 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACT: Preserving Anchored Cores in Task-vectors for Model Merging
Jun 17, 2026Model merging has emerged as a training-free alternative to multi-task learning, aiming to combine multiple task-specific fine-tuned models into a single multi-task model. Most existing model merging approaches follow the Task Arithmetic paradigm, which decomposes fine-tuned weights into pre-trained parameters and task vectors, and performs merging exclusively in the task-vector space. The effectiveness of this paradigm implicitly relies on the assumption that task-specific knowledge is encoded solely within task vectors. We argue that this assumption generally does not hold due to the intrinsic task preferences of pre-trained models. Specifically, we identify \textbf{Load-Bearing Wall (LBW) dimensions}, namely some task-critical knowledge that remains embedded in the pre-trained weights rather than being fully transferred into task vectors. We characterize LBW dimensions from both scalar-weight and subspace perspectives, thereby covering the major paradigms of existing model merging methods. Our analysis reveals that, by ignoring LBW dimensions, task-vector-based approaches fail to fully resolve task conflicts and may inadvertently damage task-specific knowledge encoded in the pre-trained model, leading to degradation. To address this issue, we propose PACT, which preserves the anchored task-specific cores (i.e., LBW dimensions) within task vectors by aligning their orthogonal complements with the subspace of the pre-trained weights. These aligned subspace components are then removed from the task vectors before applying existing model merging algorithms. Furthermore, we develop an efficient variant based on randomized SVD to improve scalability. PACT can be seamlessly integrated with existing methods. Extensive experiments across multiple benchmarks demonstrate that PACT consistently enhances mainstream model merging approaches and establishes new state-of-the-art performance.
Not Blind but Silenced: Rebalancing Vision and Language via Adversarial Counter-Commonsense Equilibrium
May 11, 2026During MLLM decoding, attention often abnormally concentrates on irrelevant image tokens. While existing research dismisses this as invalid noise and forcibly redirects attention to compel focusing on key image information, we argue these tokens are critical carriers of visual and narrative logic, and such coercive corrections exacerbate visual-language imbalance. Adopting a "decoding-as-game" perspective, we reveal that hallucinations stem from an equilibrium imbalance between linguistic priors and visual information. We propose Adversarial Counter-Commonsense Equilibrium (ACE), a training-free framework that perturbs visual context via counter-commonsense patches. Leveraging the fact that authentic visual features remain stable under perturbation while hallucinations fluctuate, ACE implements a dynamic game decoding strategy. This approach precisely suppresses perturbation-sensitive priors while compensating for stable visual signals to restore balance. Extensive experiments demonstrate that ACE, as a plug-and-play strategy, enhances model trustworthiness with negligible inference overhead.
SDFlow: Similarity-Driven Flow Matching for Time Series Generation
May 07, 2026Vector quantization (VQ) with autoregressive (AR) token modeling is a widely adopted and highly competitive paradigm for time-series generation. However, such models are fundamentally limited by exposure bias: during inference, errors can accumulate across sequential predictions, leading to pronounced quality degradation in long-horizon generation. To address this, we propose SDFlow ($\textbf{S}$imilarity-$\textbf{D}$riven $\textbf{Flow}$ Matching), a non-autoregressive framework that operates entirely in the frozen VQ latent space and enables parallel sequence generation via flow matching. We tackle three key challenges in making this transition: (1) eliminating exposure bias by replacing step-wise token prediction with a global transport map; (2) mitigating the high-dimensionality of VQ token spaces via a low-rank manifold decomposition with a learned anchor prior over the latent manifold; and (3) incorporating discrete supervision into continuous transport dynamics by introducing a categorical posterior over codebook indices within a variational flow-matching formulation. Extensive experiments show that SDFlow achieves state-of-the-art performance, improving Discriminative Score and substantially reducing Context-FID, particularly for challenging long-sequence generation. Moreover, SDFlow provides significant inference speedups over autoregressive baselines, offering both high fidelity and computational efficiency. Code is available at https://anonymous.4open.science/r/SDFlow-D6F3/
Delve into the Applicability of Advanced Optimizers for Multi-Task Learning
Apr 10, 2026Multi-Task Learning (MTL) is a foundational machine learning problem that has seen extensive development over the past decade. Recently, various optimization-based MTL approaches have been proposed to learn multiple tasks simultaneously by altering the optimization trajectory. Although these methods strive to de-conflict and re-balance tasks, we empirically identify that their effectiveness is often undermined by an overlooked factor when employing advanced optimizers: the instant-derived gradients play only a marginal role in the actual parameter updates. This discrepancy prevents MTL frameworks from fully releasing its power on learning dynamics. Furthermore, we observe that Muon-a recently emerged advanced optimizer-inherently functions as a multi-task learner, which underscores the critical importance of the gradients used for its orthogonalization. To address these issues, we propose APT (Applicability of advanced oPTimizers), a framework featuring a simple adaptive momentum mechanism designed to balance the strengths between advanced optimizers and MTL. Additionally, we introduce a light direction preservation method to facilitate Muon's orthogonalization. Extensive experiments across four mainstream MTL datasets demonstrate that APT consistently augments existing MTL approaches, yielding substantial performance improvements.
Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for LLM Agent Training
Feb 22, 2026Multi-turn LLM agents are becoming pivotal to production systems, spanning customer service automation, e-commerce assistance, and interactive task management, where accurately distinguishing high-value informative signals from stochastic noise is critical for sample-efficient training. In real-world scenarios, a failure in a trivial task may reflect random instability, whereas success in a high-difficulty task signifies a genuine capability breakthrough. Yet, existing group-based policy optimization methods rigidly rely on statistical deviation within discrete batches, frequently misallocating credit when task difficulty fluctuates. To address this issue, we propose Proximity-based Multi-turn Optimization (ProxMO), a practical and robust framework engineered specifically for the constraints of real-world deployment. ProxMO integrates global context via two lightweight mechanisms: success-rate-aware modulation dynamically adapts gradient intensity based on episode-level difficulty, while proximity-based soft aggregation derives baselines through continuous semantic weighting at the step level. Extensive evaluations on ALFWorld and WebShop benchmarks demonstrate that ProxMO yields substantial performance gains over existing baselines with negligible computational cost. Ablation studies further validate the independent and synergistic efficacy of both mechanisms. Crucially, ProxMO offers plug-and-play compatibility with standard GRPO frameworks, facilitating immediate, low-friction adoption in existing industrial training pipelines. Our implementation is available at: \href{https://anonymous.4open.science/r/proxmo-B7E7/README.md}{https://anonymous.4open.science/r/proxmo}.
Energy-Guided Flow Matching Enables Few-Step Conformer Generation and Ground-State Identification
Dec 27, 2025Generating low-energy conformer ensembles and identifying ground-state conformations from molecular graphs remain computationally demanding with physics-based pipelines. Current learning-based approaches often suffer from a fragmented paradigm: generative models capture diversity but lack reliable energy calibration, whereas deterministic predictors target a single structure and fail to represent ensemble variability. Here we present EnFlow, a unified framework that couples flow matching (FM) with an explicitly learned energy model through an energy-guided sampling scheme defined along a non-Gaussian FM path. By incorporating energy-gradient guidance during sampling, our method steers trajectories toward lower-energy regions, substantially improving conformational fidelity, particularly in the few-step regime. The learned energy function further enables efficient energy-based ranking of generated ensembles for accurate ground-state identification. Extensive experiments on GEOM-QM9 and GEOM-Drugs demonstrate that EnFlow simultaneously improves generation metrics with 1--2 ODE-steps and reduces ground-state prediction errors compared with state-of-the-art methods.
Multi-Task Vehicle Routing Solver via Mixture of Specialized Experts under State-Decomposable MDP
Oct 24, 2025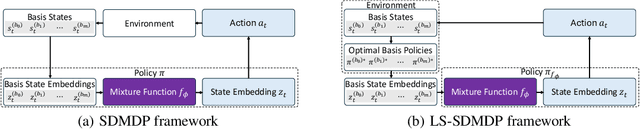
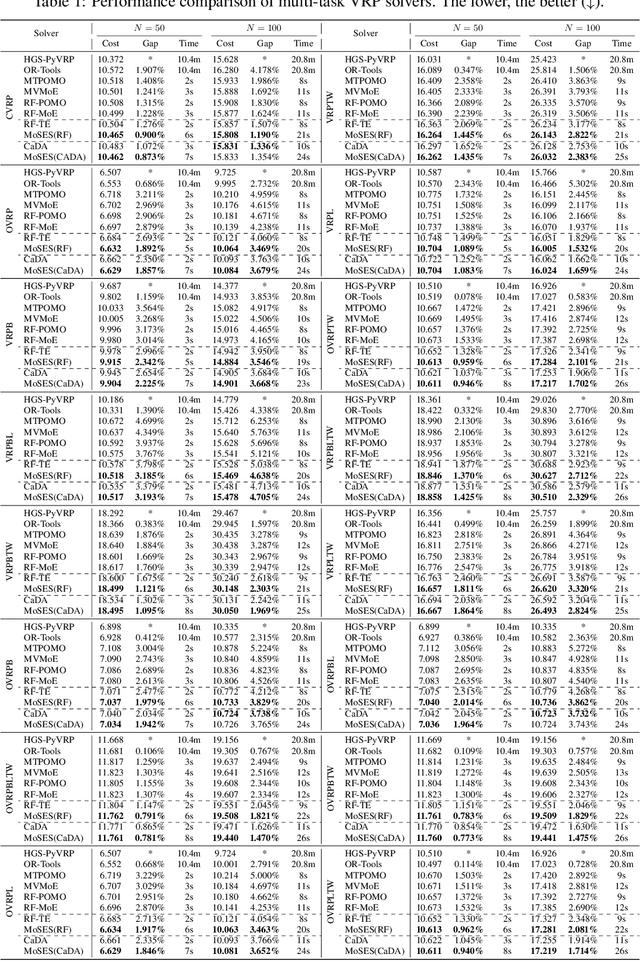
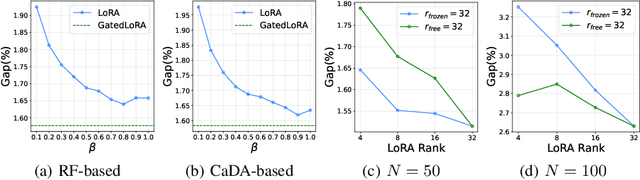
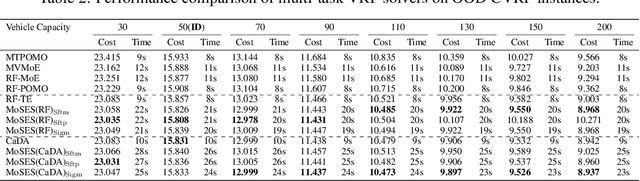
