 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSame Evidence, Different Answers: Canonical-Context On-Policy Distillation for Multi-Turn Language Models
May 28, 2026Large language models (LLMs) often solve a task when all instructions are given in a single prompt, but fail when the same information is revealed gradually across turns. When a clean FULL prompt and a RAW-SHARDED conversation contain the same complete user evidence, the model should still arrive at the same answer. We argue that a key reason for this gap is self-anchored drift: responses produced under partial information introduce unsupported assumptions, and those assumptions later distort the final answer. To reduce this effect, we propose Canonical-Context On-Policy Distillation (CCOPD). During training, the same base model is used in two roles: a frozen teacher conditioned on the clean FULL prompt and a trainable student that receives the same evidence incrementally through a multi-turn conversation; CCOPD aligns the student's behavior on its own trajectories with the teacher's canonical full-context behavior. Trained only on math problem conversations, CCOPD yields a 32\% average relative improvement in RAW-SHARDED performance over the original base model across math and five zero-shot out-of-domain task families, while largely preserving full-context performance. Further analyses suggest that CCOPD strengthens grounding in user evidence and reduces sensitivity to contamination from earlier assistant turns.
AIR: Amortized Image Reconstruction Framework for Self-Supervised Feed-Forward 2D Gaussian Splatting
May 20, 20262D Gaussian splatting provides an efficient explicit representation for image reconstruction, but existing methods still require costly per-image iterative optimization or rely on handcrafted priors for primitive allocation. We present AIR, a self-supervised feed-forward framework that amortizes iterative Gaussian fitting into a single network pass, eliminating per-image test-time optimization. AIR adopts a stage-wise residual architecture that progressively predicts additional Gaussian primitives from reconstruction residuals, together with an explicit Stage Control mechanism that activates new primitives only in under-reconstructed regions. A Predict--Optimize--Distill training strategy stabilizes multi-stage prediction by distilling short-horizon optimized Gaussian increments back into the predictor. The stabilized predictor is then jointly finetuned across stages and equipped with an image-adaptive quantizer for compact Gaussian storage. Experiments on Kodak and DIV2K show that AIR achieves better reconstruction quality than representative Gaussian-based baselines while reducing encoding time to 160--300\,ms. Code: https://github.com/whoiszzj/AIR.git
Guiding Distribution Matching Distillation with Gradient-Based Reinforcement Learning
Apr 21, 2026Diffusion distillation, exemplified by Distribution Matching Distillation (DMD), has shown great promise in few-step generation but often sacrifices quality for sampling speed. While integrating Reinforcement Learning (RL) into distillation offers potential, a naive fusion of these two objectives relies on suboptimal raw sample evaluation. This sample-based scoring creates inherent conflicts with the distillation trajectory and produces unreliable rewards due to the noisy nature of early-stage generation. To overcome these limitations, we propose GDMD, a novel framework that redefines the reward mechanism by prioritizing distillation gradients over raw pixel outputs as the primary signal for optimization. By reinterpreting the DMD gradients as implicit target tensors, our framework enables existing reward models to directly evaluate the quality of distillation updates. This gradient-level guidance functions as an adaptive weighting that synchronizes the RL policy with the distillation objective, effectively neutralizing optimization divergence. Empirical results show that GDMD sets a new SOTA for few-step generation. Specifically, our 4-step models outperform the quality of their multi-step teacher and substantially exceed previous DMDR results in GenEval and human-preference metrics, exhibiting strong scalability potential.
SARe: Structure-Aware Large-Scale 3D Fragment Reassembly
Mar 23, 20263D fragment reassembly aims to recover the rigid poses of unordered fragment point clouds or meshes in a common object coordinate system to reconstruct the complete shape. The problem becomes particularly challenging as the number of fragments grows, since the target shape is unknown and fragments provide weak semantic cues. Existing end-to-end approaches are prone to cascading failures due to unreliable contact reasoning, most notably inaccurate fragment adjacencies. To address this, we propose Structure-Aware Reassembly (SARe), a generative framework with SARe-Gen for Euclidean-space assembly generation and SARe-Refine for inference-time refinement, with explicit contact modeling. SARe-Gen jointly predicts fracture-surface token probabilities and an inter-fragment contact graph to localize contact regions and infer candidate adjacencies. It adopts a query-point-based conditioning scheme and extracts aligned local geometric tokens at query locations from a frozen geometry encoder, yielding queryable structural representations without additional structural pretraining. We further introduce an inference-time refinement stage, SARe-Refine. By verifying candidate contact edges with geometric-consistency checks, it selects reliable substructures and resamples the remaining uncertain regions while keeping verified parts fixed, leading to more stable and consistent assemblies in the many-fragment regime. We evaluate SARe across three settings, including synthetic fractures, simulated fractures from scanned real objects, and real physically fractured scans. The results demonstrate state-of-the-art performance, with more graceful degradation and higher success rates as the fragment count increases in challenging large-scale reassembly.
