 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Transcription with (Almost) No Supervision
May 22, 2026Competitive music transcription models require large amounts of paired audio-score data, which is scarce due to collection costs, alignment difficulty, and copyright restrictions. Meanwhile, vast quantities of unpaired audio recordings and symbolic scores are freely available but have gone unused. We adopt a cycle-consistent translation framework in which a small amount of paired data acts as a minimal anchor, unlocking the full potential of the unpaired pool. We find that: unpaired data yields surprisingly large gains, especially under limited supervision; unpaired audio contributes more than unpaired scores; incorporating unlabeled audio from a new instrument during training improves transcription for that instrument without any paired supervision. Together, these results suggest that scaling unpaired data offers a practical path toward high-quality transcription for instruments where labeled data remains scarce.
Attention in Space: Functional Roles of VLM Heads for Spatial Reasoning
Mar 21, 2026Despite remarkable advances in large Vision-Language Models (VLMs), spatial reasoning remains a persistent challenge. In this work, we investigate how attention heads within VLMs contribute to spatial reasoning by analyzing their functional roles through a mechanistic interpretability lens. We introduce CogVSR, a dataset that decomposes complex spatial reasoning questions into step-by-step subquestions designed to simulate human-like reasoning via a chain-of-thought paradigm, with each subquestion linked to specific cognitive functions such as spatial perception or relational reasoning. Building on CogVSR, we develop a probing framework to identify and characterize attention heads specialized for these functions. Our analysis across diverse VLM families reveals that these functional heads are universally sparse, vary in number and distribution across functions. Notably, spatially specialized heads are fewer than those for other cognitive functions, highlighting their scarcity. We propose methods to activate latent spatial heads, improving spatial understanding. Intervention experiments further demonstrate their critical role in spatial reasoning: removing functional heads leads to performance degradation, while emphasizing them enhances accuracy. This study provides new interpretability driven insights into how VLMs attend to space and paves the way for enhancing complex spatial reasoning in multimodal models.
When the City Teaches the Car: Label-Free 3D Perception from Infrastructure
Mar 17, 2026Building robust 3D perception for self-driving still relies heavily on large-scale data collection and manual annotation, yet this paradigm becomes impractical as deployment expands across diverse cities and regions. Meanwhile, modern cities are increasingly instrumented with roadside units (RSUs), static sensors deployed along roads and at intersections to monitor traffic. This raises a natural question: can the city itself help train the vehicle? We propose infrastructure-taught, label-free 3D perception, a paradigm in which RSUs act as stationary, unsupervised teachers for ego vehicles. Leveraging their fixed viewpoints and repeated observations, RSUs learn local 3D detectors from unlabeled data and broadcast predictions to passing vehicles, which are aggregated as pseudo-label supervision for training a standalone ego detector. The resulting model requires no infrastructure or communication at test time. We instantiate this idea as a fully label-free three-stage pipeline and conduct a concept-and-feasibility study in a CARLA-based multi-agent environment. With CenterPoint, our pipeline achieves 82.3% AP for detecting vehicles, compared to a fully supervised ego upper bound of 94.4%. We further systematically analyze each stage, evaluate its scalability, and demonstrate complementarity with existing ego-centric label-free methods. Together, these results suggest that city infrastructure itself can potentially provide a scalable supervisory signal for autonomous vehicles, positioning infrastructure-taught learning as a promising orthogonal paradigm for reducing annotation cost in 3D perception.
On the Feasibility and Opportunity of Autoregressive 3D Object Detection
Mar 09, 2026LiDAR-based 3D object detectors typically rely on proposal heads with hand-crafted components like anchor assignment and non-maximum suppression (NMS), complicating training and limiting extensibility. We present AutoReg3D, an autoregressive 3D detector that casts detection as sequence generation. Given point-cloud features, AutoReg3D emits objects in a range-causal (near-to-far) order and encodes each object as a short, discrete-token sequence consisting of its center, size, orientation, velocity, and class. This near-to-far ordering mirrors LiDAR geometry--near objects occlude far ones but not vice versa--enabling straightforward teacher forcing during training and autoregressive decoding at test time. AutoReg3D is compatible across diverse point-cloud or backbones and attains competitive nuScenes performance without anchors or NMS. Beyond parity, the sequential formulation unlocks language-model advances for 3D perception, including GRPO-style reinforcement learning for task-aligned objectives. These results position autoregressive decoding as a viable, flexible alternative for LiDAR-based detection and open a path to importing modern sequence-modeling tools into 3D perception.
