 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTENG-BC: Unified Time-Evolving Natural Gradient for Neural PDE Solvers with General Boundary Conditions
Feb 28, 2026Accurately solving time-dependent partial differential equations (PDEs) with neural networks remains challenging due to long-time error accumulation and the difficulty of enforcing general boundary conditions. We introduce TENG-BC, a high-precision neural PDE solver based on the Time-Evolving Natural Gradient, designed to perform under general boundary constraints. At each time step, TENG-BC performs a boundary-aware optimization that jointly enforces interior dynamics and boundary conditions, accommodating Dirichlet, Neumann, Robin, and mixed types within a unified framework. This formulation admits a natural-gradient interpretation, enabling stable time evolution without delicate penalty tuning. Across benchmarks over diffusion, transport, and nonlinear PDEs with various boundary conditions, TENG-BC achieves solver-level accuracy under comparable sampling budgets, outperforming conventional solvers and physics-informed neural network (PINN) baselines.
Agile asymmetric multi-legged locomotion: contact planning via geometric mechanics and spin model duality
Feb 09, 2026Legged robot research is presently focused on bipedal or quadrupedal robots, despite capabilities to build robots with many more legs to potentially improve locomotion performance. This imbalance is not necessarily due to hardware limitations, but rather to the absence of principled control frameworks that explain when and how additional legs improve locomotion performance. In multi-legged systems, coordinating many simultaneous contacts introduces a severe curse of dimensionality that challenges existing modeling and control approaches. As an alternative, multi-legged robots are typically controlled using low-dimensional gaits originally developed for bipeds or quadrupeds. These strategies fail to exploit the new symmetries and control opportunities that emerge in higher-dimensional systems. In this work, we develop a principled framework for discovering new control structures in multi-legged locomotion. We use geometric mechanics to reduce contact-rich locomotion planning to a graph optimization problem, and propose a spin model duality framework from statistical mechanics to exploit symmetry breaking and guide optimal gait reorganization. Using this approach, we identify an asymmetric locomotion strategy for a hexapod robot that achieves a forward speed of 0.61 body lengths per cycle (a 50% improvement over conventional gaits). The resulting asymmetry appears at both the control and hardware levels. At the control level, the body orientation oscillates asymmetrically between fast clockwise and slow counterclockwise turning phases for forward locomotion. At the hardware level, two legs on the same side remain unactuated and can be replaced with rigid parts without degrading performance. Numerical simulations and robophysical experiments validate the framework and reveal novel locomotion behaviors that emerge from symmetry reforming in high-dimensional embodied systems.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025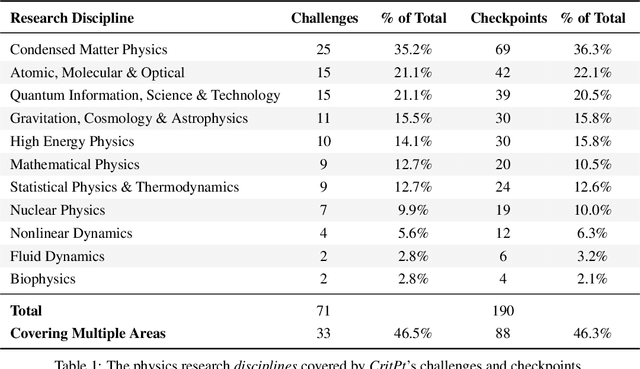