Dual-End Consistency Model
Feb 11, 2026The slow iterative sampling nature remains a major bottleneck for the practical deployment of diffusion and flow-based generative models. While consistency models (CMs) represent a state-of-the-art distillation-based approach for efficient generation, their large-scale application is still limited by two key issues: training instability and inflexible sampling. Existing methods seek to mitigate these problems through architectural adjustments or regularized objectives, yet overlook the critical reliance on trajectory selection. In this work, we first conduct an analysis on these two limitations: training instability originates from loss divergence induced by unstable self-supervised term, whereas sampling inflexibility arises from error accumulation. Based on these insights and analysis, we propose the Dual-End Consistency Model (DE-CM) that selects vital sub-trajectory clusters to achieve stable and effective training. DE-CM decomposes the PF-ODE trajectory and selects three critical sub-trajectories as optimization targets. Specifically, our approach leverages continuous-time CMs objectives to achieve few-step distillation and utilizes flow matching as a boundary regularizer to stabilize the training process. Furthermore, we propose a novel noise-to-noisy (N2N) mapping that can map noise to any point, thereby alleviating the error accumulation in the first step. Extensive experimental results show the effectiveness of our method: it achieves a state-of-the-art FID score of 1.70 in one-step generation on the ImageNet 256x256 dataset, outperforming existing CM-based one-step approaches.
Part-X-MLLM: Part-aware 3D Multimodal Large Language Model
Nov 17, 2025We introduce Part-X-MLLM, a native 3D multimodal large language model that unifies diverse 3D tasks by formulating them as programs in a structured, executable grammar. Given an RGB point cloud and a natural language prompt, our model autoregressively generates a single, coherent token sequence encoding part-level bounding boxes, semantic descriptions, and edit commands. This structured output serves as a versatile interface to drive downstream geometry-aware modules for part-based generation and editing. By decoupling the symbolic planning from the geometric synthesis, our approach allows any compatible geometry engine to be controlled through a single, language-native frontend. We pre-train a dual-encoder architecture to disentangle structure from semantics and instruction-tune the model on a large-scale, part-centric dataset. Experiments demonstrate that our model excels at producing high-quality, structured plans, enabling state-of-the-art performance in grounded Q\&A, compositional generation, and localized editing through one unified interface. Project page: https://chunshi.wang/Part-X-MLLM/
TinySR: Pruning Diffusion for Real-World Image Super-Resolution
Aug 24, 2025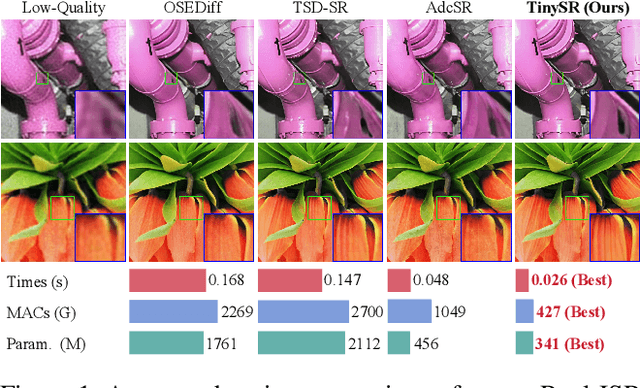
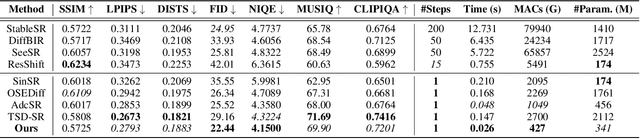
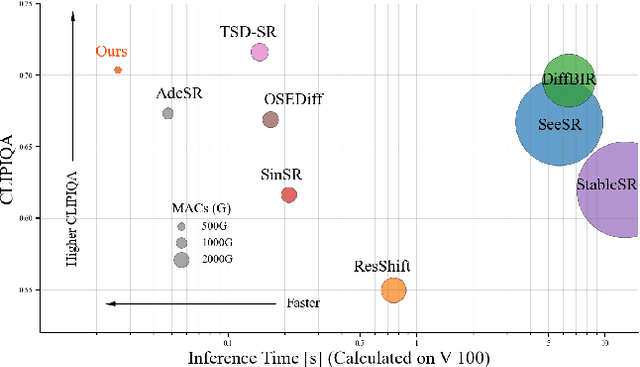
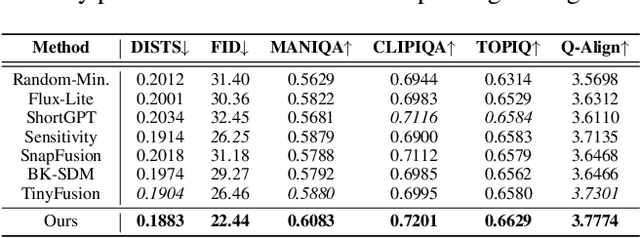
Real-world image super-resolution (Real-ISR) focuses on recovering high-quality images from low-resolution inputs that suffer from complex degradations like noise, blur, and compression. Recently, diffusion models (DMs) have shown great potential in this area by leveraging strong generative priors to restore fine details. However, their iterative denoising process incurs high computational overhead, posing challenges for real-time applications. Although one-step distillation methods, such as OSEDiff and TSD-SR, offer faster inference, they remain fundamentally constrained by their large, over-parameterized model architectures. In this work, we present TinySR, a compact yet effective diffusion model specifically designed for Real-ISR that achieves real-time performance while maintaining perceptual quality. We introduce a Dynamic Inter-block Activation and an Expansion-Corrosion Strategy to facilitate more effective decision-making in depth pruning. We achieve VAE compression through channel pruning, attention removal and lightweight SepConv. We eliminate time- and prompt-related modules and perform pre-caching techniques to further speed up the model. TinySR significantly reduces computational cost and model size, achieving up to 5.68x speedup and 83% parameter reduction compared to its teacher TSD-SR, while still providing high quality results.