Benchmark Datasets for Lead-Lag Forecasting on Social Platforms
Nov 05, 2025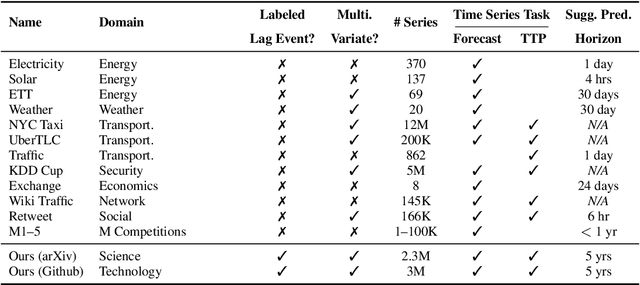


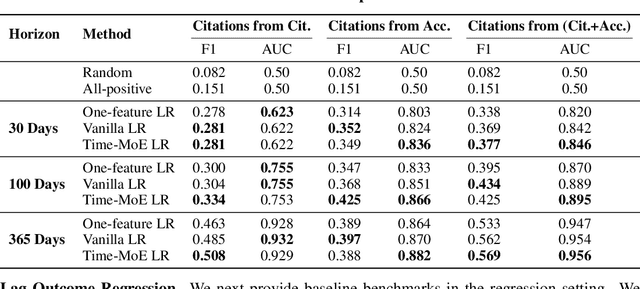
Social and collaborative platforms emit multivariate time-series traces in which early interactions-such as views, likes, or downloads-are followed, sometimes months or years later, by higher impact like citations, sales, or reviews. We formalize this setting as Lead-Lag Forecasting (LLF): given an early usage channel (the lead), predict a correlated but temporally shifted outcome channel (the lag). Despite the ubiquity of such patterns, LLF has not been treated as a unified forecasting problem within the time-series community, largely due to the absence of standardized datasets. To anchor research in LLF, here we present two high-volume benchmark datasets-arXiv (accesses -> citations of 2.3M papers) and GitHub (pushes/stars -> forks of 3M repositories)-and outline additional domains with analogous lead-lag dynamics, including Wikipedia (page views -> edits), Spotify (streams -> concert attendance), e-commerce (click-throughs -> purchases), and LinkedIn profile (views -> messages). Our datasets provide ideal testbeds for lead-lag forecasting, by capturing long-horizon dynamics across years, spanning the full spectrum of outcomes, and avoiding survivorship bias in sampling. We documented all technical details of data curation and cleaning, verified the presence of lead-lag dynamics through statistical and classification tests, and benchmarked parametric and non-parametric baselines for regression. Our study establishes LLF as a novel forecasting paradigm and lays an empirical foundation for its systematic exploration in social and usage data. Our data portal with downloads and documentation is available at https://lead-lag-forecasting.github.io/.
Mixed Signals: A Diverse Point Cloud Dataset for Heterogeneous LiDAR V2X Collaboration
Feb 19, 2025Vehicle-to-everything (V2X) collaborative perception has emerged as a promising solution to address the limitations of single-vehicle perception systems. However, existing V2X datasets are limited in scope, diversity, and quality. To address these gaps, we present Mixed Signals, a comprehensive V2X dataset featuring 45.1k point clouds and 240.6k bounding boxes collected from three connected autonomous vehicles (CAVs) equipped with two different types of LiDAR sensors, plus a roadside unit with dual LiDARs. Our dataset provides precisely aligned point clouds and bounding box annotations across 10 classes, ensuring reliable data for perception training. We provide detailed statistical analysis on the quality of our dataset and extensively benchmark existing V2X methods on it. Mixed Signals V2X Dataset is one of the highest quality, large-scale datasets publicly available for V2X perception research. Details on the website https://mixedsignalsdataset.cs.cornell.edu/.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024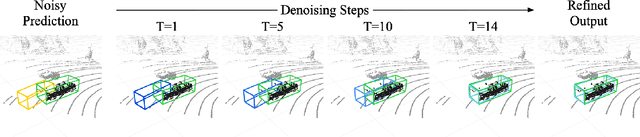
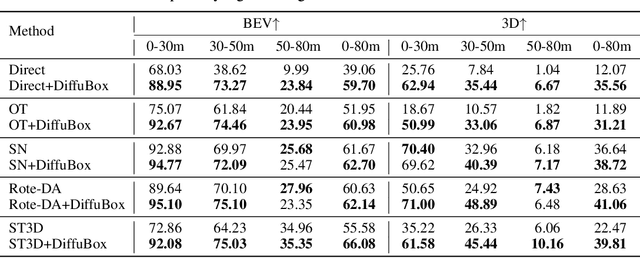
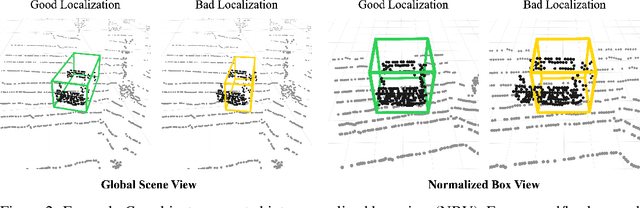
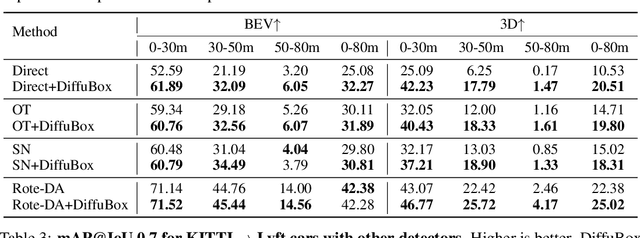
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Zero-shot Object-Level OOD Detection with Context-Aware Inpainting
Feb 07, 2024



