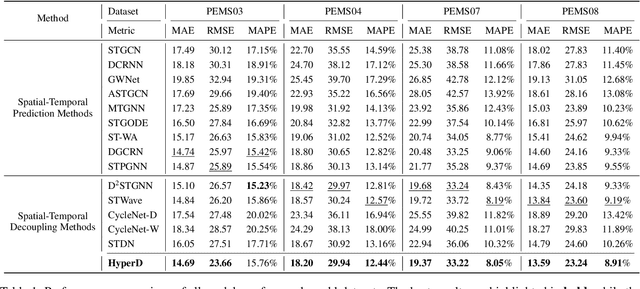
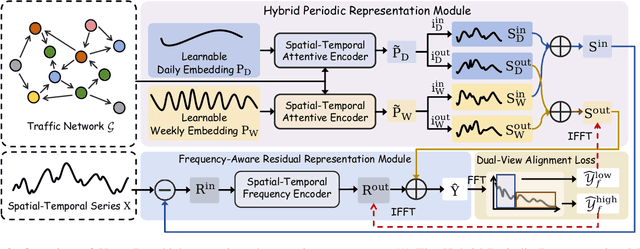
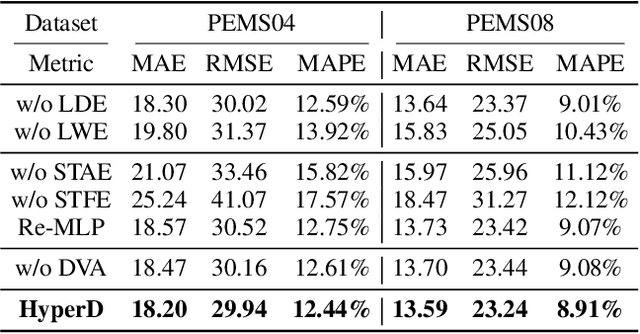
Accurate traffic forecasting plays a vital role in intelligent transportation systems, enabling applications such as congestion control, route planning, and urban mobility optimization. However, traffic forecasting remains challenging due to two key factors: (1) complex spatial dependencies arising from dynamic interactions between road segments and traffic sensors across the network, and (2) the coexistence of multi-scale periodic patterns (e.g., daily and weekly periodic patterns driven by human routines) with irregular fluctuations caused by unpredictable events (e.g., accidents, weather, or construction). To tackle these challenges, we propose HyperD (Hybrid Periodic Decoupling), a novel framework that decouples traffic data into periodic and residual components. The periodic component is handled by the Hybrid Periodic Representation Module, which extracts fine-grained daily and weekly patterns using learnable periodic embeddings and spatial-temporal attention. The residual component, which captures non-periodic, high-frequency fluctuations, is modeled by the Frequency-Aware Residual Representation Module, leveraging complex-valued MLP in frequency domain. To enforce semantic separation between the two components, we further introduce a Dual-View Alignment Loss, which aligns low-frequency information with the periodic branch and high-frequency information with the residual branch. Extensive experiments on four real-world traffic datasets demonstrate that HyperD achieves state-of-the-art prediction accuracy, while offering superior robustness under disturbances and improved computational efficiency compared to existing methods.
Metacognitive Self-Correction for Multi-Agent System via Prototype-Guided Next-Execution Reconstruction
Oct 16, 2025Large Language Model based multi-agent systems (MAS) excel at collaborative problem solving but remain brittle to cascading errors: a single faulty step can propagate across agents and disrupt the trajectory. In this paper, we present MASC, a metacognitive framework that endows MAS with real-time, unsupervised, step-level error detection and self-correction. MASC rethinks detection as history-conditioned anomaly scoring via two complementary designs: (1) Next-Execution Reconstruction, which predicts the embedding of the next step from the query and interaction history to capture causal consistency, and (2) Prototype-Guided Enhancement, which learns a prototype prior over normal-step embeddings and uses it to stabilize reconstruction and anomaly scoring under sparse context (e.g., early steps). When an anomaly step is flagged, MASC triggers a correction agent to revise the acting agent's output before information flows downstream. On the Who&When benchmark, MASC consistently outperforms all baselines, improving step-level error detection by up to 8.47% AUC-ROC ; When plugged into diverse MAS frameworks, it delivers consistent end-to-end gains across architectures, confirming that our metacognitive monitoring and targeted correction can mitigate error propagation with minimal overhead.
