 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes a Global Perspective Help Prune Sparse MoEs Elegantly?
Apr 08, 2026Empirical scaling laws for language models have encouraged the development of ever-larger LLMs, despite their growing computational and memory costs. Sparse Mixture-of-Experts (MoEs) offer a promising alternative by activating only a subset of experts per forward pass, improving efficiency without sacrificing performance. However, the large number of expert parameters still leads to substantial memory consumption. Existing pruning methods typically allocate budgets uniformly across layers, overlooking the heterogeneous redundancy that arises in sparse MoEs. We propose GRAPE (Global Redundancy-Aware Pruning of Experts, a global pruning strategy that dynamically allocates pruning budgets based on cross-layer redundancy. Experiments on Mixtral-8x7B, Mixtral-8x22B, DeepSeek-MoE, Qwen-MoE, and GPT-OSS show that, under the same pruning budget, GRAPE consistently achieves the best average performance. On the three main models reported in the paper, it improves average accuracy over the strongest local baseline by 1.40% on average across pruning settings, with gains of up to 2.45%.
Can VLMs Truly Forget? Benchmarking Training-Free Visual Concept Unlearning
Apr 03, 2026VLMs trained on web-scale data retain sensitive and copyrighted visual concepts that deployment may require removing. Training-based unlearning methods share a structural flaw: fine-tuning on a narrow forget set degrades general capabilities before unlearning begins, making it impossible to attribute subsequent performance drops to the unlearning procedure itself. Training-free approaches sidestep this by suppressing concepts through prompts or system instructions, but no rigorous benchmark exists for evaluating them on visual tasks. We introduce VLM-UnBench, the first benchmark for training-free visual concept unlearning in VLMs. It covers four forgetting levels, 7 source datasets, and 11 concept axes, and pairs a three-level probe taxonomy with five evaluation conditions to separate genuine forgetting from instruction compliance. Across 8 evaluation settings and 13 VLM configurations, realistic unlearning prompts leave forget accuracy near the no-instruction baseline; meaningful reductions appear only under oracle conditions that disclose the target concept to the model. Object and scene concepts are the most resistant to suppression, and stronger instruction-tuned models remain capable despite explicit forget instructions. These results expose a clear gap between prompt-level suppression and true visual concept erasure.
Why Instruction-Based Unlearning Fails in Diffusion Models?
Apr 02, 2026Instruction-based unlearning has proven effective for modifying the behavior of large language models at inference time, but whether this paradigm extends to other generative models remains unclear. In this work, we investigate instruction-based unlearning in diffusion-based image generation models and show, through controlled experiments across multiple concepts and prompt variants, that diffusion models systematically fail to suppress targeted concepts when guided solely by natural-language unlearning instructions. By analyzing both the CLIP text encoder and cross-attention dynamics during the denoising process, we find that unlearning instructions do not induce sustained reductions in attention to the targeted concept tokens, causing the targeted concept representations to persist throughout generation. These results reveal a fundamental limitation of prompt-level instruction in diffusion models and suggest that effective unlearning requires interventions beyond inference-time language control.
Training Large Reasoning Models Efficiently via Progressive Thought Encoding
Feb 18, 2026Large reasoning models (LRMs) excel on complex problems but face a critical barrier to efficiency: reinforcement learning (RL) training requires long rollouts for outcome-based rewards, where autoregressive decoding dominates time and memory usage. While sliding-window cache strategies can bound memory, they disrupt long-context reasoning and degrade performance. We introduce Progressive Thought Encoding, a parameter-efficient fine-tuning method that enables LRMs to reason effectively under fixed-size caches. By progressively encoding intermediate reasoning into fixed-size vector representations, our approach eliminates the need to backpropagate through full-cache rollouts, thereby reducing memory usage, while maintaining constant memory during inference. Experiments on three models, including Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct, and DeepSeek-R1-Distill-Llama-8B, on six widely used challenging mathematical benchmarks show consistent gains: our method achieves +19.3% improvement over LoRA-based fine-tuning and +29.9% over LRMs without fine-tuning on average, with up to +23.4 accuracy improvement on AIME2024/2025 under the same tight cache budgets. These results demonstrate that Progressive Thought Encoding not only improves reasoning accuracy but also makes RL training of LRMs substantially more efficient and scalable under real-world memory constraints.
