 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
MSR-HuBERT: Self-supervised Pre-training for Adaptation to Multiple Sampling Rates
Mar 24, 2026Self-supervised learning (SSL) has advanced speech processing. However, existing speech SSL methods typically assume a single sampling rate and struggle with mixed-rate data due to temporal resolution mismatch. To address this limitation, we propose MSRHuBERT, a multi-sampling-rate adaptive pre-training method. Building on HuBERT, we replace its single-rate downsampling CNN with a multi-sampling-rate adaptive downsampling CNN that maps raw waveforms from different sampling rates to a shared temporal resolution without resampling. This design enables unified mixed-rate pre-training and fine-tuning. In experiments spanning 16 to 48 kHz, MSRHuBERT outperforms HuBERT on speech recognition and full-band speech reconstruction, preserving high-frequency detail while modeling low-frequency semantic structure. Moreover, MSRHuBERT retains HuBERT's mask-prediction objective and Transformer encoder, so existing analyses and improvements that were developed for HuBERT can apply directly.
POTSA: A Cross-Lingual Speech Alignment Framework for Low Resource Speech-to-Text Translation
Nov 12, 2025Speech Large Language Models (SpeechLLMs) have achieved breakthroughs in multilingual speech-to-text translation (S2TT). However, existing approaches often overlook semantic commonalities across source languages, leading to biased translation performance. In this work, we propose \textbf{POTSA} (Parallel Optimal Transport for Speech Alignment), a new framework based on cross-lingual parallel speech pairs and Optimal Transport (OT), designed to bridge high- and low-resource translation gaps. First, we introduce a Bias Compensation module to coarsely align initial speech representations across languages. Second, we impose token-level OT constraints on a Q-Former using parallel speech pairs to establish fine-grained consistency of representations. Then, we apply a layer scheduling strategy to focus OT constraints on the most semantically beneficial layers. Experiments on the FLEURS dataset show that our method achieves SOTA performance, with +0.93 BLEU on average over five common languages and +5.05 BLEU on zero-shot languages, using only 10 hours of parallel speech per source language.
ASDA: Audio Spectrogram Differential Attention Mechanism for Self-Supervised Representation Learning
