 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents-K1: Towards Agent-native Knowledge Orchestration
Jun 11, 2026Current LLM-based research agents have advanced through agent orchestration, yet largely overlook scientific knowledge orchestration. Existing works often reduce papers to abstracts, surface mentions, and flat \texttt{cites} edges, omitting key entities, claims, evidence, mechanisms, and method lineages essential for scientific reasoning. To this end, we introduce \textbf{Agents-K1}, an end-to-end knowledge orchestration pipeline that converts raw documents into agent-native scientific knowledge graphs. Agents-K1 integrates three components under a unifying theoretical foundation: a multimodal parser whose five-module schema captures entities, multimodal evidence, citations, and typed inter-entity relations across the full paper rather than abstracts alone; a 4B information-extraction backbone trained with GRPO under a rule-based reward; and a graphanything CLI, a tri-source agent interface that unifies web search, multimodal graph retrieval, and cross-document traversal. On top of this, we process 2.46 million scientific papers across six subjects to produce \textbf{Scholar-KG}, of which we release a one-million-paper subset, and the full Scholar-KG is accessible via the SCP link below. The same pipeline can be extended to general-domain corpora and to schema-conformant data synthesis. Extensive experiments demonstrate that Agents-K1 achieves superior performance in scientific information extraction, knowledge graph construction, and multi-hop scientific reasoning.
Style or Content? Evaluating Style Classifiers with Controlled Content Overlap
Jun 05, 2026Style classifiers can use content cues that correlate with style labels in naturally collected data, yet we lack a systematic way to measure this reliance. We study this problem with a controlled content overlap setup built on parallel Bible translations. Specifically, we define the overlap parameter $α$ as the normalized residual of mutual information between content identity and style label, so that it measures how much content is shared across style classes: from no shared content ($α=0$) to fully shared content ($α=1$). Cross-overlap evaluation of RoBERTa-based classifiers shows that low-overlap models degrade when content cues are removed, while high-overlap models transfer more robustly. A cross-style content retrieval probe further shows that content becomes less recoverable as $α$ increases, with training dynamics showing this removal occurs gradually. Together, these results suggest that controlled overlap provides a simple diagnostic for separating style learning from content shortcuts.
RABot: Reinforcement-Guided Graph Augmentation for Imbalanced and Noisy Social Bot Detection
Feb 25, 2026Social bot detection is pivotal for safeguarding the integrity of online information ecosystems. Although recent graph neural network (GNN) solutions achieve strong results, they remain hindered by two practical challenges: (i) severe class imbalance arising from the high cost of generating bots, and (ii) topological noise introduced by bots that skillfully mimic human behavior and forge deceptive links. We propose the Reinforcement-guided graph Augmentation social Bot detector (RABot), a multi-granularity graph-augmentation framework that addresses both issues in a unified manner. RABot employs a neighborhood-aware oversampling strategy that linearly interpolates minority-class embeddings within local subgraphs, thereby stabilizing the decision boundary under low-resource regimes. Concurrently, a reinforcement-learning-driven edge-filtering module combines similarity-based edge features with adaptive threshold optimization to excise spurious interactions during message passing, yielding a cleaner topology. Extensive experiments on three real-world benchmarks and four GNN backbones demonstrate that RABot consistently surpasses state-of-the-art baselines. In addition, since its augmentation and filtering modules are orthogonal to the underlying architecture, RABot can be seamlessly integrated into existing GNN pipelines to boost performance with minimal overhead.
EpicCBR: Item-Relation-Enhanced Dual-Scenario Contrastive Learning for Cold-Start Bundle Recommendation
Feb 12, 2026Bundle recommendation aims to recommend a set of items to users for overall consumption. Existing bundle recommendation models primarily depend on observed user-bundle interactions, limiting exploration of newly-emerged bundles that are constantly created. It pose a critical representation challenge for current bundle methods, as they usually treat each bundle as an independent instance, while neglecting to fully leverage the user-item (UI) and bundle-item (BI) relations over popular items. To alleviate it, in this paper we propose a multi-view contrastive learning framework for cold-start bundle recommendation, named EpicCBR. Specifically, it precisely mine and utilize the item relations to construct user profiles, identifying users likely to engage with bundles. Additionally, a popularity-based method that characterizes the features of new bundles through historical bundle information and user preferences is proposed. To build a framework that demonstrates robustness in both cold-start and warm-start scenarios, a multi-view graph contrastive learning framework capable of integrating these diverse scenarios is introduced to ensure the model's generalization capability. Extensive experiments conducted on three popular benchmarks showed that EpicCBR outperforms state-of-the-art by a large margin (up to 387%), sufficiently demonstrating the superiority of the proposed method in cold-start scenario. The code and dataset can be found in the GitHub repository: https://github.com/alexlovecoding/EpicCBR.
