 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
May 29, 2025



This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a "fast" mode for routine queries and a deeper "slow" mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
Node Classification on Graphs with Few-Shot Novel Labels via Meta Transformed Network Embedding
Jul 06, 2020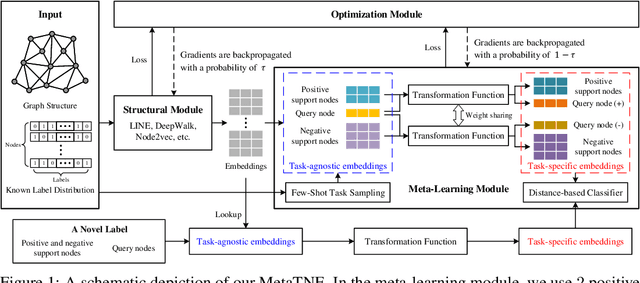
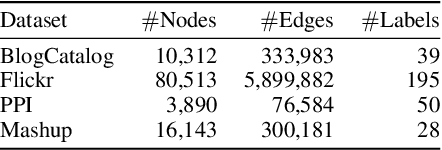
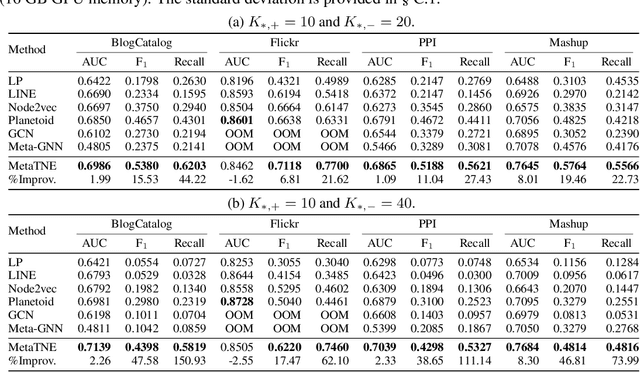
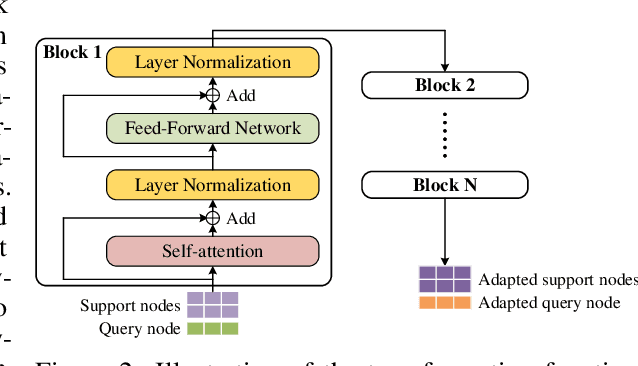
We study the problem of node classification on graphs with few-shot novel labels, which has two distinctive properties: (1) There are novel labels to emerge in the graph; (2) The novel labels have only a few representative nodes for training a classifier. The study of this problem is instructive and corresponds to many applications such as recommendations for newly formed groups with only a few users in online social networks. To cope with this problem, we propose a novel Meta Transformed Network Embedding framework (MetaTNE), which consists of three modules: (1) A \emph{structural module} provides each node a latent representation according to the graph structure. (2) A \emph{meta-learning module} captures the relationships between the graph structure and the node labels as prior knowledge in a meta-learning manner. Additionally, we introduce an \emph{embedding transformation function} that remedies the deficiency of the straightforward use of meta-learning. Inherently, the meta-learned prior knowledge can be used to facilitate the learning of few-shot novel labels. (3) An \emph{optimization module} employs a simple yet effective scheduling strategy to train the above two modules with a balance between graph structure learning and meta-learning. Experiments on four real-world datasets show that MetaTNE brings a huge improvement over the state-of-the-art methods.