Jul 03, 2025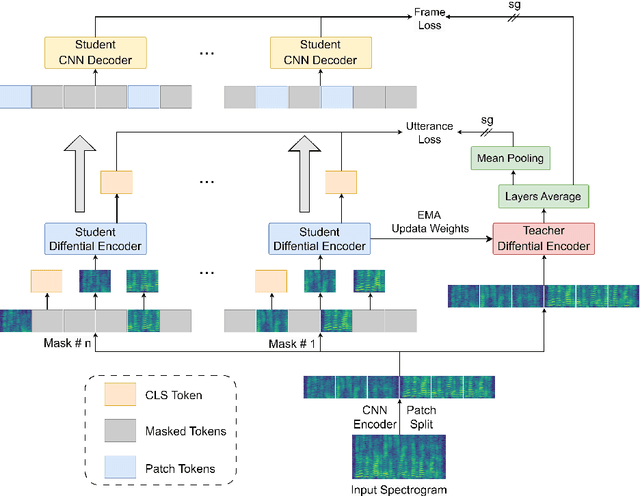
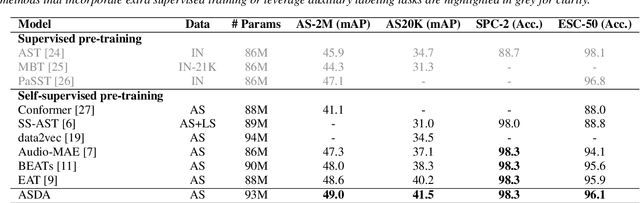
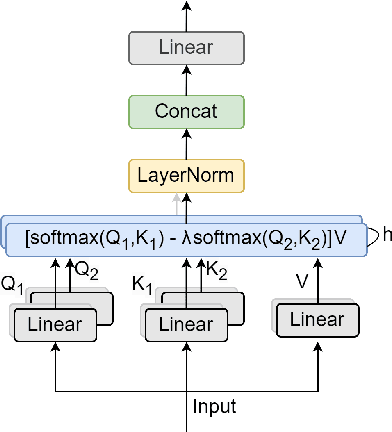
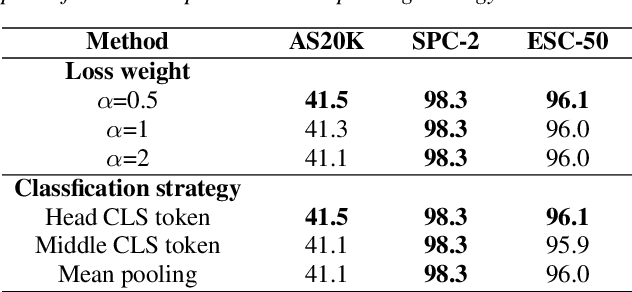
In recent advancements in audio self-supervised representation learning, the standard Transformer architecture has emerged as the predominant approach, yet its attention mechanism often allocates a portion of attention weights to irrelevant information, potentially impairing the model's discriminative ability. To address this, we introduce a differential attention mechanism, which effectively mitigates ineffective attention allocation through the integration of dual-softmax operations and appropriately tuned differential coefficients. Experimental results demonstrate that our ASDA model achieves state-of-the-art (SOTA) performance across multiple benchmarks, including audio classification (49.0% mAP on AS-2M, 41.5% mAP on AS20K), keyword spotting (98.3% accuracy on SPC-2), and environmental sound classification (96.1% accuracy on ESC-50). These results highlight ASDA's effectiveness in audio tasks, paving the way for broader applications.
Characteristic-Specific Partial Fine-Tuning for Efficient Emotion and Speaker Adaptation in Codec Language Text-to-Speech Models
Jan 24, 2025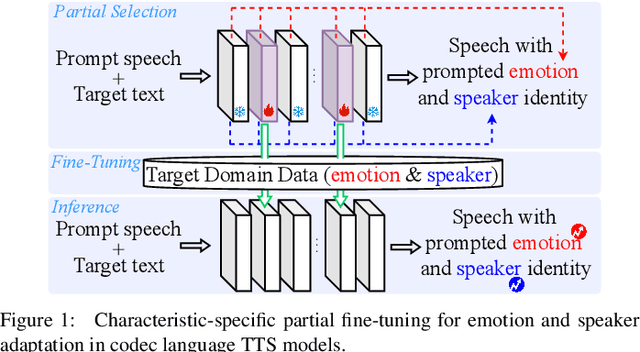
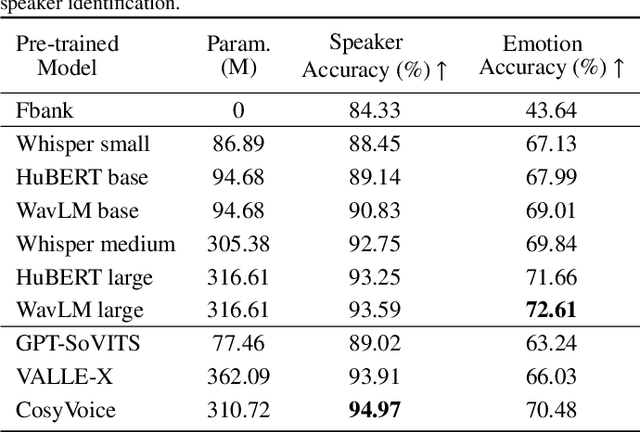
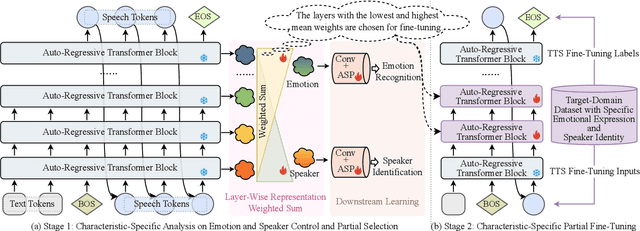
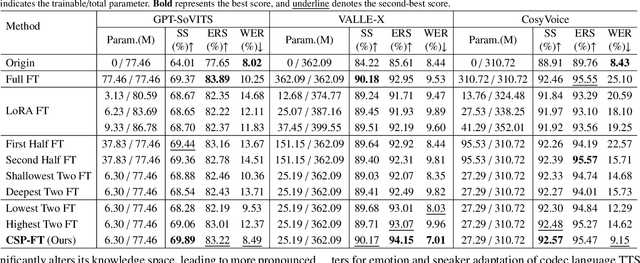
Recently, emotional speech generation and speaker cloning have garnered significant interest in text-to-speech (TTS). With the open-sourcing of codec language TTS models trained on massive datasets with large-scale parameters, adapting these general pre-trained TTS models to generate speech with specific emotional expressions and target speaker characteristics has become a topic of great attention. Common approaches, such as full and adapter-based fine-tuning, often overlook the specific contributions of model parameters to emotion and speaker control. Treating all parameters uniformly during fine-tuning, especially when the target data has limited content diversity compared to the pre-training corpus, results in slow training speed and an increased risk of catastrophic forgetting. To address these challenges, we propose a characteristic-specific partial fine-tuning strategy, short as CSP-FT. First, we use a weighted-sum approach to analyze the contributions of different