Omni-Judge: Can Omni-LLMs Serve as Human-Aligned Judges for Text-Conditioned Audio-Video Generation?
Feb 02, 2026State-of-the-art text-to-video generation models such as Sora 2 and Veo 3 can now produce high-fidelity videos with synchronized audio directly from a textual prompt, marking a new milestone in multi-modal generation. However, evaluating such tri-modal outputs remains an unsolved challenge. Human evaluation is reliable but costly and difficult to scale, while traditional automatic metrics, such as FVD, CLAP, and ViCLIP, focus on isolated modality pairs, struggle with complex prompts, and provide limited interpretability. Omni-modal large language models (omni-LLMs) present a promising alternative: they naturally process audio, video, and text, support rich reasoning, and offer interpretable chain-of-thought feedback. Driven by this, we introduce Omni-Judge, a study assessing whether omni-LLMs can serve as human-aligned judges for text-conditioned audio-video generation. Across nine perceptual and alignment metrics, Omni-Judge achieves correlation comparable to traditional metrics and excels on semantically demanding tasks such as audio-text alignment, video-text alignment, and audio-video-text coherence. It underperforms on high-FPS perceptual metrics, including video quality and audio-video synchronization, due to limited temporal resolution. Omni-Judge provides interpretable explanations that expose semantic or physical inconsistencies, enabling practical downstream uses such as feedback-based refinement. Our findings highlight both the potential and current limitations of omni-LLMs as unified evaluators for multi-modal generation.
Advancing LLM-Based Security Automation with Customized Group Relative Policy Optimization for Zero-Touch Networks
Dec 10, 2025Zero-Touch Networks (ZTNs) represent a transformative paradigm toward fully automated and intelligent network management, providing the scalability and adaptability required for the complexity of sixth-generation (6G) networks. However, the distributed architecture, high openness, and deep heterogeneity of 6G networks expand the attack surface and pose unprecedented security challenges. To address this, security automation aims to enable intelligent security management across dynamic and complex environments, serving as a key capability for securing 6G ZTNs. Despite its promise, implementing security automation in 6G ZTNs presents two primary challenges: 1) automating the lifecycle from security