 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-NER: Evidential Deep Learning for Trustworthy Named Entity Recognition
May 29, 2023Most named entity recognition (NER) systems focus on improving model performance, ignoring the need to quantify model uncertainty, which is critical to the reliability of NER systems in open environments. Evidential deep learning (EDL) has recently been proposed as a promising solution to explicitly model predictive uncertainty for classification tasks. However, directly applying EDL to NER applications faces two challenges, i.e., the problems of sparse entities and OOV/OOD entities in NER tasks. To address these challenges, we propose a trustworthy NER framework named E-NER by introducing two uncertainty-guided loss terms to the conventional EDL, along with a series of uncertainty-guided training strategies. Experiments show that E-NER can be applied to multiple NER paradigms to obtain accurate uncertainty estimation. Furthermore, compared to state-of-the-art baselines, the proposed method achieves a better OOV/OOD detection performance and better generalization ability on OOV entities.
Nearest Neighbor Machine Translation is Meta-Optimizer on Output Projection Layer
May 22, 2023



Nearest Neighbor Machine Translation ($k$NN-MT) has achieved great success on domain adaptation tasks by integrating pre-trained Neural Machine Translation (NMT) models with domain-specific token-level retrieval. However, the reasons underlying its success have not been thoroughly investigated. In this paper, we provide a comprehensive analysis of $k$NN-MT through theoretical and empirical studies. Initially, we offer a theoretical interpretation of the working mechanism of $k$NN-MT as an efficient technique to implicitly execute gradient descent on the output projection layer of NMT, indicating that it is a specific case of model fine-tuning. Subsequently, we conduct multi-domain experiments and word-level analysis to examine the differences in performance between $k$NN-MT and entire-model fine-tuning. Our findings suggest that: (1) Incorporating $k$NN-MT with adapters yields comparable translation performance to fine-tuning on in-domain test sets, while achieving better performance on out-of-domain test sets; (2) Fine-tuning significantly outperforms $k$NN-MT on the recall of low-frequency domain-specific words, but this gap could be bridged by optimizing the context representations with additional adapter layers.
ImSimCSE: Improving Contrastive Learning for Sentence Embeddings from Two Perspectives
May 22, 2023



This paper aims to improve contrastive learning for sentence embeddings from two perspectives: handling dropout noise and addressing feature corruption. Specifically, for the first perspective, we identify that the dropout noise from negative pairs affects the model's performance. Therefore, we propose a simple yet effective method to deal with such type of noise. Secondly, we pinpoint the rank bottleneck of current solutions to feature corruption and propose a dimension-wise contrastive learning objective to address this issue. Both proposed methods are generic and can be applied to any contrastive learning based models for sentence embeddings. Experimental results on standard benchmarks demonstrate that combining both proposed methods leads to a gain of 1.8 points compared to the strong baseline SimCSE configured with BERT base. Furthermore, applying the proposed method to DiffCSE, another strong contrastive learning based baseline, results in a gain of 1.4 points.
A Simple and Plug-and-play Method for Unsupervised Sentence Representation Enhancement
May 13, 2023



Generating proper embedding of sentences through an unsupervised way is beneficial to semantic matching and retrieval problems in real-world scenarios. This paper presents Representation ALchemy (RepAL), an extremely simple post-processing method that enhances sentence representations. The basic idea in RepAL is to de-emphasize redundant information of sentence embedding generated by pre-trained models. Through comprehensive experiments, we show that RepAL is free of training and is a plug-and-play method that can be combined with most existing unsupervised sentence learning models. We also conducted in-depth analysis to understand RepAL.
Frequency-aware Dimension Selection for Static Word Embedding by Mixed Product Distance
May 13, 2023Static word embedding is still useful, particularly for context-unavailable tasks, because in the case of no context available, pre-trained language models often perform worse than static word embeddings. Although dimension is a key factor determining the quality of static word embeddings, automatic dimension selection is rarely discussed. In this paper, we investigate the impact of word frequency on the dimension selection, and empirically find that word frequency is so vital that it needs to be taken into account during dimension selection. Based on such an empirical finding, this paper proposes a dimension selection method that uses a metric (Mixed Product Distance, MPD) to select a proper dimension for word embedding algorithms without training any word embedding. Through applying a post-processing function to oracle matrices, the MPD-based method can de-emphasize the impact of word frequency. Experiments on both context-unavailable and context-available tasks demonstrate the better efficiency-performance trade-off of our MPD-based dimension selection method over baselines.
Lift Yourself Up: Retrieval-augmented Text Generation with Self Memory
May 03, 2023