Transformer layers in a pre-trained codec language TTS model for emotion and speaker control in the generated speech. We then selectively fine-tune the layers with the highest and lowest characteristic-specific contributions to generate speech with target emotional expression and speaker identity. Experimental results demonstrate that our method achieves performance comparable to, or even surpassing, full fine-tuning in generating speech with specific emotional expressions and speaker identities. Additionally, CSP-FT delivers approximately 2x faster training speeds, fine-tunes only around 8% of parameters, and significantly reduces catastrophic forgetting. Furthermore, we show that codec language TTS models perform competitively with self-supervised models in speaker identification and emotion classification tasks, offering valuable insights for developing universal speech processing models.
Reducing the Gap Between Pretrained Speech Enhancement and Recognition Models Using a Real Speech-Trained Bridging Module
Jan 05, 2025


The information loss or distortion caused by single-channel speech enhancement (SE) harms the performance of automatic speech recognition (ASR). Observation addition (OA) is an effective post-processing method to improve ASR performance by balancing noisy and enhanced speech. Determining the OA coefficient is crucial. However, the currently supervised OA coefficient module, called the bridging module, only utilizes simulated noisy speech for training, which has a severe mismatch with real noisy speech. In this paper, we propose training strategies to train the bridging module with real noisy speech. First, DNSMOS is selected to evaluate the perceptual quality of real noisy speech with no need for the corresponding clean label to train the bridging module. Additional constraints during training are introduced to enhance the robustness of the bridging module further. Each utterance is evaluated by the ASR back-end using various OA coefficients to obtain the word error rates (WERs). The WERs are used to construct a multidimensional vector. This vector is introduced into the bridging module with multi-task learning and is used to determine the optimal OA coefficients. The experimental results on the CHiME-4 dataset show that the proposed methods all had significant improvement compared with the simulated data trained bridging module, especially under real evaluation sets.
