 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards In-Depth Root Cause Localization for Microservices with Multi-Agent Recursion-of-Thought
May 14, 2026As modern microservice systems grow increasingly complex due to dynamic interactions and evolving runtime environments, they experience failures with rising frequency. Ensuring system reliability therefore critically depends on accurate root cause localization (RCL). While numerous traditional machine learning and deep learning approaches have been explored for this task, they often suffer from limited interpretability and poor transferability across deployments. More recently, large language model (LLM)-based methods have been proposed to address these issues. However, existing LLM-based approaches still face two fundamental limitations: context explosion, which dilutes critical evidence and degrades localization accuracy, and serial reasoning structures, which hinder deep causal exploration and impair inference efficiency. In this paper, we conduct a comprehensive study of both how human SREs perform root cause localization in practice and why existing LLM-based methods fall short. Motivated by these findings, we introduce RCLAgent, an in-depth root cause localization framework for microservice systems that realizes multi-agent recursion-of-thought with parallel reasoning. RCLAgent decomposes the diagnostic process along the trace graph by assigning each span to a Dedicated Agent and organizing agents recursively and in parallel according to the graph topology, with the final diagnosis obtained by synthesizing the Root-Level Diagnosis Report and the Global Evidence Graph. Extensive experiments on multiple public benchmarks demonstrate that RCLAgent consistently outperforms state-of-the-art methods in both localization accuracy and inference efficiency.
Towards Robust LLM Post-Training: Automatic Failure Management for Reinforcement Fine-Tuning
May 06, 2026Reinforcement fine-tuning (RFT) has become a core paradigm for post-training large language models, yet its training process remains highly fragile. Existing efforts mainly improve reliability at the system level or address specific issues in individual subproblems by modifying RFT algorithms. Despite their effectiveness, they largely overlook the problem of failure management at the training-process level. When training goes wrong, practitioners still rely heavily on expert-driven manual inspection and correction, and automatic failure management for RFT remains largely unexplored. In this paper, we take a first step toward systematic failure management for reinforcement fine-tuning. To understand the empirical structure of RFT failures, we first construct RFT-FaultBench, the first benchmark for fine-grained failures in reinforcement fine-tuning, covering 5 fault families, 16 fault types, 779 training runs, 22,549 train-step records, and 1,457,288 trajectory-level records. Based on this benchmark, we conduct a comprehensive empirical study showing that RFT failures are both observable from training dynamics and distinguishable through their empirical fault fingerprints. Building on these findings, we propose RFT-FM, an automatic failure management framework for reinforcement fine-tuning that unifies anomaly detection, failure diagnosis, and auto remediation in a closed loop. Experimental results show that RFT-FaultBench is neither trivial nor saturated: it exhibits clear anomaly structure while still posing substantial challenges, especially under subtle fault settings. Moreover, RFT-FM shows strong capability in detecting, diagnosing, and mitigating RFT failures.
E2E-REME: Towards End-to-End Microservices Auto-Remediation via Experience-Simulation Reinforcement Fine-Tuning
Apr 13, 2026Contemporary microservice systems continue to grow in scale and complexity, leading to increasingly frequent and costly failures. While recent LLM-based auto-remediation approaches have emerged, they primarily translate textual instructions into executable Ansible playbooks and rely on expert-crafted prompts, lacking runtime knowledge guidance and depending on large-scale general-purpose LLMs, which limits their accuracy and efficiency. We introduce \textit{End-to-End Microservice Remediation} (E2E-MR), a new task that requires directly generating executable playbooks from diagnosis reports to autonomously restore faulty systems. To enable rigorous evaluation, we build \textit{MicroRemed}, a benchmark that automates microservice deployment, failure injection, playbook execution, and post-repair verification. We further propose \textit{E2E-REME}, an end-to-end auto-remediation model trained via experience-simulation reinforcement fine-tuning. Experiments on public and industrial microservice platforms, compared with nine representative LLMs, show that E2E-REME achieves superior accuracy and efficiency.