strategy generation to validation and update under real-world, parallel, and adversarial conditions, and 2) adapting security strategies to evolving threats and dynamic environments. This motivates us to propose SecLoop and SA-GRPO. SecLoop constitutes the first fully automated framework that integrates large language models (LLMs) across the entire lifecycle of security strategy generation, orchestration, response, and feedback, enabling intelligent and adaptive defenses in dynamic network environments, thus tackling the first challenge. Furthermore, we propose SA-GRPO, a novel security-aware group relative policy optimization algorithm that iteratively refines security strategies by contrasting group feedback collected from parallel SecLoop executions, thereby addressing the second challenge. Extensive real-world experiments on five benchmarks, including 11 MITRE ATT&CK processes and over 20 types of attacks, demonstrate the superiority of the proposed SecLoop and SA-GRPO. We will release our platform to the community, facilitating the advancement of security automation towards next generation communications.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025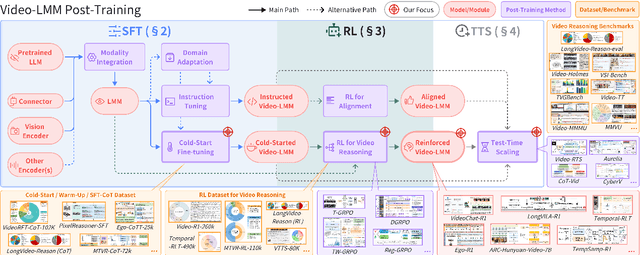
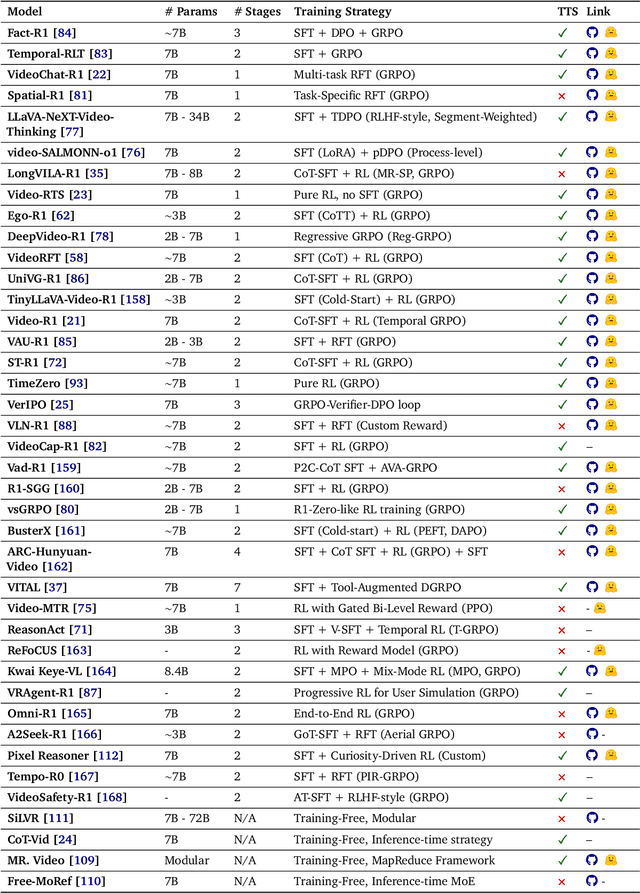
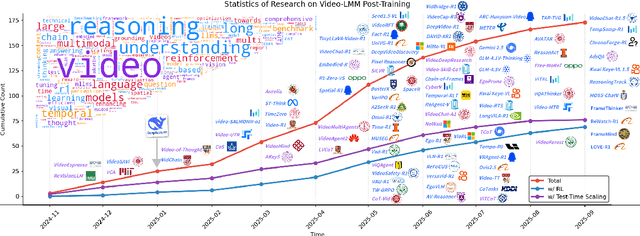
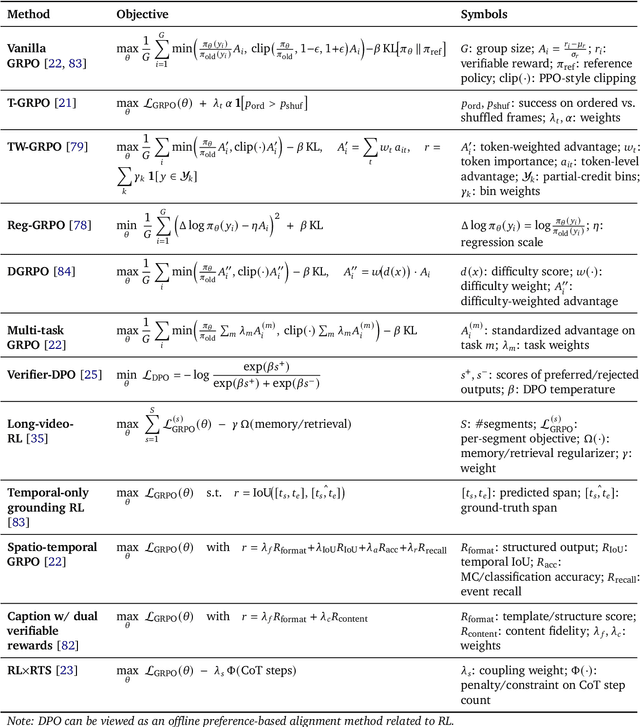
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
AdvEvo-MARL: Shaping Internalized Safety through Adversarial Co-Evolution in Multi-Agent Reinforcement Learning
Oct 02, 2025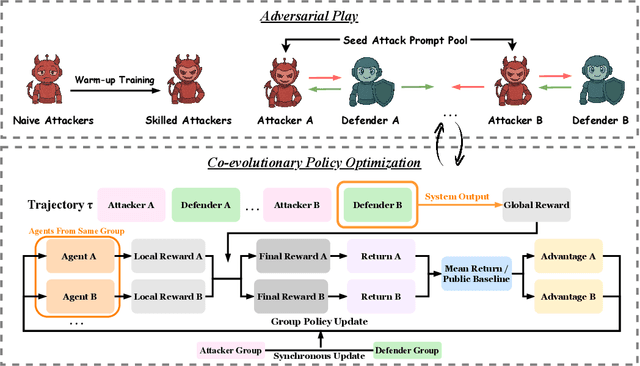

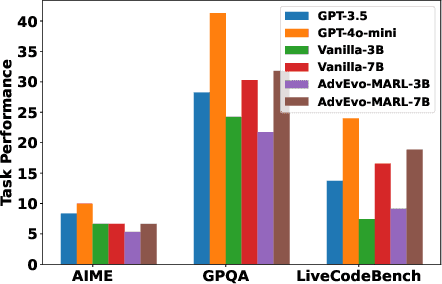
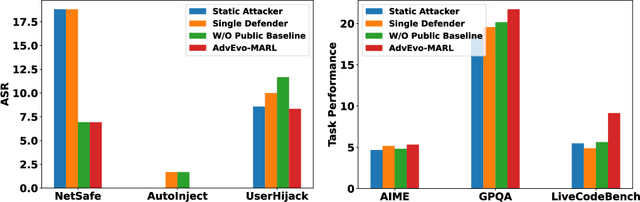
LLM-based multi-agent systems excel at planning, tool use, and role coordination, but their openness and interaction complexity also expose them to jailbreak, prompt-injection, and adversarial collaboration. Existing defenses fall into two lines: (i) self-verification that asks each agent to pre-filter unsafe instructions before execution, and (ii) external guard modules that police behaviors. The former often underperforms because a standalone agent lacks sufficient capacity to detect cross-agent unsafe chains and delegation-induced risks; the latter increases system overhead and creates a single-point-of-failure-once compromised, system-wide safety collapses, and adding more guards worsens cost and complexity. To solve these challenges, we propose AdvEvo-MARL, a co-evolutionary multi-agent reinforcement learning framework that internalizes safety into