 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Reasoning Space: The cage of long-horizon reasoning in LLMs
Feb 22, 2026The test-time compute strategy, such as Chain-of-Thought (CoT), has significantly enhanced the ability of large language models to solve complex tasks like logical reasoning. However, empirical studies indicate that simply increasing the compute budget can sometimes lead to a collapse in test-time performance when employing typical task decomposition strategies such as CoT. This work hypothesizes that reasoning failures with larger compute budgets stem from static planning methods, which hardly perceive the intrinsic boundaries of LLM reasoning. We term it as the Limited Reasoning Space hypothesis and perform theoretical analysis through the lens of a non-autonomous stochastic dynamical system. This insight suggests that there is an optimal range for compute budgets; over-planning can lead to redundant feedback and may even impair reasoning capabilities. To exploit the compute-scaling benefits and suppress over-planning, this work proposes Halo, a model predictive control framework for LLM planning. Halo is designed for long-horizon tasks with reason-based planning and crafts an entropy-driven dual controller, which adopts a Measure-then-Plan strategy to achieve controllable reasoning. Experimental results demonstrate that Halo outperforms static baselines on complex long-horizon tasks by dynamically regulating planning at the reasoning boundary.
Climber-Pilot: A Non-Myopic Generative Recommendation Model Towards Better Instruction-Following
Feb 14, 2026Generative retrieval has emerged as a promising paradigm in recommender systems, offering superior sequence modeling capabilities over traditional dual-tower architectures. However, in large-scale industrial scenarios, such models often suffer from inherent myopia: due to single-step inference and strict latency constraints, they tend to collapse diverse user intents into locally optimal predictions, failing to capture long-horizon and multi-item consumption patterns. Moreover, real-world retrieval systems must follow explicit retrieval instructions, such as category-level control and policy constraints. Incorporating such instruction-following behavior into generative retrieval remains challenging, as existing conditioning or post-hoc filtering approaches often compromise relevance or efficiency. In this work, we present Climber-Pilot, a unified generative retrieval framework to address both limitations. First, we introduce Time-Aware Multi-Item Prediction (TAMIP), a novel training paradigm designed to mitigate inherent myopia in generative retrieval. By distilling long-horizon, multi-item foresight into model parameters through time-aware masking, TAMIP alleviates locally optimal predictions while preserving efficient single-step inference. Second, to support flexible instruction-following retrieval, we propose Condition-Guided Sparse Attention (CGSA), which incorporates business constraints directly into the generative process via sparse attention, without introducing additional inference steps. Extensive offline experiments and online A/B testing at NetEase Cloud Music, one of the largest music streaming platforms, demonstrate that Climber-Pilot significantly outperforms state-of-the-art baselines, achieving a 4.24\% lift of the core business metric.
6D Channel Knowledge Map Construction via Bidirectional Wireless Gaussian Splatting
Oct 30, 2025
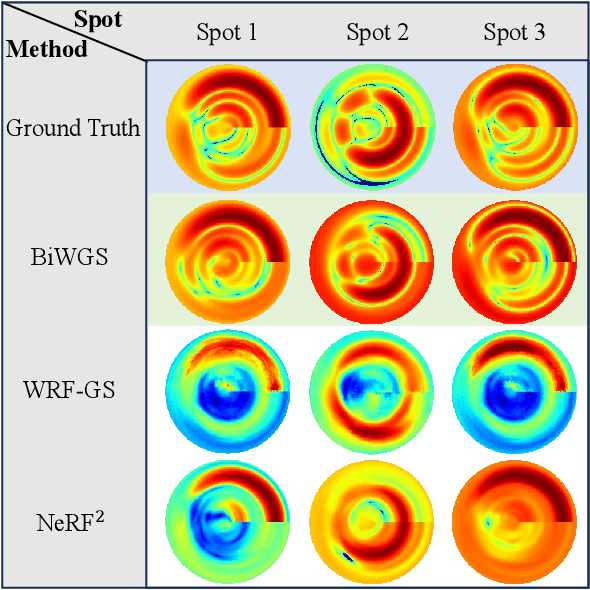
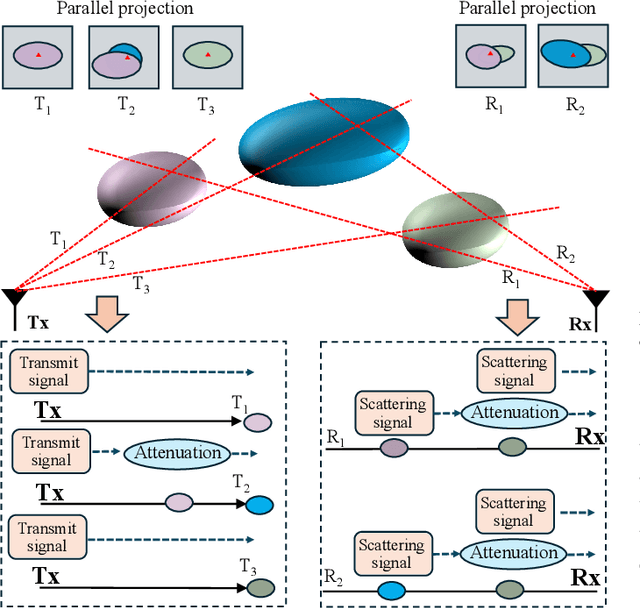
This paper investigates the construction of channel knowledge map (CKM) from sparse channel measurements. Dif ferent from conventional two-/three-dimensional (2D/3D) CKM approaches assuming fixed base station configurations, we present a six-dimensional (6D) CKM framework named bidirectional wireless Gaussian splatting (BiWGS), which is capable of mod eling wireless channels across dynamic transmitter (Tx) and receiver (Rx) positions in 3D space. BiWGS uses Gaussian el lipsoids to represent virtual scatterer clusters and environmental obstacles in the wireless environment. By properly learning the bidirectional scattering patterns and complex attenuation profiles based on channel measurements, these ellipsoids inherently cap ture the electromagnetic transmission characteristics of wireless environments, thereby accurately modeling signal transmission under varying transceiver configurations. Experiment results show that BiWGS significantly outperforms classic multi-layer perception (MLP) for the construction of 6D channel power gain map with varying Tx-Rx positions, and achieves spatial spectrum prediction accuracy comparable to the state-of-the art wireless radiation field Gaussian splatting (WRF-GS) for 3D CKM construction. This validates the capability of the proposed BiWGS in accomplishing dimensional expansion of 6D CKM construction, without compromising fidelity.
