 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlocal Information Bottleneck for Time Series Imputation
Oct 06, 2025



Time Series Imputation (TSI), which aims to recover missing values in temporal data, remains a fundamental challenge due to the complex and often high-rate missingness in real-world scenarios. Existing models typically optimize the point-wise reconstruction loss, focusing on recovering numerical values (local information). However, we observe that under high missing rates, these models still perform well in the training phase yet produce poor imputations and distorted latent representation distributions (global information) in the inference phase. This reveals a critical optimization dilemma: current objectives lack global guidance, leading models to overfit local noise and fail to capture global information of the data. To address this issue, we propose a new training paradigm, Glocal Information Bottleneck (Glocal-IB). Glocal-IB is model-agnostic and extends the standard IB framework by introducing a Global Alignment loss, derived from a tractable mutual information approximation. This loss aligns the latent representations of masked inputs with those of their originally observed counterparts. It helps the model retain global structure and local details while suppressing noise caused by missing values, giving rise to better generalization under high missingness. Extensive experiments on nine datasets confirm that Glocal-IB leads to consistently improved performance and aligned latent representations under missingness. Our code implementation is available in https://github.com/Muyiiiii/NeurIPS-25-Glocal-IB.
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025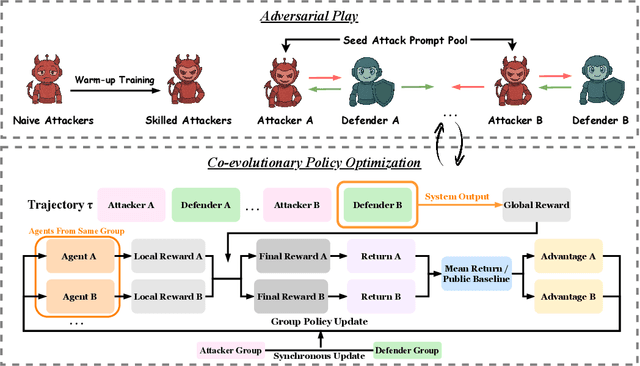

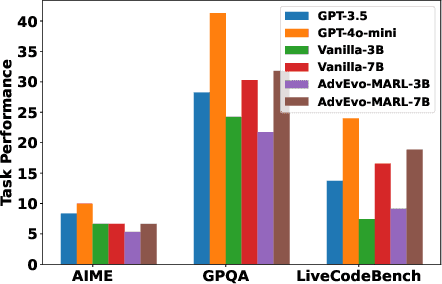
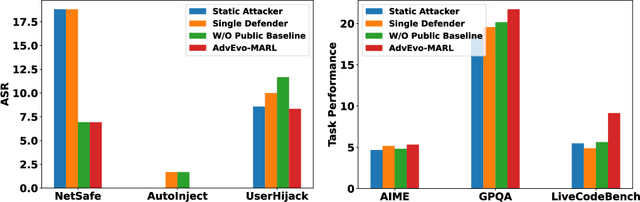
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Emotion Transfer with Enhanced Prototype for Unseen Emotion Recognition in Conversation
Aug 27, 2025



Current Emotion Recognition in Conversation (ERC) research follows a closed-domain assumption. However, there is no clear consensus on emotion classification in psychology, which presents a challenge for models when it comes to recognizing previously unseen emotions in real-world applications. To bridge this gap, we introduce the Unseen Emotion Recognition in Conversation (UERC) task for the first time and propose ProEmoTrans, a solid prototype-based emotion transfer framework. This prototype-based approach shows promise but still faces key challenges: First, implicit expressions complicate emotion definition, which we address by proposing an LLM-enhanced description approach. Second, utterance encoding in long conversations is difficult, which we tackle with a proposed parameter-free mechanism for efficient encoding and overfitting prevention. Finally, the Markovian flow nature of emotions is hard to transfer, which we address with an improved Attention Viterbi Decoding (AVD) method to transfer seen emotion transitions to unseen emotions. Extensive experiments on three datasets show that our method serves as a strong baseline for preliminary exploration in this new area.
A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Aug 12, 2025