task agents. Rather than relying on external guards, AdvEvo-MARL jointly optimizes attackers (which synthesize evolving jailbreak prompts) and defenders (task agents trained to both accomplish their duties and resist attacks) in adversarial learning environments. To stabilize learning and foster cooperation, we introduce a public baseline for advantage estimation: agents within the same functional group share a group-level mean-return baseline, enabling lower-variance updates and stronger intra-group coordination. Across representative attack scenarios, AdvEvo-MARL consistently keeps attack-success rate (ASR) below 20%, whereas baselines reach up to 38.33%, while preserving-and sometimes improving-task accuracy (up to +3.67% on reasoning tasks). These results show that safety and utility can be jointly improved without relying on extra guard agents or added system overhead.
MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
May 26, 2025Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/
The Sword of Damocles in ViTs: Computational Redundancy Amplifies Adversarial Transferability
Apr 15, 2025Vision Transformers (ViTs) have demonstrated impressive performance across a range of applications, including many safety-critical tasks. However, their unique architectural properties raise new challenges and opportunities in adversarial robustness. In particular, we observe that adversarial examples crafted on ViTs exhibit higher transferability compared to those crafted on CNNs, suggesting that ViTs contain structural characteristics favorable for transferable attacks. In this work, we investigate the role of computational redundancy in ViTs and its impact on adversarial transferability. Unlike prior studies that aim to reduce computation for efficiency, we propose to exploit this redundancy to improve the quality and transferability of adversarial examples. Through a detailed analysis, we identify two forms of redundancy, including the data-level and model-level, that can be harnessed to amplify attack effectiveness. Building on this insight, we design a suite of techniques, including attention sparsity manipulation, attention head permutation, clean token regularization, ghost MoE diversification, and test-time adversarial training. Extensive experiments on the ImageNet-1k dataset validate the effectiveness of our approach, showing that our methods significantly outperform existing baselines in both transferability and generality across diverse model architectures.