 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025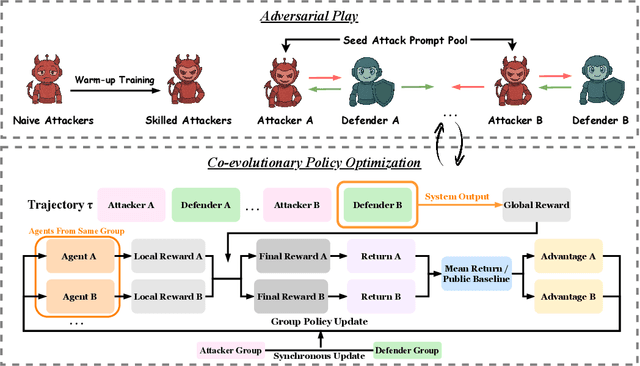

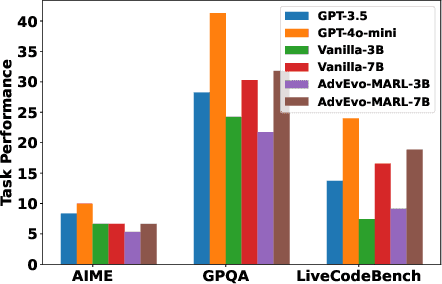
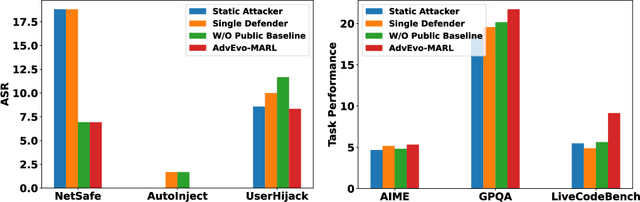
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Evo-MARL: Co-Evolutionary Multi-Agent Reinforcement Learning for Internalized Safety
Aug 05, 2025


Multi-agent systems (MAS) built on multimodal large language models exhibit strong collaboration and performance. However, their growing openness and interaction complexity pose serious risks, notably jailbreak and adversarial attacks. Existing defenses typically rely on external guard modules, such as dedicated safety agents, to handle unsafe behaviors. Unfortunately, this paradigm faces two challenges: (1) standalone agents offer limited protection, and (2) their independence leads to single-point failure-if compromised, system-wide safety collapses. Naively increasing the number of guard agents further raises cost and complexity. To address these challenges, we propose Evo-MARL, a novel multi-agent reinforcement learning (MARL) framework that enables all task agents to jointly acquire defensive capabilities. Rather than relying on external safety modules, Evo-MARL trains each agent to simultaneously perform its primary function and resist adversarial threats, ensuring robustness without increasing system overhead or single-node failure. Furthermore, Evo-MARL integrates evolutionary search with parameter-sharing reinforcement learning to co-evolve attackers and defenders. This adversarial training paradigm internalizes safety mechanisms and continually enhances MAS performance under co-evolving threats. Experiments show that Evo-MARL reduces attack success rates by up to 22% while boosting accuracy by up to 5% on reasoning tasks-demonstrating that safety and utility can be jointly improved.
Cold-Start Recommendation with Knowledge-Guided Retrieval-Augmented Generation
May 27, 2025Cold-start items remain a persistent challenge in recommender systems due to their lack of historical user interactions, which collaborative models rely on. While recent zero-shot methods leverage large language models (LLMs) to address this, they often struggle with sparse metadata and hallucinated or incomplete knowledge. We propose ColdRAG, a retrieval-augmented generation approach that builds a domain-specific knowledge graph dynamically to enhance LLM-based recommendation in cold-start scenarios, without requiring task-specific fine-tuning. ColdRAG begins by converting structured item attributes into rich natural-language profiles, from which it extracts entities and relationships to construct a unified knowledge graph capturing item semantics. Given a user's interaction history, it scores edges in the graph using an LLM, retrieves candidate items with supporting evidence, and prompts the LLM to rank them. By enabling multi-hop reasoning over this graph, ColdRAG grounds recommendations in verifiable evidence, reducing hallucinations and strengthening semantic connections. Experiments on three public benchmarks demonstrate that ColdRAG surpasses existing zero-shot baselines in both Recall and NDCG. This framework offers a practical solution to cold-start recommendation by combining knowledge-graph reasoning with retrieval-augmented LLM generation.
Cost Aware Untargeted Poisoning Attack against Graph Neural Networks,
Dec 12, 2023



Graph Neural Networks (GNNs) have become widely used in the field of graph mining. However, these networks are vulnerable to structural perturbations. While many research efforts have focused on analyzing vulnerability through poisoning attacks, we have identified an inefficiency in current attack losses. These losses steer the attack strategy towards modifying edges targeting misclassified nodes or resilient nodes, resulting in a waste of structural adversarial perturbation. To address this issue, we propose a novel attack loss framework called the Cost Aware Poisoning Attack (CA-attack) to improve the allocation of the attack budget by dynamically considering the classification margins of nodes. Specifically, it prioritizes nodes with smaller positive margins while postponing nodes with negative margins. Our experiments demonstrate that the proposed CA-attack significantly enhances existing attack strategies