As text generation has become a core capability of modern Large Language Models (LLMs), it underpins a wide range of downstream applications. However, most existing LLMs rely on autoregressive (AR) generation, producing one token at a time based on previously generated context-resulting in limited generation speed due to the inherently sequential nature of the process. To address this challenge, an increasing number of researchers have begun exploring parallel text generation-a broad class of techniques aimed at breaking the token-by-token generation bottleneck and improving inference efficiency. Despite growing interest, there remains a lack of comprehensive analysis on what specific techniques constitute parallel text generation and how they improve inference performance. To bridge this gap, we present a systematic survey of parallel text generation methods. We categorize existing approaches into AR-based and Non-AR-based paradigms, and provide a detailed examination of the core techniques within each category. Following this taxonomy, we assess their theoretical trade-offs in terms of speed, quality, and efficiency, and examine their potential for combination and comparison with alternative acceleration strategies. Finally, based on our findings, we highlight recent advancements, identify open challenges, and outline promising directions for future research in parallel text generation.
Dialogues Aspect-based Sentiment Quadruple Extraction via Structural Entropy Minimization Partitioning
Aug 07, 2025Dialogues Aspect-based Sentiment Quadruple Extraction (DiaASQ) aims to extract all target-aspect-opinion-sentiment quadruples from a given multi-round, multi-participant dialogue. Existing methods typically learn word relations across entire dialogues, assuming a uniform distribution of sentiment elements. However, we find that dialogues often contain multiple semantically independent sub-dialogues without clear dependencies between them. Therefore, learning word relationships across the entire dialogue inevitably introduces additional noise into the extraction process. To address this, our method focuses on partitioning dialogues into semantically independent sub-dialogues. Achieving completeness while minimizing these sub-dialogues presents a significant challenge. Simply partitioning based on reply relationships is ineffective. Instead, we propose utilizing a structural entropy minimization algorithm to partition the dialogues. This approach aims to preserve relevant utterances while distinguishing irrelevant ones as much as possible. Furthermore, we introduce a two-step framework for quadruple extraction: first extracting individual sentiment elements at the utterance level, then matching quadruples at the sub-dialogue level. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in DiaASQ with much lower computational costs.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
DP-DGAD: A Generalist Dynamic Graph Anomaly Detector with Dynamic Prototypes
Aug 01, 2025



Dynamic graph anomaly detection (DGAD) is essential for identifying anomalies in evolving graphs across domains such as finance, traffic, and social networks. Recently, generalist graph anomaly detection (GAD) models have shown promising results. They are pretrained on multiple source datasets and generalize across domains. While effective on static graphs, they struggle to capture evolving anomalies in dynamic graphs. Moreover, the continuous emergence of new domains and the lack of labeled data further challenge generalist DGAD. Effective cross-domain DGAD requires both domain-specific and domain-agnostic anomalous patterns. Importantly, these patterns evolve temporally within and across domains. Building on these insights, we propose a DGAD model with Dynamic Prototypes (DP) to capture evolving domain-specific and domain-agnostic patterns. Firstly, DP-DGAD extracts dynamic prototypes, i.e., evolving representations of normal and anomalous patterns, from temporal ego-graphs and stores them in a memory buffer. The buffer is selectively updated to retain general, domain-agnostic patterns while incorporating new domain-specific ones. Then, an anomaly scorer compares incoming data with dynamic prototypes to flag both general and domain-specific anomalies. Finally, DP-DGAD employs confidence-based pseudo-labeling for effective self-supervised adaptation in target domains. Extensive experiments demonstrate state-of-the-art performance across ten real-world datasets from different domains.
SGCL: Unifying Self-Supervised and Supervised Learning for Graph Recommendation
Jul 17, 2025Recommender systems (RecSys) are essential for online platforms, providing personalized suggestions to users within a vast sea of information. Self-supervised graph learning seeks to harness high-order collaborative filtering signals through unsupervised augmentation on the user-item bipartite graph, primarily leveraging a multi-task learning framework that includes both supervised recommendation loss and self-supervised contrastive loss. However, this separate design introduces additional graph convolution processes and creates inconsistencies in gradient directions due to disparate losses, resulting in prolonged training times and sub-optimal performance. In this study, we introduce a unified framework of Supervised Graph Contrastive Learning for recommendation (SGCL) to address these issues. SGCL uniquely combines the training of recommendation and unsupervised contrastive losses into a cohesive supervised contrastive learning loss, aligning both tasks within a single optimization direction for exceptionally fast training. Extensive experiments on three real-world datasets show that SGCL outperforms state-of-the-art methods, achieving superior accuracy and efficiency.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
A Gravity-informed Spatiotemporal Transformer for Human Activity Intensity Prediction
Jun 16, 2025Human activity intensity prediction is a crucial to many location-based services. Although tremendous progress has been made to model dynamic spatiotemporal patterns of human activity, most existing methods, including spatiotemporal graph neural networks (ST-GNNs), overlook physical constraints of spatial interactions and the over-smoothing phenomenon in spatial correlation modeling. To address these limitations, this work proposes a physics-informed deep learning framework, namely Gravity-informed Spatiotemporal Transformer (Gravityformer) by refining transformer attention to integrate the universal law of gravitation and explicitly incorporating constraints from spatial interactions. Specifically, it (1) estimates two spatially explicit mass parameters based on inflow and outflow, (2) models the likelihood of cross-unit interaction using closed-form solutions of spatial interactions to constrain spatial modeling randomness, and (3) utilizes the learned spatial interaction to guide and mitigate the over-smoothing phenomenon in transformer attention matrices. The underlying law of human activity can be explicitly modeled by the proposed adaptive gravity model. Moreover, a parallel spatiotemporal graph convolution transformer structure is proposed for achieving a balance between coupled spatial and temporal learning. Systematic experiments on six real-world large-scale activity datasets demonstrate the quantitative and qualitative superiority of our approach over state-of-the-art benchmarks. Additionally, the learned gravity attention matrix can be disentangled and interpreted based on geographical laws. This work provides a novel insight into integrating physical laws with deep learning for spatiotemporal predictive learning.