ParticleGS: Particle-Based Dynamics Modeling of 3D Gaussians for Prior-free Motion Extrapolation
May 26, 2025This paper aims to model the dynamics of 3D Gaussians from visual observations to support temporal extrapolation. Existing dynamic 3D reconstruction methods often struggle to effectively learn underlying dynamics or rely heavily on manually defined physical priors, which limits their extrapolation capabilities. To address this issue, we propose a novel dynamic 3D Gaussian Splatting prior-free motion extrapolation framework based on particle dynamics systems. The core advantage of our method lies in its ability to learn differential equations that describe the dynamics of 3D Gaussians, and follow them during future frame extrapolation. Instead of simply fitting to the observed visual frame sequence, we aim to more effectively model the gaussian particle dynamics system. To this end, we introduce a dynamics latent state vector into the standard Gaussian kernel and design a dynamics latent space encoder to extract initial state. Subsequently, we introduce a Neural ODEs-based dynamics module that models the temporal evolution of Gaussian in dynamics latent space. Finally, a Gaussian kernel space decoder is used to decode latent state at the specific time step into the deformation. Experimental results demonstrate that the proposed method achieves comparable rendering quality with existing approaches in reconstruction tasks, and significantly outperforms them in future frame extrapolation. Our code is available at https://github.com/QuanJinSheng/ParticleGS.
MASTER: Multi-Agent Security Through Exploration of Roles and Topological Structures -- A Comprehensive Framework
May 24, 2025Large Language Models (LLMs)-based Multi-Agent Systems (MAS) exhibit remarkable problem-solving and task planning capabilities across diverse domains due to their specialized agentic roles and collaborative interactions. However, this also amplifies the severity of security risks under MAS attacks. To address this, we introduce MASTER, a novel security research framework for MAS, focusing on diverse Role configurations and Topological structures across various scenarios. MASTER offers an automated construction process for different MAS setups and an information-flow-based interaction paradigm. To tackle MAS security challenges in varied scenarios, we design a scenario-adaptive, extensible attack strategy utilizing role and topological information, which dynamically allocates targeted, domain-specific attack tasks for collaborative agent execution. Our experiments demonstrate that such an attack, leveraging role and topological information, exhibits significant destructive potential across most models. Additionally, we propose corresponding defense strategies, substantially enhancing MAS resilience across diverse scenarios. We anticipate that our framework and findings will provide valuable insights for future research into MAS security challenges.
DecoupledESC: Enhancing Emotional Support Generation via Strategy-Response Decoupled Preference Optimization
May 22, 2025Recent advances in Emotional Support Conversation (ESC) have improved emotional support generation by fine-tuning Large Language Models (LLMs) via Supervised Fine-Tuning (SFT). However, common psychological errors still persist. While Direct Preference Optimization (DPO) shows promise in reducing such errors through pairwise preference learning, its effectiveness in ESC tasks is limited by two key challenges: (1) Entangled data structure: Existing ESC data inherently entangles psychological strategies and response content, making it difficult to construct high-quality preference pairs; and (2) Optimization ambiguity: Applying vanilla DPO to such entangled pairwise data leads to ambiguous training objectives. To address these issues, we introduce Inferential Preference Mining (IPM) to construct high-quality preference data, forming the IPM-PrefDial dataset. Building upon this data, we propose a Decoupled ESC framework inspired by Gross's Extended Process Model of Emotion Regulation, which decomposes the ESC task into two sequential subtasks: strategy planning and empathic response generation. Each was trained via SFT and subsequently enhanced by DPO to align with the psychological preference. Extensive experiments demonstrate that our Decoupled ESC framework outperforms joint optimization baselines, reducing preference bias and improving response quality.