 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLCSD: Reinforcement Learning with Contrastive On-Policy Self-Distillation
Jun 10, 2026On-policy self-distillation (OPSD) provides dense, token-level supervision for reasoning models by aligning a model's own distribution with the distribution it produces under privileged context, typically a verified solution. However, we show that the learning signal drawn from this distributional gap concentrates on style tokens rather than task-bearing ones, as the hinted model tends to produce more direct, shorter outputs. We term this pathology \emph{privilege-induced style drift}, which destabilizes training or causes response length to shrink. To address this, we propose \textbf{RLCSD} (Reinforcement Learning with Contrastive on-policy Self-Distillation), which mitigates this drift by contrasting the teacher-student gap under a correct hint against that under a wrong hint, suppressing the style shift that conditioning on a hint tends to induce regardless of correctness, and yielding a signal that is more concentrated on task-bearing tokens. Experiments on Qwen3 (1.7B/4B/8B) and Olmo-3-7B-Think across mathematical and logical reasoning show that RLCSD consistently outperforms GRPO and prior OPSD methods. We further show that the contrastive principle is general: it plugs into existing OPSD methods to improve them, and its underlying insight extends to the broader cross-model on-policy distillation setting.
Baichuan-M4: A Clinical-Grade Medical Agent System for Continuous Care
Jun 09, 2026Baichuan-M4 is Baichuan Intelligence's clinical-grade medical large model, designed for continuous care rather than single-turn medical question answering. It is built as a coordinated medical agent system around three pillars: Baichuan-Harness, a unified runtime that keeps reinforcement-learning training and real-world deployment consistent while enforcing action constraints, tool use, long-term patient memory, and multi-agent coordination; a core reasoning model trained with a continuous-care reinforcement-learning framework that integrates span-level reward modeling (SPAR++), reasoning-path compression, curriculum learning, and stabilized policy optimization; and a clinical tool layer for patient-memory management, authoritative evidence-based retrieval, and multimodal medical perception across documents, X-rays, and dermatology. On a cross-dimensional medical evaluation suite, Baichuan-M4 attains leading results in static medical knowledge and safety, dynamic OSCE-style consultation, long-context clinical memory, evidence-based retrieval, medical document OCR, and multimodal image understanding, while lowering the hallucination rate to 3.3%.
Locally Confident, Globally Stuck: The Quality-Exploration Dilemma in Diffusion Language Models
Apr 01, 2026Diffusion large language models (dLLMs) theoretically permit token decoding in arbitrary order, a flexibility that could enable richer exploration of reasoning paths than autoregressive (AR) LLMs. In practice, however, random-order decoding often hurts generation quality. To mitigate this, low-confidence remasking improves single-sample quality (e.g., Pass@$1$) by prioritizing confident tokens, but it also suppresses exploration and limits multi-sample gains (e.g., Pass@$k$), creating a fundamental quality--exploration dilemma. In this paper, we provide a unified explanation of this dilemma. We show that low-confidence remasking improves a myopic proxy for quality while provably constraining the entropy of the induced sequence distribution. To overcome this limitation, we characterize the optimal distribution that explicitly balances quality and exploration, and develop a simple Independent Metropolis--Hastings sampler that approximately targets this distribution during decoding. Experiments across a range of reasoning benchmarks including MATH500, AIME24/25, HumanEval, and MBPP show that our approach yields better exploration-quality tradeoff than both random and low-confidence remasking.
Agentic Memory Enhanced Recursive Reasoning for Root Cause Localization in Microservices
Jan 06, 2026As contemporary microservice systems become increasingly popular and complex-often comprising hundreds or even thousands of fine-grained, interdependent subsystems-they are experiencing more frequent failures. Ensuring system reliability thus demands accurate root cause localization. While many traditional graph-based and deep learning approaches have been explored for this task, they often rely heavily on pre-defined schemas that struggle to adapt to evolving operational contexts. Consequently, a number of LLM-based methods have recently been proposed. However, these methods still face two major limitations: shallow, symptom-centric reasoning that undermines accuracy, and a lack of cross-alert reuse that leads to redundant reasoning and high latency. In this paper, we conduct a comprehensive study of how Site Reliability Engineers (SREs) localize the root causes of failures, drawing insights from professionals across multiple organizations. Our investigation reveals that expert root cause analysis exhibits three key characteristics: recursiveness, multi-dimensional expansion, and cross-modal reasoning. Motivated by these findings, we introduce AMER-RCL, an agentic memory enhanced recursive reasoning framework for root cause localization in microservices. AMER-RCL employs the Recursive Reasoning RCL engine, a multi-agent framework that performs recursive reasoning on each alert to progressively refine candidate causes, while Agentic Memory incrementally accumulates and reuses reasoning from prior alerts within a time window to reduce redundant exploration and lower inference latency. Experimental results demonstrate that AMER-RCL consistently outperforms state-of-the-art methods in both localization accuracy and inference efficiency.