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
A universal compression theory: Lottery ticket hypothesis and superpolynomial scaling laws
Oct 01, 2025When training large-scale models, the performance typically scales with the number of parameters and the dataset size according to a slow power law. A fundamental theoretical and practical question is whether comparable performance can be achieved with significantly smaller models and substantially less data. In this work, we provide a positive and constructive answer. We prove that a generic permutation-invariant function of $d$ objects can be asymptotically compressed into a function of $\operatorname{polylog} d$ objects with vanishing error. This theorem yields two key implications: (Ia) a large neural network can be compressed to polylogarithmic width while preserving its learning dynamics; (Ib) a large dataset can be compressed to polylogarithmic size while leaving the loss landscape of the corresponding model unchanged. (Ia) directly establishes a proof of the \textit{dynamical} lottery ticket hypothesis, which states that any ordinary network can be strongly compressed such that the learning dynamics and result remain unchanged. (Ib) shows that a neural scaling law of the form $L\sim d^{-\alpha}$ can be boosted to an arbitrarily fast power law decay, and ultimately to $\exp(-\alpha' \sqrt[m]{d})$.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
PhySense: Principle-Based Physics Reasoning Benchmarking for Large Language Models
May 30, 2025



Large language models (LLMs) have rapidly advanced and are increasingly capable of tackling complex scientific problems, including those in physics. Despite this progress, current LLMs often fail to emulate the concise, principle-based reasoning characteristic of human experts, instead generating lengthy and opaque solutions. This discrepancy highlights a crucial gap in their ability to apply core physical principles for efficient and interpretable problem solving. To systematically investigate this limitation, we introduce PhySense, a novel principle-based physics reasoning benchmark designed to be easily solvable by experts using guiding principles, yet deceptively difficult for LLMs without principle-first reasoning. Our evaluation across multiple state-of-the-art LLMs and prompt types reveals a consistent failure to align with expert-like reasoning paths, providing insights for developing AI systems with efficient, robust and interpretable principle-based scientific reasoning.
Provably Robust Training of Quantum Circuit Classifiers Against Parameter Noise
May 24, 2025Advancements in quantum computing have spurred significant interest in harnessing its potential for speedups over classical systems. However, noise remains a major obstacle to achieving reliable quantum algorithms. In this work, we present a provably noise-resilient training theory and algorithm to enhance the robustness of parameterized quantum circuit classifiers. Our method, with a natural connection to Evolutionary Strategies, guarantees resilience to parameter noise with minimal adjustments to commonly used optimization algorithms. Our approach is function-agnostic and adaptable to various quantum circuits, successfully demonstrated in quantum phase classification tasks. By developing provably guaranteed optimization theory with quantum circuits, our work opens new avenues for practical, robust applications of near-term quantum computers.
Advancing AI-Scientist Understanding: Making LLM Think Like a Physicist with Interpretable Reasoning
Apr 02, 2025



Large Language Models (LLMs) are playing an expanding role in physics research by enhancing reasoning, symbolic manipulation, and numerical computation. However, ensuring the reliability and interpretability of their outputs remains a significant challenge. In our framework, we conceptualize the collaboration between AI and human scientists as a dynamic interplay among three modules: the reasoning module, the interpretation module, and the AI-scientist interaction module. Recognizing that effective physics reasoning demands rigorous logical consistency, quantitative precision, and deep integration with established theoretical models, we introduce the interpretation module to improve the understanding of AI-generated outputs, which is not previously explored in the literature. This module comprises multiple specialized agents, including summarizers, model builders, UI builders, and testers, which collaboratively structure LLM outputs within a physically grounded framework, by constructing a more interpretable science model. A case study demonstrates that our approach enhances transparency, facilitates validation, and strengthens AI-augmented reasoning in scientific discovery.
L$^2$M: Mutual Information Scaling Law for Long-Context Language Modeling
Mar 06, 2025



We rigorously establish a bipartite mutual information scaling law in natural language that governs long-range dependencies. This scaling law, which we show is distinct from and scales independently of the conventional two-point mutual information, is the key to understanding long-context language modeling. Using this scaling law, we formulate the Long-context Language Modeling (L$^2$M) condition, which relates a model's capacity for effective long context length modeling to the scaling of its latent state size for storing past information. Our results are validated through experiments on both transformers and state space models. This work establishes a theoretical foundation that guides the development of large language models toward longer context lengths.