 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Distribution Matching Distillation with Gradient-Based Reinforcement Learning
Apr 21, 2026Diffusion distillation, exemplified by Distribution Matching Distillation (DMD), has shown great promise in few-step generation but often sacrifices quality for sampling speed. While integrating Reinforcement Learning (RL) into distillation offers potential, a naive fusion of these two objectives relies on suboptimal raw sample evaluation. This sample-based scoring creates inherent conflicts with the distillation trajectory and produces unreliable rewards due to the noisy nature of early-stage generation. To overcome these limitations, we propose GDMD, a novel framework that redefines the reward mechanism by prioritizing distillation gradients over raw pixel outputs as the primary signal for optimization. By reinterpreting the DMD gradients as implicit target tensors, our framework enables existing reward models to directly evaluate the quality of distillation updates. This gradient-level guidance functions as an adaptive weighting that synchronizes the RL policy with the distillation objective, effectively neutralizing optimization divergence. Empirical results show that GDMD sets a new SOTA for few-step generation. Specifically, our 4-step models outperform the quality of their multi-step teacher and substantially exceed previous DMDR results in GenEval and human-preference metrics, exhibiting strong scalability potential.
Dual-End Consistency Model
Feb 11, 2026The slow iterative sampling nature remains a major bottleneck for the practical deployment of diffusion and flow-based generative models. While consistency models (CMs) represent a state-of-the-art distillation-based approach for efficient generation, their large-scale application is still limited by two key issues: training instability and inflexible sampling. Existing methods seek to mitigate these problems through architectural adjustments or regularized objectives, yet overlook the critical reliance on trajectory selection. In this work, we first conduct an analysis on these two limitations: training instability originates from loss divergence induced by unstable self-supervised term, whereas sampling inflexibility arises from error accumulation. Based on these insights and analysis, we propose the Dual-End Consistency Model (DE-CM) that selects vital sub-trajectory clusters to achieve stable and effective training. DE-CM decomposes the PF-ODE trajectory and selects three critical sub-trajectories as optimization targets. Specifically, our approach leverages continuous-time CMs objectives to achieve few-step distillation and utilizes flow matching as a boundary regularizer to stabilize the training process. Furthermore, we propose a novel noise-to-noisy (N2N) mapping that can map noise to any point, thereby alleviating the error accumulation in the first step. Extensive experimental results show the effectiveness of our method: it achieves a state-of-the-art FID score of 1.70 in one-step generation on the ImageNet 256x256 dataset, outperforming existing CM-based one-step approaches.
TinySR: Pruning Diffusion for Real-World Image Super-Resolution
Aug 24, 2025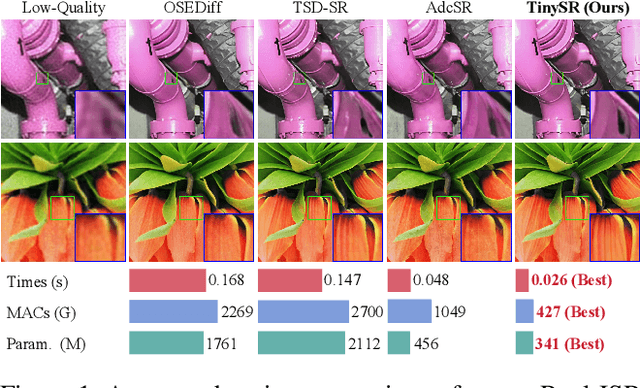
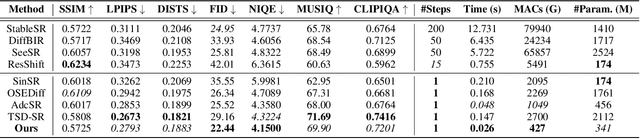
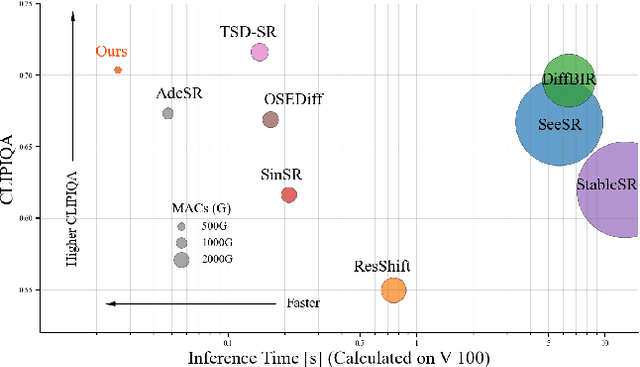
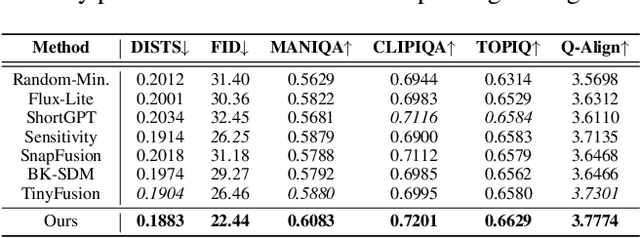
Real-world image super-resolution (Real-ISR) focuses on recovering high-quality images from low-resolution inputs that suffer from complex degradations like noise, blur, and compression. Recently, diffusion models (DMs) have shown great potential in this area by leveraging strong generative priors to restore fine details. However, their iterative denoising process incurs high computational overhead, posing challenges for real-time applications. Although one-step distillation methods, such as OSEDiff and TSD-SR, offer faster inference, they remain fundamentally constrained by their large, over-parameterized model architectures. In this work, we present TinySR, a compact yet effective diffusion model specifically designed for Real-ISR that achieves real-time performance while maintaining perceptual quality. We introduce a Dynamic Inter-block Activation and an Expansion-Corrosion Strategy to facilitate more effective decision-making in depth pruning. We achieve VAE compression through channel pruning, attention removal and lightweight SepConv. We eliminate time- and prompt-related modules and perform pre-caching techniques to further speed up the model. TinySR significantly reduces computational cost and model size, achieving up to 5.68x speedup and 83% parameter reduction compared to its teacher TSD-SR, while still providing high quality results.
TSD-SR: One-Step Diffusion with Target Score Distillation for Real-World Image Super-Resolution
Nov 27, 2024



Pre-trained text-to-image diffusion models are increasingly applied to real-world image super-resolution (Real-ISR) task. Given the iterative refinement nature of diffusion models, most existing approaches are computationally expensive. While methods such as SinSR and OSEDiff have emerged to condense inference steps via distillation, their performance in image restoration or details recovery is not satisfied. To address this, we propose TSD-SR, a novel distillation framework specifically designed for real-world image super-resolution, aiming to construct an efficient and effective one-step model. We first introduce the Target Score Distillation, which leverages the priors of diffusion models and real image references to achieve more realistic image restoration. Secondly, we propose a Distribution-Aware Sampling Module to make detail-oriented gradients more readily accessible, addressing the challenge of recovering fine details. Extensive experiments demonstrate that our TSD-SR has superior restoration results (most of the metrics perform the best) and the fastest inference speed (e.g. 40 times faster than SeeSR) compared to the past Real-ISR approaches based on pre-trained diffusion priors.