Machine learning algorithms are increasingly provided as black-box cloud services or pre-trained models, without access to their training data. This motivates the problem of zero-shot out-of-distribution (OOD) detection. Concretely, we aim to detect OOD objects that do not belong to the classifier's label set but are erroneously classified as in-distribution (ID) objects. Our approach, RONIN, uses an off-the-shelf diffusion model to replace detected objects with inpainting. RONIN conditions the inpainting process with the predicted ID label, drawing the input object closer to the in-distribution domain. As a result, the reconstructed object is very close to the original in the ID cases and far in the OOD cases, allowing RONIN to effectively distinguish ID and OOD samples. Throughout extensive experiments, we demonstrate that RONIN achieves competitive results compared to previous approaches across several datasets, both in zero-shot and non-zero-shot settings.
Reward Finetuning for Faster and More Accurate Unsupervised Object Discovery
Nov 05, 2023



Recent advances in machine learning have shown that Reinforcement Learning from Human Feedback (RLHF) can improve machine learning models and align them with human preferences. Although very successful for Large Language Models (LLMs), these advancements have not had a comparable impact in research for autonomous vehicles -- where alignment with human expectations can be imperative. In this paper, we propose to adapt similar RL-based methods to unsupervised object discovery, i.e. learning to detect objects from LiDAR points without any training labels. Instead of labels, we use simple heuristics to mimic human feedback. More explicitly, we combine multiple heuristics into a simple reward function that positively correlates its score with bounding box accuracy, i.e., boxes containing objects are scored higher than those without. We start from the detector's own predictions to explore the space and reinforce boxes with high rewards through gradient updates. Empirically, we demonstrate that our approach is not only more accurate, but also orders of magnitudes faster to train compared to prior works on object discovery.
Correction with Backtracking Reduces Hallucination in Summarization
Oct 31, 2023



Abstractive summarization aims at generating natural language summaries of a source document that are succinct while preserving the important elements. Despite recent advances, neural text summarization models are known to be susceptible to hallucinating (or more correctly confabulating), that is to produce summaries with details that are not grounded in the source document. In this paper, we introduce a simple yet efficient technique, CoBa, to reduce hallucination in abstractive summarization. The approach is based on two steps: hallucination detection and mitigation. We show that the former can be achieved through measuring simple statistics about conditional word probabilities and distance to context words. Further, we demonstrate that straight-forward backtracking is surprisingly effective at mitigation. We thoroughly evaluate the proposed method with prior art on three benchmark datasets for text summarization. The results show that CoBa is effective and efficient in reducing hallucination, and offers great adaptability and flexibility.