Hypothesize-Then-Verify: Speculative Root Cause Analysis for Microservices with Pathwise Parallelism
Jan 06, 2026Microservice systems have become the backbone of cloud-native enterprise applications due to their resource elasticity, loosely coupled architecture, and lightweight deployment. Yet, the intrinsic complexity and dynamic runtime interactions of such systems inevitably give rise to anomalies. Ensuring system reliability therefore hinges on effective root cause analysis (RCA), which entails not only localizing the source of anomalies but also characterizing the underlying failures in a timely and interpretable manner. Recent advances in intelligent RCA techniques, particularly those powered by large language models (LLMs), have demonstrated promising capabilities, as LLMs reduce reliance on handcrafted features while offering cross-platform adaptability, task generalization, and flexibility. However, existing LLM-based methods still suffer from two critical limitations: (a) limited exploration diversity, which undermines accuracy, and (b) heavy dependence on large-scale LLMs, which results in slow inference. To overcome these challenges, we propose SpecRCA, a speculative root cause analysis framework for microservices that adopts a \textit{hypothesize-then-verify} paradigm. SpecRCA first leverages a hypothesis drafting module to rapidly generate candidate root causes, and then employs a parallel root cause verifier to efficiently validate them. Preliminary experiments on the AIOps 2022 dataset demonstrate that SpecRCA achieves superior accuracy and efficiency compared to existing approaches, highlighting its potential as a practical solution for scalable and interpretable RCA in complex microservice environments.
d-TreeRPO: Towards More Reliable Policy Optimization for Diffusion Language Models
Dec 10, 2025Reliable reinforcement learning (RL) for diffusion large language models (dLLMs) requires both accurate advantage estimation and precise estimation of prediction probabilities. Existing RL methods for dLLMs fall short in both aspects: they rely on coarse or unverifiable reward signals, and they estimate prediction probabilities without accounting for the bias relative to the true, unbiased expected prediction probability that properly integrates over all possible decoding orders. To mitigate these issues, we propose \emph{d}-TreeRPO, a reliable RL framework for dLLMs that leverages tree-structured rollouts and bottom-up advantage computation based on verifiable outcome rewards to provide fine-grained and verifiable step-wise reward signals. When estimating the conditional transition probability from a parent node to a child node, we theoretically analyze the estimation error between the unbiased expected prediction probability and the estimate obtained via a single forward pass, and find that higher prediction confidence leads to lower estimation error. Guided by this analysis, we introduce a time-scheduled self-distillation loss during training that enhances prediction confidence in later training stages, thereby enabling more accurate probability estimation and improved convergence. Experiments show that \emph{d}-TreeRPO outperforms existing baselines and achieves significant gains on multiple reasoning benchmarks, including +86.2 on Sudoku, +51.6 on Countdown, +4.5 on GSM8K, and +5.3 on Math500. Ablation studies and computational cost analyses further demonstrate the effectiveness and practicality of our design choices.
A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models
Aug 12, 2025



As text generation has become a core capability of modern Large Language Models (LLMs), it underpins a wide range of downstream applications. However, most existing LLMs rely on autoregressive (AR) generation, producing one token at a time based on previously generated context-resulting in limited generation speed due to the inherently sequential nature of the process. To address this challenge, an increasing number of researchers have begun exploring parallel text generation-a broad class of techniques aimed at breaking the token-by-token generation bottleneck and improving inference efficiency. Despite growing interest, there remains a lack of comprehensive analysis on what specific techniques constitute parallel text generation and how they improve inference performance. To bridge this gap, we present a systematic survey of parallel text generation methods. We categorize existing approaches into AR-based and Non-AR-based paradigms, and provide a detailed examination of the core techniques within each category. Following this taxonomy, we assess their theoretical trade-offs in terms of speed, quality, and efficiency, and examine their potential for combination and comparison with alternative acceleration strategies. Finally, based on our findings, we highlight recent advancements, identify open challenges, and outline promising directions for future research in parallel text generation.
Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025
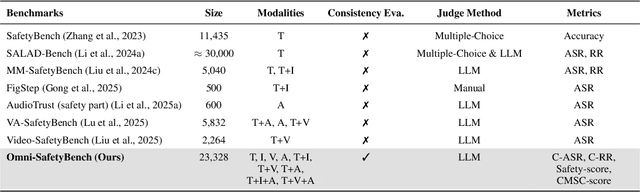

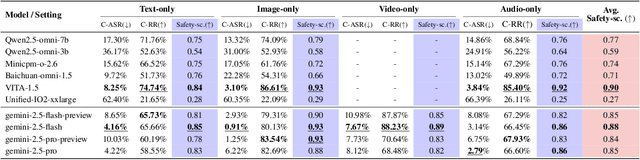
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Can LLM Watermarks Robustly Prevent Unauthorized Knowledge Distillation?
Feb 17, 2025The radioactive nature of Large Language Model (LLM) watermarking enables the detection of watermarks inherited by student models when trained on the outputs of watermarked teacher models, making it a promising tool for preventing unauthorized knowledge distillation. However, the robustness of watermark radioactivity against adversarial actors remains largely unexplored. In this paper, we investigate whether student models can acquire the capabilities of teacher models through knowledge distillation while avoiding watermark inheritance. We propose two categories of watermark removal approaches: pre-distillation removal through untargeted and targeted training data paraphrasing (UP and TP), and post-distillation removal through inference-time watermark neutralization (WN). Extensive experiments across multiple model pairs, watermarking schemes and hyper-parameter settings demonstrate that both TP and WN thoroughly eliminate inherited watermarks, with WN achieving this while maintaining knowledge transfer efficiency and low computational overhead. Given the ongoing deployment of watermarking techniques in production LLMs, these findings emphasize the urgent need for more robust defense strategies. Our code is available at https://github.com/THU-BPM/Watermark-Radioactivity-Attack.