 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Signals: A Diverse Point Cloud Dataset for Heterogeneous LiDAR V2X Collaboration
Feb 19, 2025Vehicle-to-everything (V2X) collaborative perception has emerged as a promising solution to address the limitations of single-vehicle perception systems. However, existing V2X datasets are limited in scope, diversity, and quality. To address these gaps, we present Mixed Signals, a comprehensive V2X dataset featuring 45.1k point clouds and 240.6k bounding boxes collected from three connected autonomous vehicles (CAVs) equipped with two different types of LiDAR sensors, plus a roadside unit with dual LiDARs. Our dataset provides precisely aligned point clouds and bounding box annotations across 10 classes, ensuring reliable data for perception training. We provide detailed statistical analysis on the quality of our dataset and extensively benchmark existing V2X methods on it. Mixed Signals V2X Dataset is one of the highest quality, large-scale datasets publicly available for V2X perception research. Details on the website https://mixedsignalsdataset.cs.cornell.edu/.
Transfer Your Perspective: Controllable 3D Generation from Any Viewpoint in a Driving Scene
Feb 10, 2025



Self-driving cars relying solely on ego-centric perception face limitations in sensing, often failing to detect occluded, faraway objects. Collaborative autonomous driving (CAV) seems like a promising direction, but collecting data for development is non-trivial. It requires placing multiple sensor-equipped agents in a real-world driving scene, simultaneously! As such, existing datasets are limited in locations and agents. We introduce a novel surrogate to the rescue, which is to generate realistic perception from different viewpoints in a driving scene, conditioned on a real-world sample - the ego-car's sensory data. This surrogate has huge potential: it could potentially turn any ego-car dataset into a collaborative driving one to scale up the development of CAV. We present the very first solution, using a combination of simulated collaborative data and real ego-car data. Our method, Transfer Your Perspective (TYP), learns a conditioned diffusion model whose output samples are not only realistic but also consistent in both semantics and layouts with the given ego-car data. Empirical results demonstrate TYP's effectiveness in aiding in a CAV setting. In particular, TYP enables us to (pre-)train collaborative perception algorithms like early and late fusion with little or no real-world collaborative data, greatly facilitating downstream CAV applications.
Learning 3D Perception from Others' Predictions
Oct 03, 2024



Accurate 3D object detection in real-world environments requires a huge amount of annotated data with high quality. Acquiring such data is tedious and expensive, and often needs repeated effort when a new sensor is adopted or when the detector is deployed in a new environment. We investigate a new scenario to construct 3D object detectors: learning from the predictions of a nearby unit that is equipped with an accurate detector. For example, when a self-driving car enters a new area, it may learn from other traffic participants whose detectors have been optimized for that area. This setting is label-efficient, sensor-agnostic, and communication-efficient: nearby units only need to share the predictions with the ego agent (e.g., car). Naively using the received predictions as ground-truths to train the detector for the ego car, however, leads to inferior performance. We systematically study the problem and identify viewpoint mismatches and mislocalization (due to synchronization and GPS errors) as the main causes, which unavoidably result in false positives, false negatives, and inaccurate pseudo labels. We propose a distance-based curriculum, first learning from closer units with similar viewpoints and subsequently improving the quality of other units' predictions via self-training. We further demonstrate that an effective pseudo label refinement module can be trained with a handful of annotated data, largely reducing the data quantity necessary to train an object detector. We validate our approach on the recently released real-world collaborative driving dataset, using reference cars' predictions as pseudo labels for the ego car. Extensive experiments including several scenarios (e.g., different sensors, detectors, and domains) demonstrate the effectiveness of our approach toward label-efficient learning of 3D perception from other units' predictions.
Sample-Efficient Diffusion for Text-To-Speech Synthesis
Sep 01, 2024



This work introduces Sample-Efficient Speech Diffusion (SESD), an algorithm for effective speech synthesis in modest data regimes through latent diffusion. It is based on a novel diffusion architecture, that we call U-Audio Transformer (U-AT), that efficiently scales to long sequences and operates in the latent space of a pre-trained audio autoencoder. Conditioned on character-aware language model representations, SESD achieves impressive results despite training on less than 1k hours of speech - far less than current state-of-the-art systems. In fact, it synthesizes more intelligible speech than the state-of-the-art auto-regressive model, VALL-E, while using less than 2% the training data.
Diffusion Guided Language Modeling
Aug 08, 2024



Current language models demonstrate remarkable proficiency in text generation. However, for many applications it is desirable to control attributes, such as sentiment, or toxicity, of the generated language -- ideally tailored towards each specific use case and target audience. For auto-regressive language models, existing guidance methods are prone to decoding errors that cascade during generation and degrade performance. In contrast, text diffusion models can easily be guided with, for example, a simple linear sentiment classifier -- however they do suffer from significantly higher perplexity than auto-regressive alternatives. In this paper we use a guided diffusion model to produce a latent proposal that steers an auto-regressive language model to generate text with desired properties. Our model inherits the unmatched fluency of the auto-regressive approach and the plug-and-play flexibility of diffusion. We show that it outperforms previous plug-and-play guidance methods across a wide range of benchmark data sets. Further, controlling a new attribute in our framework is reduced to training a single logistic regression classifier.
On Speeding Up Language Model Evaluation
Jul 08, 2024Large language models (LLMs) currently dominate the field of natural language processing (NLP), representing the state-of-the-art across a diverse array of tasks. Developing a model of this nature, from training to inference, requires making numerous decisions which define a combinatorial search problem. For example, selecting the optimal pre-trained LLM, prompt, or hyperparameters to attain the best performance for a task often requires evaluating multiple candidates on an entire test set. This exhaustive evaluation can be time-consuming and costly, as both inference and metric computation with LLMs are resource-intensive. In this paper, we address the challenge of identifying the best method within a limited budget for evaluating methods on test examples. By leveraging the well-studied multi-armed bandit framework, which sequentially selects the next method-example pair to evaluate, our approach, combining multi-armed bandit algorithms with low-rank factorization, significantly reduces the required resources. Experiments show that our algorithms can identify the top-performing method using only 5-15\% of the typically needed resources, resulting in an 85-95\% reduction in cost.
Orchestrating LLMs with Different Personalizations
Jul 04, 2024