Emotion Transfer with Enhanced Prototype for Unseen Emotion Recognition in Conversation
Aug 27, 2025



Current Emotion Recognition in Conversation (ERC) research follows a closed-domain assumption. However, there is no clear consensus on emotion classification in psychology, which presents a challenge for models when it comes to recognizing previously unseen emotions in real-world applications. To bridge this gap, we introduce the Unseen Emotion Recognition in Conversation (UERC) task for the first time and propose ProEmoTrans, a solid prototype-based emotion transfer framework. This prototype-based approach shows promise but still faces key challenges: First, implicit expressions complicate emotion definition, which we address by proposing an LLM-enhanced description approach. Second, utterance encoding in long conversations is difficult, which we tackle with a proposed parameter-free mechanism for efficient encoding and overfitting prevention. Finally, the Markovian flow nature of emotions is hard to transfer, which we address with an improved Attention Viterbi Decoding (AVD) method to transfer seen emotion transitions to unseen emotions. Extensive experiments on three datasets show that our method serves as a strong baseline for preliminary exploration in this new area.
STAMImputer: Spatio-Temporal Attention MoE for Traffic Data Imputation
Jun 11, 2025Traffic data imputation is fundamentally important to support various applications in intelligent transportation systems such as traffic flow prediction. However, existing time-to-space sequential methods often fail to effectively extract features in block-wise missing data scenarios. Meanwhile, the static graph structure for spatial feature propagation significantly constrains the models flexibility in handling the distribution shift issue for the nonstationary traffic data. To address these issues, this paper proposes a SpatioTemporal Attention Mixture of experts network named STAMImputer for traffic data imputation. Specifically, we introduce a Mixture of Experts (MoE) framework to capture latent spatio-temporal features and their influence weights, effectively imputing block missing. A novel Low-rank guided Sampling Graph ATtention (LrSGAT) mechanism is designed to dynamically balance the local and global correlations across road networks. The sampled attention vectors are utilized to generate dynamic graphs that capture real-time spatial correlations. Extensive experiments are conducted on four traffic datasets for evaluation. The result shows STAMImputer achieves significantly performance improvement compared with existing SOTA approaches. Our codes are available at https://github.com/RingBDStack/STAMImupter.
Unsupervised Graph Clustering with Deep Structural Entropy
May 20, 2025Research on Graph Structure Learning (GSL) provides key insights for graph-based clustering, yet current methods like Graph Neural Networks (GNNs), Graph Attention Networks (GATs), and contrastive learning often rely heavily on the original graph structure. Their performance deteriorates when the original graph's adjacency matrix is too sparse or contains noisy edges unrelated to clustering. Moreover, these methods depend on learning node embeddings and using traditional techniques like k-means to form clusters, which may not fully capture the underlying graph structure between nodes. To address these limitations, this paper introduces DeSE, a novel unsupervised graph clustering framework incorporating Deep Structural Entropy. It enhances the original graph with quantified structural information and deep neural networks to form clusters. Specifically, we first propose a method for calculating structural entropy with soft assignment, which quantifies structure in a differentiable form. Next, we design a Structural Learning layer (SLL) to generate an attributed graph from the original feature data, serving as a target to enhance and optimize the original structural graph, thereby mitigating the issue of sparse connections between graph nodes. Finally, our clustering assignment method (ASS), based on GNNs, learns node embeddings and a soft assignment matrix to cluster on the enhanced graph. The ASS layer can be stacked to meet downstream task requirements, minimizing structural entropy for stable clustering and maximizing node consistency with edge-based cross-entropy loss. Extensive comparative experiments are conducted on four benchmark datasets against eight representative unsupervised graph clustering baselines, demonstrating the superiority of the DeSE in both effectiveness and interpretability.