BlindGuard: Safeguarding LLM-based Multi-Agent Systems under Unknown Attacks
Aug 11, 2025The security of LLM-based multi-agent systems (MAS) is critically threatened by propagation vulnerability, where malicious agents can distort collective decision-making through inter-agent message interactions. While existing supervised defense methods demonstrate promising performance, they may be impractical in real-world scenarios due to their heavy reliance on labeled malicious agents to train a supervised malicious detection model. To enable practical and generalizable MAS defenses, in this paper, we propose BlindGuard, an unsupervised defense method that learns without requiring any attack-specific labels or prior knowledge of malicious behaviors. To this end, we establish a hierarchical agent encoder to capture individual, neighborhood, and global interaction patterns of each agent, providing a comprehensive understanding for malicious agent detection. Meanwhile, we design a corruption-guided detector that consists of directional noise injection and contrastive learning, allowing effective detection model training solely on normal agent behaviors. Extensive experiments show that BlindGuard effectively detects diverse attack types (i.e., prompt injection, memory poisoning, and tool attack) across MAS with various communication patterns while maintaining superior generalizability compared to supervised baselines. The code is available at: https://github.com/MR9812/BlindGuard.
Understanding the Information Propagation Effects of Communication Topologies in LLM-based Multi-Agent Systems
May 29, 2025The communication topology in large language model-based multi-agent systems fundamentally governs inter-agent collaboration patterns, critically shaping both the efficiency and effectiveness of collective decision-making. While recent studies for communication topology automated design tend to construct sparse structures for efficiency, they often overlook why and when sparse and dense topologies help or hinder collaboration. In this paper, we present a causal framework to analyze how agent outputs, whether correct or erroneous, propagate under topologies with varying sparsity. Our empirical studies reveal that moderately sparse topologies, which effectively suppress error propagation while preserving beneficial information diffusion, typically achieve optimal task performance. Guided by this insight, we propose a novel topology design approach, EIB-leanrner, that balances error suppression and beneficial information propagation by fusing connectivity patterns from both dense and sparse graphs. Extensive experiments show the superior effectiveness, communication cost, and robustness of EIB-leanrner.
SpecOffload: Unlocking Latent GPU Capacity for LLM Inference on Resource-Constrained Devices
May 15, 2025Efficient LLM inference on resource-constrained devices presents significant challenges in compute and memory utilization. Due to limited GPU memory, existing systems offload model weights to CPU memory, incurring substantial I/O overhead between the CPU and GPU. This leads to two major inefficiencies: (1) GPU cores are underutilized, often remaining idle while waiting for data to be loaded; and (2) GPU memory has low impact on performance, as reducing its capacity has minimal effect on overall throughput.In this paper, we propose SpecOffload, a high-throughput inference engine that embeds speculative decoding into offloading. Our key idea is to unlock latent GPU resources for storing and executing a draft model used for speculative decoding, thus accelerating inference at near-zero additional cost. To support this, we carefully orchestrate the interleaved execution of target and draft models in speculative decoding within the offloading pipeline, and propose a planner to manage tensor placement and select optimal parameters. Compared to the best baseline, SpecOffload improves GPU core utilization by 4.49x and boosts inference throughput by 2.54x. Our code is available at https://github.com/MobiSense/SpecOffload .
Harnessing LLMs Explanations to Boost Surrogate Models in Tabular Data Classification
May 09, 2025Large Language Models (LLMs) have shown remarkable ability in solving complex tasks, making them a promising tool for enhancing tabular learning. However, existing LLM-based methods suffer from high resource requirements, suboptimal demonstration selection, and limited interpretability, which largely hinder their prediction performance and application in the real world. To overcome these problems, we propose a novel in-context learning framework for tabular prediction. The core idea is to leverage the explanations generated by LLMs to guide a smaller, locally deployable Surrogate Language Model (SLM) to make interpretable tabular predictions. Specifically, our framework mainly involves three stages: (i) Post Hoc Explanation Generation, where LLMs are utilized to generate explanations for question-answer pairs in candidate demonstrations, providing insights into the reasoning behind the answer. (ii) Post Hoc Explanation-Guided Demonstrations Selection, which utilizes explanations generated by LLMs to guide the process of demonstration selection from candidate demonstrations. (iii) Post Hoc Explanation-Guided Interpretable SLM Prediction, which utilizes the demonstrations obtained in step (ii) as in-context and merges corresponding explanations as rationales to improve the performance of SLM and guide the model to generate interpretable outputs. Experimental results highlight the framework's effectiveness, with an average accuracy improvement of 5.31% across various tabular datasets in diverse domains.