With direct access to human-written reference as memory, retrieval-augmented generation has achieved much progress in a wide range of text generation tasks. Since better memory would typically prompt better generation~(we define this as primal problem), previous works mainly focus on how to retrieve better memory. However, one fundamental limitation exists for current literature: the memory is retrieved from a fixed corpus and is bounded by the quality of the corpus. Due to the finite retrieval space, bounded memory would greatly limit the potential of the memory-augmented generation model. In this paper, by exploring the duality of the primal problem: better generation also prompts better memory, we propose a framework called Selfmem, which iteratively adopts a retrieval-augmented generator itself to generate an unbounded memory pool and uses a memory selector to pick one generated memory for the next generation round. By combining the primal and dual problem, a retrieval-augmented generation model could lift itself up with its own output in the infinite generation space. To verify our framework, we conduct extensive experiments across various text generation scenarios including neural machine translation, abstractive summarization and dialogue generation over seven datasets and achieve state-of-the-art results in JRC-Acquis(four directions), XSum(50.3 ROUGE-1) and BigPatent(62.9 ROUGE-1).
Fairness-guided Few-shot Prompting for Large Language Models
Mar 31, 2023



Large language models have demonstrated surprising ability to perform in-context learning, i.e., these models can be directly applied to solve numerous downstream tasks by conditioning on a prompt constructed by a few input-output examples. However, prior research has shown that in-context learning can suffer from high instability due to variations in training examples, example order, and prompt formats. Therefore, the construction of an appropriate prompt is essential for improving the performance of in-context learning. In this paper, we revisit this problem from the view of predictive bias. Specifically, we introduce a metric to evaluate the predictive bias of a fixed prompt against labels or a given attributes. Then we empirically show that prompts with higher bias always lead to unsatisfactory predictive quality. Based on this observation, we propose a novel search strategy based on the greedy search to identify the near-optimal prompt for improving the performance of in-context learning. We perform comprehensive experiments with state-of-the-art mainstream models such as GPT-3 on various downstream tasks. Our results indicate that our method can enhance the model's in-context learning performance in an effective and interpretable manner.
Federated Nearest Neighbor Machine Translation
Feb 23, 2023