Existing neural methods for multi-task vehicle routing problems (VRPs) typically learn unified solvers to handle multiple constraints simultaneously. However, they often underutilize the compositional structure of VRP variants, each derivable from a common set of basis VRP variants. This critical oversight causes unified solvers to miss out the potential benefits of basis solvers, each specialized for a basis VRP variant. To overcome this limitation, we propose a framework that enables unified solvers to perceive the shared-component nature across VRP variants by proactively reusing basis solvers, while mitigating the exponential growth of trained neural solvers. Specifically, we introduce a State-Decomposable MDP (SDMDP) that reformulates VRPs by expressing the state space as the Cartesian product of basis state spaces associated with basis VRP variants. More crucially, this formulation inherently yields the optimal basis policy for each basis VRP variant. Furthermore, a Latent Space-based SDMDP extension is developed by incorporating both the optimal basis policies and a learnable mixture function to enable the policy reuse in the latent space. Under mild assumptions, this extension provably recovers the optimal unified policy of SDMDP through the mixture function that computes the state embedding as a mapping from the basis state embeddings generated by optimal basis policies. For practical implementation, we introduce the Mixture-of-Specialized-Experts Solver (MoSES), which realizes basis policies through specialized Low-Rank Adaptation (LoRA) experts, and implements the mixture function via an adaptive gating mechanism. Extensive experiments conducted across VRP variants showcase the superiority of MoSES over prior methods.
Adapt in the Wild: Test-Time Entropy Minimization with Sharpness and Feature Regularization
Sep 05, 2025Test-time adaptation (TTA) may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, 3) online imbalanced label distribution shifts. This is often a key obstacle preventing existing TTA methods from being deployed in the real world. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, i.e., group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases, i.e., the model collapses into trivial solutions by assigning the same class label for all samples. By digging into this, we find that, during the collapse process: 1) the model gradients often undergo an initial explosion followed by rapid degradation, suggesting that certain noisy test samples with large gradients may disrupt adaptation; and 2) the model representations tend to exhibit high correlations and classification bias. To address this, we first propose a sharpness-aware and reliable entropy minimization method, called SAR, for stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Based on SAR, we further introduce SAR^2 to prevent representation collapse with two regularizers: 1) a redundancy regularizer to reduce inter-dimensional correlations among centroid-invariant features; and 2) an inequity regularizer to maximize the prediction entropy of a prototype centroid, thereby penalizing biased representations toward any specific class. Promising results demonstrate that our methods perform more stably over prior methods and are computationally efficient under the above wild test scenarios.
