 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan VLMs Truly Forget? Benchmarking Training-Free Visual Concept Unlearning
Apr 03, 2026VLMs trained on web-scale data retain sensitive and copyrighted visual concepts that deployment may require removing. Training-based unlearning methods share a structural flaw: fine-tuning on a narrow forget set degrades general capabilities before unlearning begins, making it impossible to attribute subsequent performance drops to the unlearning procedure itself. Training-free approaches sidestep this by suppressing concepts through prompts or system instructions, but no rigorous benchmark exists for evaluating them on visual tasks. We introduce VLM-UnBench, the first benchmark for training-free visual concept unlearning in VLMs. It covers four forgetting levels, 7 source datasets, and 11 concept axes, and pairs a three-level probe taxonomy with five evaluation conditions to separate genuine forgetting from instruction compliance. Across 8 evaluation settings and 13 VLM configurations, realistic unlearning prompts leave forget accuracy near the no-instruction baseline; meaningful reductions appear only under oracle conditions that disclose the target concept to the model. Object and scene concepts are the most resistant to suppression, and stronger instruction-tuned models remain capable despite explicit forget instructions. These results expose a clear gap between prompt-level suppression and true visual concept erasure.
TDMM-LM: Bridging Facial Understanding and Animation via Language Models
Mar 14, 2026Text-guided human body animation has advanced rapidly, yet facial animation lags due to the scarcity of well-annotated, text-paired facial corpora. To close this gap, we leverage foundation generative models to synthesize a large, balanced corpus of facial behavior. We design prompts suite covering emotions and head motions, generate about 80 hours of facial videos with multiple generators, and fit per-frame 3D facial parameters, yielding large-scale (prompt and parameter) pairs for training. Building on this dataset, we probe language models for bidirectional competence over facial motion via two complementary tasks: (1) Motion2Language: given a sequence of 3D facial parameters, the model produces natural-language descriptions capturing content, style, and dynamics; and (2) Language2Motion: given a prompt, the model synthesizes the corresponding sequence of 3D facial parameters via quantized motion tokens for downstream animation. Extensive experiments show that in this setting language models can both interpret and synthesize facial motion with strong generalization. To best of our knowledge, this is the first work to cast facial-parameter modeling as a language problem, establishing a unified path for text-conditioned facial animation and motion understanding.
Omni-Judge: Can Omni-LLMs Serve as Human-Aligned Judges for Text-Conditioned Audio-Video Generation?
Feb 02, 2026State-of-the-art text-to-video generation models such as Sora 2 and Veo 3 can now produce high-fidelity videos with synchronized audio directly from a textual prompt, marking a new milestone in multi-modal generation. However, evaluating such tri-modal outputs remains an unsolved challenge. Human evaluation is reliable but costly and difficult to scale, while traditional automatic metrics, such as FVD, CLAP, and ViCLIP, focus on isolated modality pairs, struggle with complex prompts, and provide limited interpretability. Omni-modal large language models (omni-LLMs) present a promising alternative: they naturally process audio, video, and text, support rich reasoning, and offer interpretable chain-of-thought feedback. Driven by this, we introduce Omni-Judge, a study assessing whether omni-LLMs can serve as human-aligned judges for text-conditioned audio-video generation. Across nine perceptual and alignment metrics, Omni-Judge achieves correlation comparable to traditional metrics and excels on semantically demanding tasks such as audio-text alignment, video-text alignment, and audio-video-text coherence. It underperforms on high-FPS perceptual metrics, including video quality and audio-video synchronization, due to limited temporal resolution. Omni-Judge provides interpretable explanations that expose semantic or physical inconsistencies, enabling practical downstream uses such as feedback-based refinement. Our findings highlight both the potential and current limitations of omni-LLMs as unified evaluators for multi-modal generation.
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025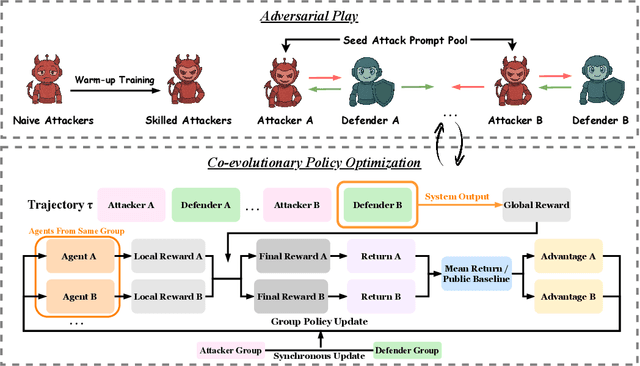

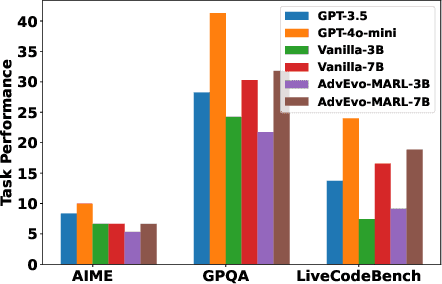
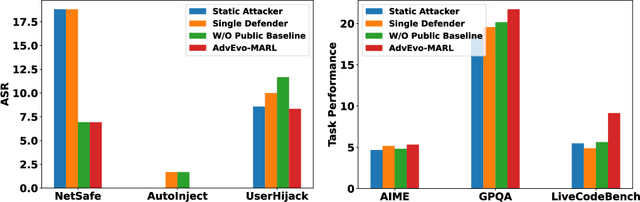
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.