Efficient Failure Management for Multi-Agent Systems with Reasoning Trace Representation
Mar 23, 2026Large Language Models (LLM)-based Multi-Agent Systems (MASs) have emerged as a new paradigm in software system design, increasingly demonstrating strong reasoning and collaboration capabilities. As these systems become more complex and autonomous, effective failure management is essential to ensure reliability and availability. However, existing approaches often rely on per-trace reasoning, which leads to low efficiency, and neglect historical failure patterns, limiting diagnostic accuracy. In this paper, we conduct a preliminary empirical study to demonstrate the necessity, potential, and challenges of leveraging historical failure patterns to enhance failure management in MASs. Building on this insight, we propose \textbf{EAGER}, an efficient failure management framework for multi-agent systems based on reasoning trace representation. EAGER employs unsupervised reasoning-scoped contrastive learning to encode both intra-agent reasoning and inter-agent coordination, enabling real-time step-wise failure detection, diagnosis, and reflexive mitigation guided by historical failure knowledge. Preliminary evaluations on three open-source MASs demonstrate the effectiveness of EAGER and highlight promising directions for future research in reliable multi-agent system operations.
RuntimeSlicer: Towards Generalizable Unified Runtime State Representation for Failure Management
Mar 23, 2026Modern software systems operate at unprecedented scale and complexity, where effective failure management is critical yet increasingly challenging. Metrics, traces, and logs provide complementary views of system runtime behavior, but existing failure management approaches typically rely on task-oriented pipelines that tightly couple modality-specific preprocessing, representation learning, and downstream models, resulting in limited generalization across tasks and systems. To fill this gap, we propose RuntimeSlicer, a unified runtime state representation model towards generalizable failure management. RuntimeSlicer pre-trains a task-agnostic representation model that directly encodes metrics, traces, and logs into a single, aligned system-state embedding capturing the holistic runtime condition of the system. To train RuntimeSlicer, we introduce Unified Runtime Contrastive Learning, which integrates heterogeneous training data sources and optimizes complementary objectives for cross-modality alignment and temporal consistency. Building upon the learned system-state embeddings, we further propose State-Aware Task-Oriented Tuning, which performs unsupervised partitioning of runtime states and enables state-conditioned adaptation for downstream tasks. This design allows lightweight task-oriented models to be trained on top of the unified embedding without redesigning modality-specific encoders or preprocessing pipelines. Preliminary experiments on the AIOps 2022 dataset demonstrate the feasibility and effectiveness of RuntimeSlicer for system state modeling and failure management tasks.
Hypothesize-Then-Verify: Speculative Root Cause Analysis for Microservices with Pathwise Parallelism
Jan 06, 2026Microservice systems have become the backbone of cloud-native enterprise applications due to their resource elasticity, loosely coupled architecture, and lightweight deployment. Yet, the intrinsic complexity and dynamic runtime interactions of such systems inevitably give rise to anomalies. Ensuring system reliability therefore hinges on effective root cause analysis (RCA), which entails not only localizing the source of anomalies but also characterizing the underlying failures in a timely and interpretable manner. Recent advances in intelligent RCA techniques, particularly those powered by large language models (LLMs), have demonstrated promising capabilities, as LLMs reduce reliance on handcrafted features while offering cross-platform adaptability, task generalization, and flexibility. However, existing LLM-based methods still suffer from two critical limitations: (a) limited exploration diversity, which undermines accuracy, and (b) heavy dependence on large-scale LLMs, which results in slow inference. To overcome these challenges, we propose SpecRCA, a speculative root cause analysis framework for microservices that adopts a \textit{hypothesize-then-verify} paradigm. SpecRCA first leverages a hypothesis drafting module to rapidly generate candidate root causes, and then employs a parallel root cause verifier to efficiently validate them. Preliminary experiments on the AIOps 2022 dataset demonstrate that SpecRCA achieves superior accuracy and efficiency compared to existing approaches, highlighting its potential as a practical solution for scalable and interpretable RCA in complex microservice environments.