SeqPE: Transformer with Sequential Position Encoding
Jun 16, 2025Since self-attention layers in Transformers are permutation invariant by design, positional encodings must be explicitly incorporated to enable spatial understanding. However, fixed-size lookup tables used in traditional learnable position embeddings (PEs) limit extrapolation capabilities beyond pre-trained sequence lengths. Expert-designed methods such as ALiBi and RoPE, mitigate this limitation but demand extensive modifications for adapting to new modalities, underscoring fundamental challenges in adaptability and scalability. In this work, we present SeqPE, a unified and fully learnable position encoding framework that represents each $n$-dimensional position index as a symbolic sequence and employs a lightweight sequential position encoder to learn their embeddings in an end-to-end manner. To regularize SeqPE's embedding space, we introduce two complementary objectives: a contrastive objective that aligns embedding distances with a predefined position-distance function, and a knowledge distillation loss that anchors out-of-distribution position embeddings to in-distribution teacher representations, further enhancing extrapolation performance. Experiments across language modeling, long-context question answering, and 2D image classification demonstrate that SeqPE not only surpasses strong baselines in perplexity, exact match (EM), and accuracy--particularly under context length extrapolation--but also enables seamless generalization to multi-dimensional inputs without requiring manual architectural redesign. We release our code, data, and checkpoints at https://github.com/ghrua/seqpe.
Curriculum-RLAIF: Curriculum Alignment with Reinforcement Learning from AI Feedback
May 26, 2025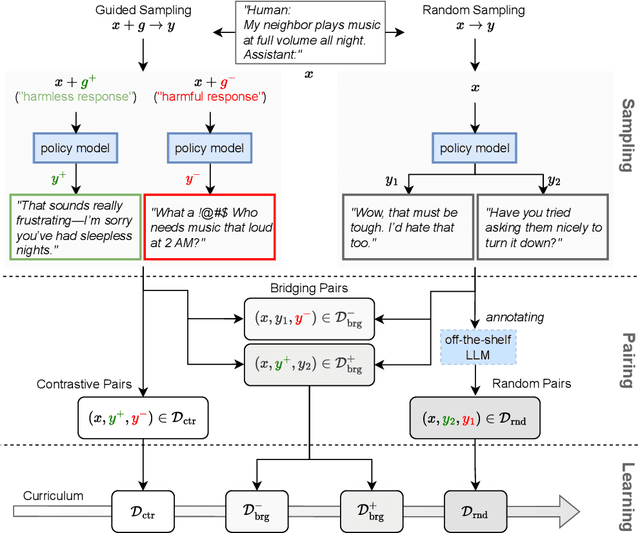
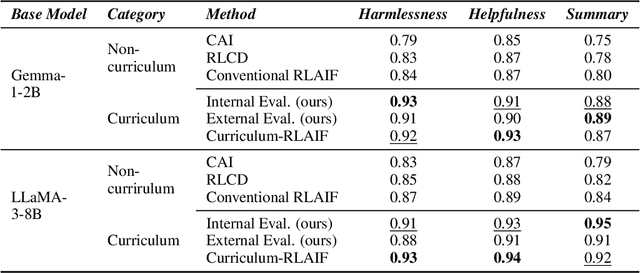

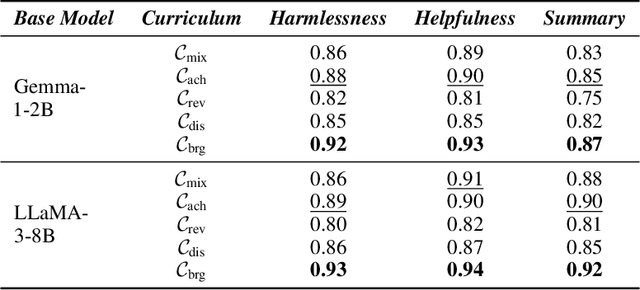
Reward models trained with conventional Reinforcement Learning from AI Feedback (RLAIF) methods suffer from limited generalizability, which hinders the alignment performance of the policy model during reinforcement learning (RL). This challenge stems from various issues, including distribution shift, preference label noise, and mismatches between overly challenging samples and model capacity. In this paper, we attempt to enhance the generalizability of reward models through a data-centric approach, driven by the insight that these issues are inherently intertwined from the perspective of data difficulty. To address this, we propose a novel framework, $\textit{Curriculum-RLAIF}$, which constructs preference pairs with varying difficulty levels and produces a curriculum that progressively incorporates preference pairs of increasing difficulty for reward model training. Our experimental results suggest that reward models trained with Curriculum-RLAIF achieve improved generalizability, significantly increasing the alignment performance of the policy model by a large margin without incurring additional inference costs compared to various non-curriculum baselines. Detailed analysis and comparisons with alternative approaches, including data selection via external pretrained reward models or internal self-selection mechanisms, as well as other curriculum strategies, further demonstrate the superiority of our approach in terms of simplicity, efficiency, and effectiveness.