Time-Graph Frequency Representation with Singular Value Decomposition for Neural Speech Enhancement
Dec 24, 2024Time-frequency (T-F) domain methods for monaural speech enhancement have benefited from the success of deep learning. Recently, focus has been put on designing two-stream network models to predict amplitude mask and phase separately, or, coupling the amplitude and phase into Cartesian coordinates and constructing real and imaginary pairs. However, most methods suffer from the alignment modeling of amplitude and phase (real and imaginary pairs) in a two-stream network framework, which inevitably incurs performance restrictions. In this paper, we introduce a graph Fourier transform defined with the singular value decomposition (GFT-SVD), resulting in real-valued time-graph representation for neural speech enhancement. This real-valued representation-based GFT-SVD provides an ability to align the modeling of amplitude and phase, leading to avoiding recovering the target speech phase information. Our findings demonstrate the effects of real-valued time-graph representation based on GFT-SVD for neutral speech enhancement. The extensive speech enhancement experiments establish that the combination of GFT-SVD and DNN outperforms the combination of GFT with the eigenvector decomposition (GFT-EVD) and magnitude estimation UNet, and outperforms the short-time Fourier transform (STFT) and DNN, regarding objective intelligibility and perceptual quality. We release our source code at: https://github.com/Wangfighting0015/GFT\_project.
Mamba-SEUNet: Mamba UNet for Monaural Speech Enhancement
Dec 21, 2024In recent speech enhancement (SE) research, transformer and its variants have emerged as the predominant methodologies. However, the quadratic complexity of the self-attention mechanism imposes certain limitations on practical deployment. Mamba, as a novel state-space model (SSM), has gained widespread application in natural language processing and computer vision due to its strong capabilities in modeling long sequences and relatively low computational complexity. In this work, we introduce Mamba-SEUNet, an innovative architecture that integrates Mamba with U-Net for SE tasks. By leveraging bidirectional Mamba to model forward and backward dependencies of speech signals at different resolutions, and incorporating skip connections to capture multi-scale information, our approach achieves state-of-the-art (SOTA) performance. Experimental results on the VCTK+DEMAND dataset indicate that Mamba-SEUNet attains a PESQ score of 3.59, while maintaining low computational complexity. When combined with the Perceptual Contrast Stretching technique, Mamba-SEUNet further improves the PESQ score to 3.73.
WeSep: A Scalable and Flexible Toolkit Towards Generalizable Target Speaker Extraction
Sep 24, 2024



Target speaker extraction (TSE) focuses on isolating the speech of a specific target speaker from overlapped multi-talker speech, which is a typical setup in the cocktail party problem. In recent years, TSE draws increasing attention due to its potential for various applications such as user-customized interfaces and hearing aids, or as a crutial front-end processing technologies for subsequential tasks such as speech recognition and speaker recongtion. However, there are currently few open-source toolkits or available pre-trained models for off-the-shelf usage. In this work, we introduce WeSep, a toolkit designed for research and practical applications in TSE. WeSep is featured with flexible target speaker modeling, scalable data management, effective on-the-fly data simulation, structured recipes and deployment support. The toolkit is publicly avaliable at \url{https://github.com/wenet-e2e/WeSep.}
Progressive Residual Extraction based Pre-training for Speech Representation Learning
Aug 31, 2024



Self-supervised learning (SSL) has garnered significant attention in speech processing, excelling in linguistic tasks such as speech recognition. However, jointly improving the performance of pre-trained models on various downstream tasks, each requiring different speech information, poses significant challenges. To this purpose, we propose a progressive residual extraction based self-supervised learning method, named ProgRE. Specifically, we introduce two lightweight and specialized task modules into an encoder-style SSL backbone to enhance its ability to extract pitch variation and speaker information from speech. Furthermore, to prevent the interference of reinforced pitch variation and speaker information with irrelevant content information learning, we residually remove the information extracted by these two modules from the main branch. The main branch is then trained using HuBERT's speech masking prediction to ensure the performance of the Transformer's deep-layer features on content tasks. In this way, we can progressively extract pitch variation, speaker, and content representations from the input speech. Finally, we can combine multiple representations with diverse speech information using different layer weights to obtain task-specific representations for various downstream tasks. Experimental results indicate that our proposed method achieves joint performance improvements on various tasks, such as speaker identification, speech recognition, emotion recognition, speech enhancement, and voice conversion, compared to excellent SSL methods such as wav2vec2.0, HuBERT, and WavLM.