To protect user privacy and meet legal regulations, federated learning (FL) is attracting significant attention. Training neural machine translation (NMT) models with traditional FL algorithm (e.g., FedAvg) typically relies on multi-round model-based interactions. However, it is impractical and inefficient for machine translation tasks due to the vast communication overheads and heavy synchronization. In this paper, we propose a novel federated nearest neighbor (FedNN) machine translation framework that, instead of multi-round model-based interactions, leverages one-round memorization-based interaction to share knowledge across different clients to build low-overhead privacy-preserving systems. The whole approach equips the public NMT model trained on large-scale accessible data with a $k$-nearest-neighbor ($$kNN) classifier and integrates the external datastore constructed by private text data in all clients to form the final FL model. A two-phase datastore encryption strategy is introduced to achieve privacy-preserving during this process. Extensive experiments show that FedNN significantly reduces computational and communication costs compared with FedAvg, while maintaining promising performance in different FL settings.
Neural Machine Translation with Contrastive Translation Memories
Dec 06, 2022Retrieval-augmented Neural Machine Translation models have been successful in many translation scenarios. Different from previous works that make use of mutually similar but redundant translation memories~(TMs), we propose a new retrieval-augmented NMT to model contrastively retrieved translation memories that are holistically similar to the source sentence while individually contrastive to each other providing maximal information gains in three phases. First, in TM retrieval phase, we adopt a contrastive retrieval algorithm to avoid redundancy and uninformativeness of similar translation pieces. Second, in memory encoding stage, given a set of TMs we propose a novel Hierarchical Group Attention module to gather both local context of each TM and global context of the whole TM set. Finally, in training phase, a Multi-TM contrastive learning objective is introduced to learn salient feature of each TM with respect to target sentence. Experimental results show that our framework obtains improvements over strong baselines on the benchmark datasets.
Discourse-Aware Graph Networks for Textual Logical Reasoning
Jul 04, 2022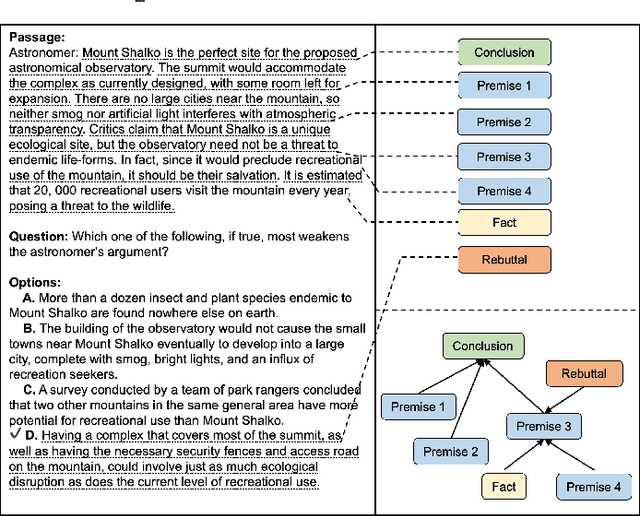
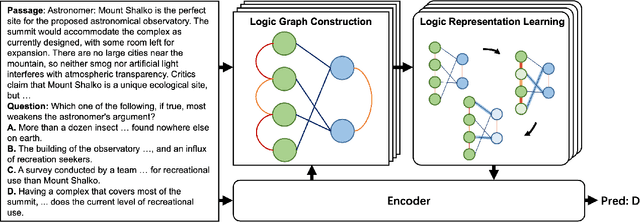
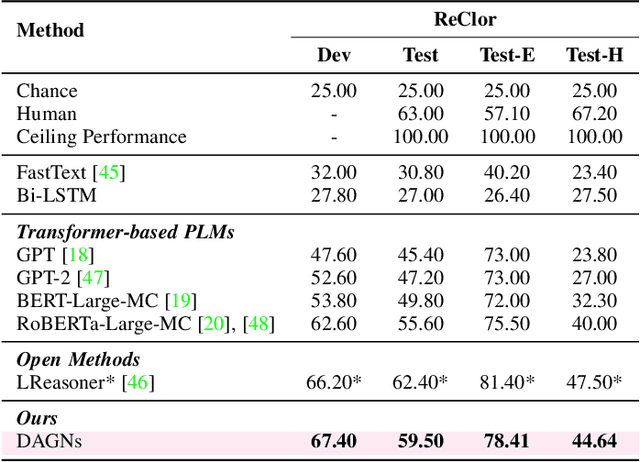
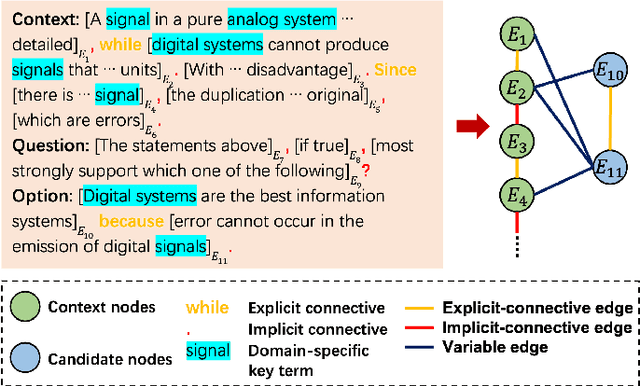
Textual logical reasoning, especially question answering (QA) tasks with logical reasoning, requires awareness of particular logical structures. The passage-level logical relations represent entailment or contradiction between propositional units (e.g., a concluding sentence). However, such structures are unexplored as current QA systems focus on entity-based relations. In this work, we propose logic structural-constraint modeling to solve the logical reasoning QA and introduce discourse-aware graph networks (DAGNs). The networks perform two procedures: (1) logic graph construction that leverages in-line discourse connectives as well as generic logic theories, (2) logic representation learning by graph networks that produces structural logic features. This pipeline is applied to a general encoder, whose fundamental features are joined with the high-level logic features for answer prediction. Experiments on three textual logical reasoning datasets demonstrate the reasonability of the logical structures built in DAGNs and the effectiveness of the learned logic features. Moreover, zero-shot transfer results show the features' generality to unseen logical texts.