Latte: Transfering LLMs` Latent-level Knowledge for Few-shot Tabular Learning
May 08, 2025



Few-shot tabular learning, in which machine learning models are trained with a limited amount of labeled data, provides a cost-effective approach to addressing real-world challenges. The advent of Large Language Models (LLMs) has sparked interest in leveraging their pre-trained knowledge for few-shot tabular learning. Despite promising results, existing approaches either rely on test-time knowledge extraction, which introduces undesirable latency, or text-level knowledge, which leads to unreliable feature engineering. To overcome these limitations, we propose Latte, a training-time knowledge extraction framework that transfers the latent prior knowledge within LLMs to optimize a more generalized downstream model. Latte enables general knowledge-guided downstream tabular learning, facilitating the weighted fusion of information across different feature values while reducing the risk of overfitting to limited labeled data. Furthermore, Latte is compatible with existing unsupervised pre-training paradigms and effectively utilizes available unlabeled samples to overcome the performance limitations imposed by an extremely small labeled dataset. Extensive experiments on various few-shot tabular learning benchmarks demonstrate the superior performance of Latte, establishing it as a state-of-the-art approach in this domain
A Comprehensive Survey of Synthetic Tabular Data Generation
Apr 23, 2025Tabular data remains one of the most prevalent and critical data formats across diverse real-world applications. However, its effective use in machine learning (ML) is often constrained by challenges such as data scarcity, privacy concerns, and class imbalance. Synthetic data generation has emerged as a promising solution, leveraging generative models to learn the distribution of real datasets and produce high-fidelity, privacy-preserving samples. Various generative paradigms have been explored, including energy-based models (EBMs), variational autoencoders (VAEs), generative adversarial networks (GANs), large language models (LLMs), and diffusion models. While several surveys have investigated synthetic tabular data generation, most focus on narrow subdomains or specific generative methods, such as GANs, diffusion models, or privacy-preserving techniques. This limited scope often results in fragmented insights, lacking a comprehensive synthesis that bridges diverse approaches. In particular, recent advances driven by LLMs and diffusion-based models remain underexplored. This gap hinders a holistic understanding of the field`s evolution, methodological interplay, and open challenges. To address this, our survey provides a unified and systematic review of synthetic tabular data generation. Our contributions are threefold: (1) we propose a comprehensive taxonomy that organizes existing methods into traditional approaches, diffusion-based methods, and LLM-based models, and provide an in-depth comparative analysis; (2) we detail the complete pipeline for synthetic tabular data generation, including data synthesis, post-processing, and evaluation; (3) we identify major challenges, explore real-world applications, and outline open research questions and future directions to guide future work in this rapidly evolving area.
Leveraging Submodule Linearity Enhances Task Arithmetic Performance in LLMs
Apr 15, 2025



Task arithmetic is a straightforward yet highly effective strategy for model merging, enabling the resultant model to exhibit multi-task capabilities. Recent research indicates that models demonstrating linearity enhance the performance of task arithmetic. In contrast to existing methods that rely on the global linearization of the model, we argue that this linearity already exists within the model's submodules. In particular, we present a statistical analysis and show that submodules (e.g., layers, self-attentions, and MLPs) exhibit significantly higher linearity than the overall model. Based on these findings, we propose an innovative model merging strategy that independently merges these submodules. Especially, we derive a closed-form solution for optimal merging weights grounded in the linear properties of these submodules. Experimental results demonstrate that our method consistently outperforms the standard task arithmetic approach and other established baselines across different model scales and various tasks. This result highlights the benefits of leveraging the linearity of submodules and provides a new perspective for exploring solutions for effective and practical multi-task model merging.