This paper presents a novel approach to aligning large language models (LLMs) with individual human preferences, sometimes referred to as Reinforcement Learning from \textit{Personalized} Human Feedback (RLPHF). Given stated preferences along multiple dimensions, such as helpfulness, conciseness, or humor, the goal is to create an LLM without re-training that best adheres to this specification. Starting from specialized expert LLMs, each trained for one such particular preference dimension, we propose a black-box method that merges their outputs on a per-token level. We train a lightweight Preference Control Model (PCM) that dynamically translates the preference description and current context into next-token prediction weights. By combining the expert models' outputs at the token level, our approach dynamically generates text that optimizes the given preference. Empirical tests show that our method matches or surpasses existing preference merging techniques, providing a scalable, efficient alternative to fine-tuning LLMs for individual personalization.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024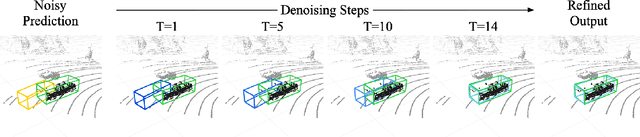
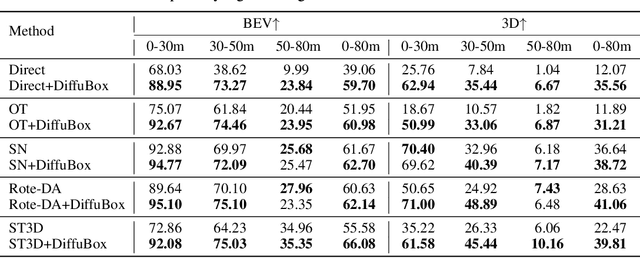
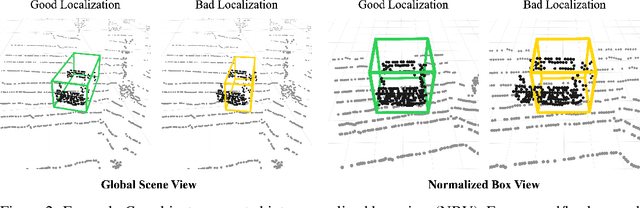
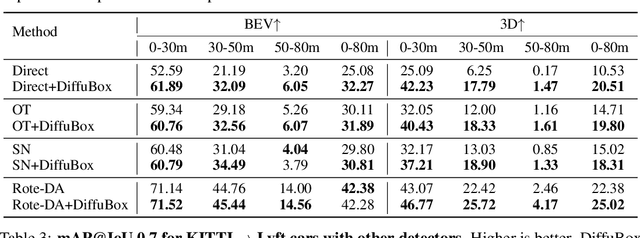
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Don't Trust: Verify -- Grounding LLM Quantitative Reasoning with Autoformalization
Mar 26, 2024Large language models (LLM), such as Google's Minerva and OpenAI's GPT families, are becoming increasingly capable of solving mathematical quantitative reasoning problems. However, they still make unjustified logical and computational errors in their reasoning steps and answers. In this paper, we leverage the fact that if the training corpus of LLMs contained sufficiently many examples of formal mathematics (e.g. in Isabelle, a formal theorem proving environment), they can be prompted to translate i.e. autoformalize informal mathematical statements into formal Isabelle code -- which can be verified automatically for internal consistency. This provides a mechanism to automatically reject solutions whose formalized versions are inconsistent within themselves or with the formalized problem statement. We evaluate our method on GSM8K, MATH and MultiArith datasets and demonstrate that our approach provides a consistently better heuristic than vanilla majority voting -- the previously best method to identify correct answers, by more than 12% on GSM8K. In our experiments it improves results consistently across all datasets and LLM model sizes. The code can be found at https://github.com/jinpz/dtv.
Zero-shot Object-Level OOD Detection with Context-Aware Inpainting
Feb 07, 2024



Machine learning algorithms are increasingly provided as black-box cloud services or pre-trained models, without access to their training data. This motivates the problem of zero-shot out-of-distribution (OOD) detection. Concretely, we aim to detect OOD objects that do not belong to the classifier's label set but are erroneously classified as in-distribution (ID) objects. Our approach, RONIN, uses an off-the-shelf diffusion model to replace detected objects with inpainting. RONIN conditions the inpainting process with the predicted ID label, drawing the input object closer to the in-distribution domain. As a result, the reconstructed object is very close to the original in the ID cases and far in the OOD cases, allowing RONIN to effectively distinguish ID and OOD samples. Throughout extensive experiments, we demonstrate that RONIN achieves competitive results compared to previous approaches across several datasets, both in zero-shot and non-zero-shot settings.