 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Monocular Segmentation-Based Mapping for Appearance and View-Invariant Global Localization
Jul 15, 2025Global localization is critical for autonomous navigation, particularly in scenarios where an agent must localize within a map generated in a different session or by another agent, as agents often have no prior knowledge about the correlation between reference frames. However, this task remains challenging in unstructured environments due to appearance changes induced by viewpoint variation, seasonal changes, spatial aliasing, and occlusions -- known failure modes for traditional place recognition methods. To address these challenges, we propose VISTA (View-Invariant Segmentation-Based Tracking for Frame Alignment), a novel open-set, monocular global localization framework that combines: 1) a front-end, object-based, segmentation and tracking pipeline, followed by 2) a submap correspondence search, which exploits geometric consistencies between environment maps to align vehicle reference frames. VISTA enables consistent localization across diverse camera viewpoints and seasonal changes, without requiring any domain-specific training or finetuning. We evaluate VISTA on seasonal and oblique-angle aerial datasets, achieving up to a 69% improvement in recall over baseline methods. Furthermore, we maintain a compact object-based map that is only 0.6% the size of the most memory-conservative baseline, making our approach capable of real-time implementation on resource-constrained platforms.
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
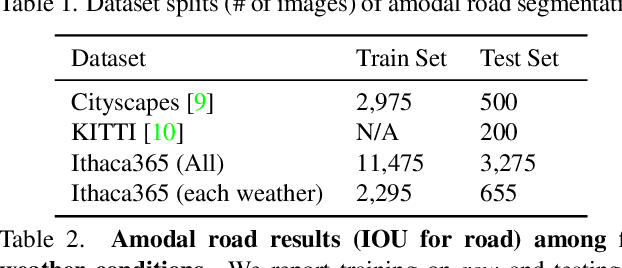
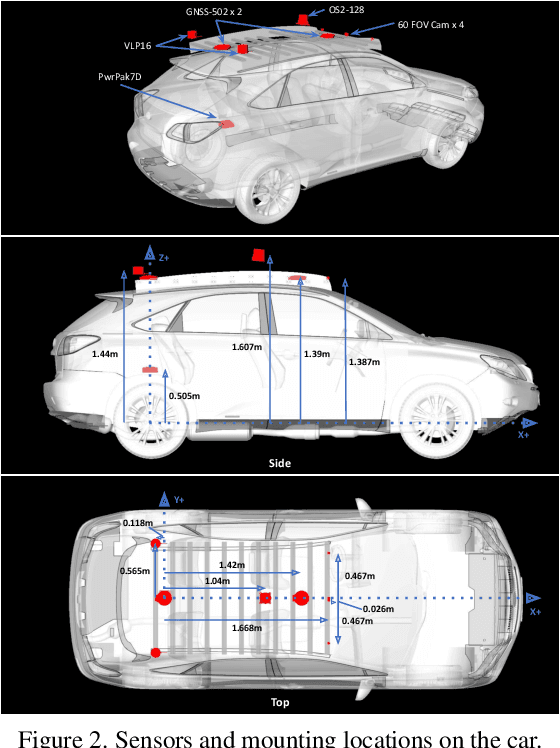
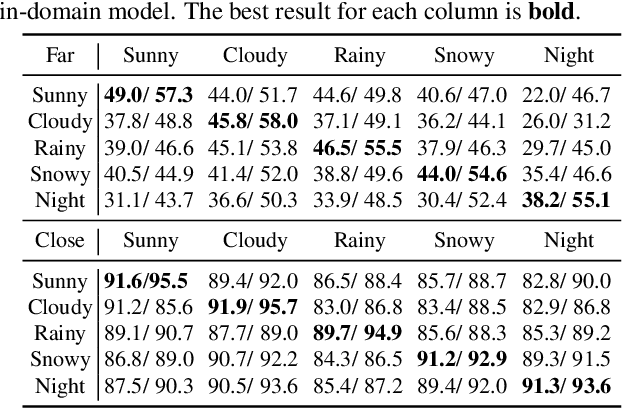
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/