RL-MTJail: Reinforcement Learning for Automated Black-Box Multi-Turn Jailbreaking of Large Language Models
Dec 08, 2025Large language models are vulnerable to jailbreak attacks, threatening their safe deployment in real-world applications. This paper studies black-box multi-turn jailbreaks, aiming to train attacker LLMs to elicit harmful content from black-box models through a sequence of prompt-output interactions. Existing approaches typically rely on single turn optimization, which is insufficient for learning long-term attack strategies. To bridge this gap, we formulate the problem as a multi-turn reinforcement learning task, directly optimizing the harmfulness of the final-turn output as the outcome reward. To mitigate sparse supervision and promote long-term attack strategies, we propose two heuristic process rewards: (1) controlling the harmfulness of intermediate outputs to prevent triggering the black-box model's rejection mechanisms, and (2) maintaining the semantic relevance of intermediate outputs to avoid drifting into irrelevant content. Experimental results on multiple benchmarks show consistently improved attack success rates across multiple models, highlighting the effectiveness of our approach. The code is available at https://github.com/xxiqiao/RL-MTJail. Warning: This paper contains examples of harmful content.
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025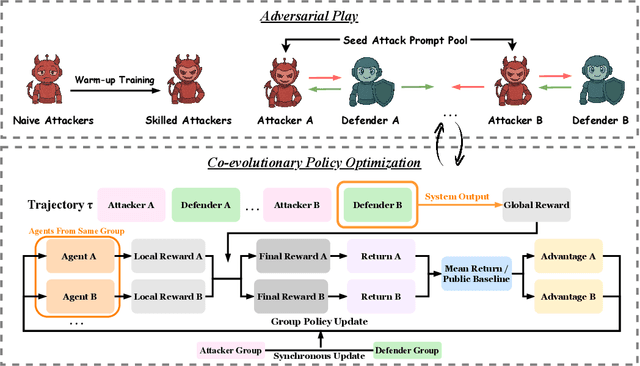

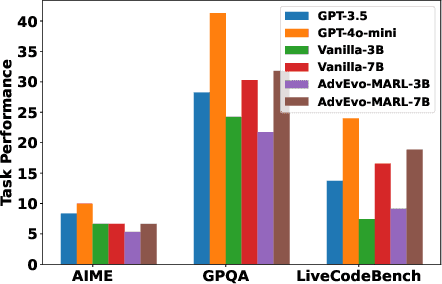
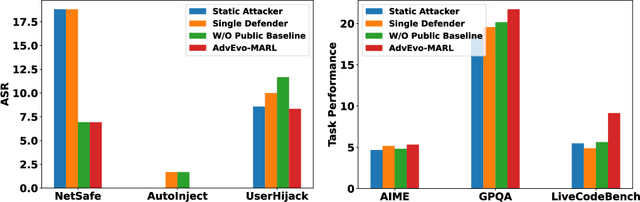
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
Assistant-Guided Mitigation of Teacher Preference Bias in LLM-as-a-Judge
May 25, 2025LLM-as-a-Judge employs large language models (LLMs), such as GPT-4, to evaluate the quality of LLM-generated responses, gaining popularity for its cost-effectiveness and strong alignment with human evaluations. However, training proxy judge models using evaluation data generated by powerful teacher models introduces a critical yet previously overlooked issue: teacher preference bias, where the proxy judge model learns a biased preference for responses from the teacher model. To tackle this problem, we propose a novel setting that incorporates an additional assistant model, which is not biased toward the teacher model's responses, to complement the training data. Building on this setup, we introduce AGDe-Judge, a three-stage framework designed to debias from both the labels and feedbacks in the training data. Extensive experiments demonstrate that AGDe-Judge effectively reduces teacher preference bias while maintaining strong performance across six evaluation benchmarks. Code is available at https://github.com/Liuz233/AGDe-Judge.
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Self-Improvement Towards Pareto Optimality: Mitigating Preference Conflicts in Multi-Objective Alignment
Feb 20, 2025



Multi-Objective Alignment (MOA) aims to align LLMs' responses with multiple human preference objectives, with Direct Preference Optimization (DPO) emerging as a prominent approach. However, we find that DPO-based MOA approaches suffer from widespread preference conflicts in the data, where different objectives favor different responses. This results in conflicting optimization directions, hindering the optimization on the Pareto Front. To address this, we propose to construct Pareto-optimal responses to resolve preference conflicts. To efficiently obtain and utilize such responses, we propose a self-improving DPO framework that enables LLMs to self-generate and select Pareto-optimal responses for self-supervised preference alignment. Extensive experiments on two datasets demonstrate the superior Pareto Front achieved by our framework compared to various baselines. Code is available at \url{https://github.com/zyttt-coder/SIPO}.
Mitigating Hallucinations in Multimodal Spatial Relations through Constraint-Aware Prompting
Feb 12, 2025Spatial relation hallucinations pose a persistent challenge in large vision-language models (LVLMs), leading to generate incorrect predictions about object positions and spatial configurations within an image. To address this issue, we propose a constraint-aware prompting framework designed to reduce spatial relation hallucinations. Specifically, we introduce two types of constraints: (1) bidirectional constraint, which ensures consistency in pairwise object relations, and (2) transitivity constraint, which enforces relational dependence across multiple objects. By incorporating these constraints, LVLMs can produce more spatially coherent and consistent outputs. We evaluate our method on three widely-used spatial relation datasets, demonstrating performance improvements over existing approaches. Additionally, a systematic analysis of various bidirectional relation analysis choices and transitivity reference selections highlights greater possibilities of our methods in incorporating constraints to mitigate spatial relation hallucinations.