Agentic Memory Enhanced Recursive Reasoning for Root Cause Localization in Microservices
Jan 06, 2026As contemporary microservice systems become increasingly popular and complex-often comprising hundreds or even thousands of fine-grained, interdependent subsystems-they are experiencing more frequent failures. Ensuring system reliability thus demands accurate root cause localization. While many traditional graph-based and deep learning approaches have been explored for this task, they often rely heavily on pre-defined schemas that struggle to adapt to evolving operational contexts. Consequently, a number of LLM-based methods have recently been proposed. However, these methods still face two major limitations: shallow, symptom-centric reasoning that undermines accuracy, and a lack of cross-alert reuse that leads to redundant reasoning and high latency. In this paper, we conduct a comprehensive study of how Site Reliability Engineers (SREs) localize the root causes of failures, drawing insights from professionals across multiple organizations. Our investigation reveals that expert root cause analysis exhibits three key characteristics: recursiveness, multi-dimensional expansion, and cross-modal reasoning. Motivated by these findings, we introduce AMER-RCL, an agentic memory enhanced recursive reasoning framework for root cause localization in microservices. AMER-RCL employs the Recursive Reasoning RCL engine, a multi-agent framework that performs recursive reasoning on each alert to progressively refine candidate causes, while Agentic Memory incrementally accumulates and reuses reasoning from prior alerts within a time window to reduce redundant exploration and lower inference latency. Experimental results demonstrate that AMER-RCL consistently outperforms state-of-the-art methods in both localization accuracy and inference efficiency.
d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
Dec 10, 2025Reliable reinforcement learning (RL) for diffusion large language models (dLLMs) requires both accurate advantage estimation and precise estimation of prediction probabilities. Existing RL methods for dLLMs fall short in both aspects: they rely on coarse or unverifiable reward signals, and they estimate prediction probabilities without accounting for the bias relative to the true, unbiased expected prediction probability that properly integrates over all possible decoding orders. To mitigate these issues, we propose \emph{d}-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. When estimating the conditional transition probability from a parent node to a child node, we theoretically analyze the estimation error between the unbiased expected prediction probability and the estimate obtained via a single forward pass, and find that higher prediction confidence leads to lower estimation error. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and improved convergence. Experiments show that \emph{d}-TreeRPO outperforms existing baselines and achieves significant gains on multiple reasoning benchmarks, including +86.2 on Sudoku, +51.6 on Countdown, +4.5 on GSM8K, and +5.3 on Math500. Ablation studies and computational cost analyses further demonstrate the effectiveness and practicality of our design choices.
A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Aug 12, 2025



As text generation has become a core capability of modern Large Language Models (LLMs), it underpins a wide range of downstream applications. However, most existing LLMs rely on autoregressive (AR) generation, producing one token at a time based on previously generated context-resulting in limited generation speed due to the inherently sequential nature of the process. To address this challenge, an increasing number of researchers have begun exploring parallel text generation-a broad class of techniques aimed at breaking the token-by-token generation bottleneck and improving inference efficiency. Despite growing interest, there remains a lack of comprehensive analysis on what specific techniques constitute parallel text generation and how they improve inference performance. To bridge this gap, we present a systematic survey of parallel text generation methods. We categorize existing approaches into AR-based and Non-AR-based paradigms, and provide a detailed examination of the core techniques within each category. Following this taxonomy, we assess their theoretical trade-offs in terms of speed, quality, and efficiency, and examine their potential for combination and comparison with alternative acceleration strategies. Finally, based on our findings, we highlight recent advancements, identify open challenges, and outline promising directions for future research in parallel text generation.
Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025
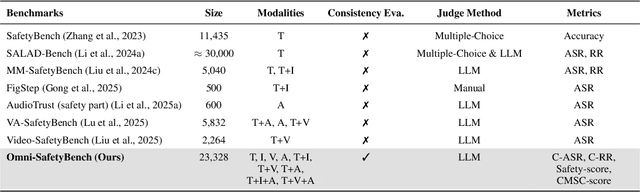

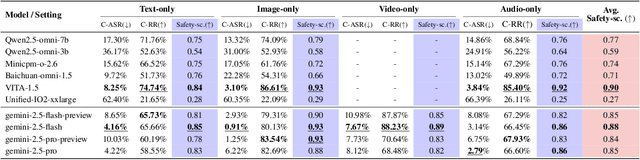
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.