T-T: Table Transformer for Tagging-based Aspect Sentiment Triplet Extraction
May 08, 2025Aspect sentiment triplet extraction (ASTE) aims to extract triplets composed of aspect terms, opinion terms, and sentiment polarities from given sentences. The table tagging method is a popular approach to addressing this task, which encodes a sentence into a 2-dimensional table, allowing for the tagging of relations between any two words. Previous efforts have focused on designing various downstream relation learning modules to better capture interactions between tokens in the table, revealing that a stronger capability to capture relations can lead to greater improvements in the model. Motivated by this, we attempt to directly utilize transformer layers as downstream relation learning modules. Due to the powerful semantic modeling capability of transformers, it is foreseeable that this will lead to excellent improvement. However, owing to the quadratic relation between the length of the table and the length of the input sentence sequence, using transformers directly faces two challenges: overly long table sequences and unfair local attention interaction. To address these challenges, we propose a novel Table-Transformer (T-T) for the tagging-based ASTE method. Specifically, we introduce a stripe attention mechanism with a loop-shift strategy to tackle these challenges. The former modifies the global attention mechanism to only attend to a 2-dimensional local attention window, while the latter facilitates interaction between different attention windows. Extensive and comprehensive experiments demonstrate that the T-T, as a downstream relation learning module, achieves state-of-the-art performance with lower computational costs.
HumanMM: Global Human Motion Recovery from Multi-shot Videos
Mar 10, 2025In this paper, we present a novel framework designed to reconstruct long-sequence 3D human motion in the world coordinates from in-the-wild videos with multiple shot transitions. Such long-sequence in-the-wild motions are highly valuable to applications such as motion generation and motion understanding, but are of great challenge to be recovered due to abrupt shot transitions, partial occlusions, and dynamic backgrounds presented in such videos. Existing methods primarily focus on single-shot videos, where continuity is maintained within a single camera view, or simplify multi-shot alignment in camera space only. In this work, we tackle the challenges by integrating an enhanced camera pose estimation with Human Motion Recovery (HMR) by incorporating a shot transition detector and a robust alignment module for accurate pose and orientation continuity across shots. By leveraging a custom motion integrator, we effectively mitigate the problem of foot sliding and ensure temporal consistency in human pose. Extensive evaluations on our created multi-shot dataset from public 3D human datasets demonstrate the robustness of our method in reconstructing realistic human motion in world coordinates.
Motion-X++: A Large-Scale Multimodal 3D Whole-body Human Motion Dataset
Jan 09, 2025



In this paper, we introduce Motion-X++, a large-scale multimodal 3D expressive whole-body human motion dataset. Existing motion datasets predominantly capture body-only poses, lacking facial expressions, hand gestures, and fine-grained pose descriptions, and are typically limited to lab settings with manually labeled text descriptions, thereby restricting their scalability. To address this issue, we develop a scalable annotation pipeline that can automatically capture 3D whole-body human motion and comprehensive textural labels from RGB videos and build the Motion-X dataset comprising 81.1K text-motion pairs. Furthermore, we extend Motion-X into Motion-X++ by improving the annotation pipeline, introducing more data modalities, and scaling up the data quantities. Motion-X++ provides 19.5M 3D whole-body pose annotations covering 120.5K motion sequences from massive scenes, 80.8K RGB videos, 45.3K audios, 19.5M frame-level whole-body pose descriptions, and 120.5K sequence-level semantic labels. Comprehensive experiments validate the accuracy of our annotation pipeline and highlight Motion-X++'s significant benefits for generating expressive, precise, and natural motion with paired multimodal labels supporting several downstream tasks, including text-driven whole-body motion generation,audio-driven motion generation, 3D whole-body human mesh recovery, and 2D whole-body keypoints estimation, etc.
Group Distributionally Robust Optimization can Suppress Class Imbalance Effect in Network Traffic Classification
Sep 28, 2024



Internet services have led to the eruption of traffic, and machine learning on these Internet data has become an indispensable tool, especially when the application is risk-sensitive. This paper focuses on network traffic classification in the presence of class imbalance, which fundamentally and ubiquitously exists in Internet data analysis. This existence of class imbalance mostly drifts the optimal decision boundary, resulting in a less optimal solution for machine learning models. To alleviate the effect, we propose to design strategies for alleviating the class imbalance through the lens of group distributionally robust optimization. Our approach iteratively updates the non-parametric weights for separate classes and optimizes the learning model by minimizing reweighted losses. We interpret the optimization steps from a Stackelberg game and perform extensive experiments on typical benchmarks. Results show that our approach can not only suppress the negative effect of class imbalance but also improve the comprehensive performance in prediction.