 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Structure Generation: From Educational Priors to Policy Optimization
Aug 18, 2025Cognitive structure is a student's subjective organization of an objective knowledge system, reflected in the psychological construction of concepts and their relations. However, cognitive structure assessment remains a long-standing challenge in student modeling and psychometrics, persisting as a foundational yet largely unassessable concept in educational practice. This paper introduces a novel framework, Cognitive Structure Generation (CSG), in which we first pretrain a Cognitive Structure Diffusion Probabilistic Model (CSDPM) to generate students' cognitive structures from educational priors, and then further optimize its generative process as a policy with hierarchical reward signals via reinforcement learning to align with genuine cognitive development levels during students' learning processes. Experimental results on four popular real-world education datasets show that cognitive structures generated by CSG offer more comprehensive and effective representations for student modeling, substantially improving performance on KT and CD tasks while enhancing interpretability.
Efficient Controllable Diffusion via Optimal Classifier Guidance
May 27, 2025The controllable generation of diffusion models aims to steer the model to generate samples that optimize some given objective functions. It is desirable for a variety of applications including image generation, molecule generation, and DNA/sequence generation. Reinforcement Learning (RL) based fine-tuning of the base model is a popular approach but it can overfit the reward function while requiring significant resources. We frame controllable generation as a problem of finding a distribution that optimizes a KL-regularized objective function. We present SLCD -- Supervised Learning based Controllable Diffusion, which iteratively generates online data and trains a small classifier to guide the generation of the diffusion model. Similar to the standard classifier-guided diffusion, SLCD's key computation primitive is classification and does not involve any complex concepts from RL or control. Via a reduction to no-regret online learning analysis, we show that under KL divergence, the output from SLCD provably converges to the optimal solution of the KL-regularized objective. Further, we empirically demonstrate that SLCD can generate high quality samples with nearly the same inference time as the base model in both image generation with continuous diffusion and biological sequence generation with discrete diffusion. Our code is available at https://github.com/Owen-Oertell/slcd
Value-Guided Search for Efficient Chain-of-Thought Reasoning
May 23, 2025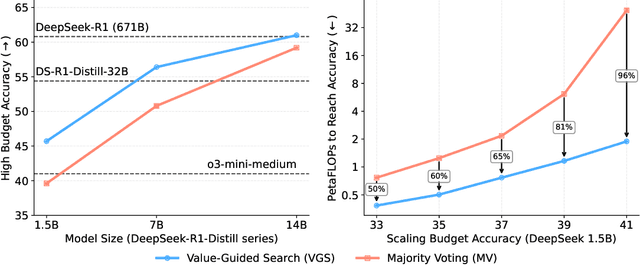
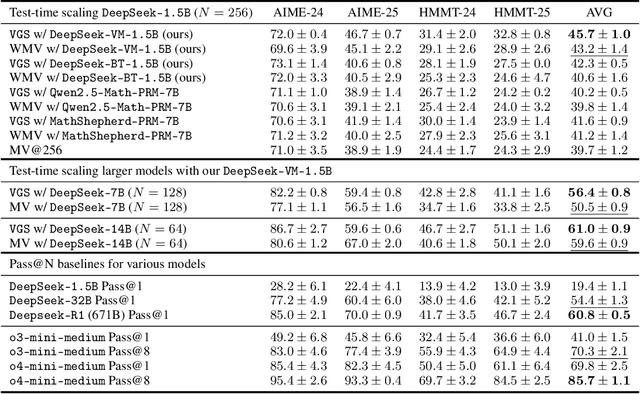
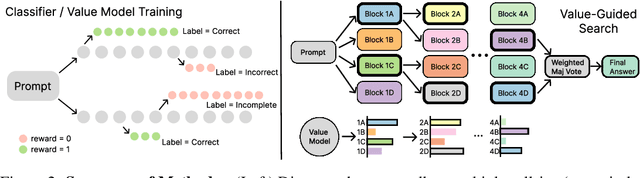
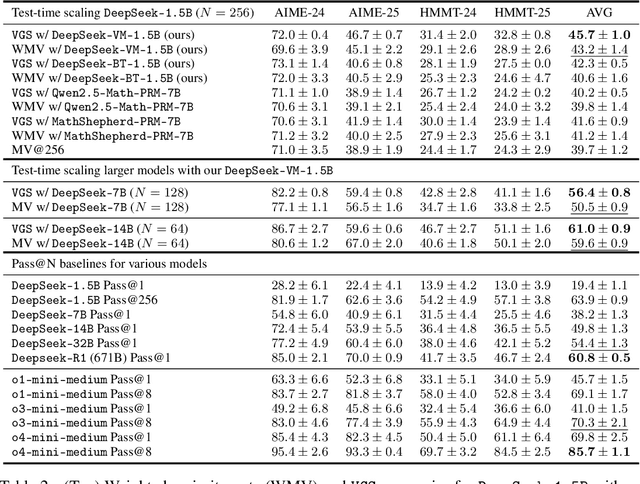
In this paper, we propose a simple and efficient method for value model training on long-context reasoning traces. Compared to existing process reward models (PRMs), our method does not require a fine-grained notion of "step," which is difficult to define for long-context reasoning models. By collecting a dataset of 2.5 million reasoning traces, we train a 1.5B token-level value model and apply it to DeepSeek models for improved performance with test-time compute scaling. We find that block-wise value-guided search (VGS) with a final weighted majority vote achieves better test-time scaling than standard methods such as majority voting or best-of-n. With an inference budget of 64 generations, VGS with DeepSeek-R1-Distill-1.5B achieves an average accuracy of 45.7% across four competition math benchmarks (AIME 2024 & 2025, HMMT Feb 2024 & 2025), reaching parity with o3-mini-medium. Moreover, VGS significantly reduces the inference FLOPs required to achieve the same performance of majority voting. Our dataset, model and codebase are open-sourced.
Pre-training Large Memory Language Models with Internal and External Knowledge
May 21, 2025Neural language models are black-boxes -- both linguistic patterns and factual knowledge are distributed across billions of opaque parameters. This entangled encoding makes it difficult to reliably inspect, verify, or update specific facts. We propose a new class of language models, Large Memory Language Models (LMLM) with a pre-training recipe that stores factual knowledge in both internal weights and an external database. Our approach strategically masks externally retrieved factual values from the training loss, thereby teaching the model to perform targeted lookups rather than relying on memorization in model weights. Our experiments demonstrate that LMLMs achieve competitive performance compared to significantly larger, knowledge-dense LLMs on standard benchmarks, while offering the advantages of explicit, editable, and verifiable knowledge bases. This work represents a fundamental shift in how language models interact with and manage factual knowledge.
INPROVF: Leveraging Large Language Models to Repair High-level Robot Controllers from Assumption Violations
Mar 17, 2025



This paper presents INPROVF, an automatic framework that combines large language models (LLMs) and formal methods to speed up the repair process of high-level robot controllers. Previous approaches based solely on formal methods are computationally expensive and cannot scale to large state spaces. In contrast, INPROVF uses LLMs to generate repair candidates, and formal methods to verify their correctness. To improve the quality of these candidates, our framework first translates the symbolic representations of the environment and controllers into natural language descriptions. If a candidate fails the verification, INPROVF provides feedback on potential unsafe behaviors or unsatisfied tasks, and iteratively prompts LLMs to generate improved solutions. We demonstrate the effectiveness of INPROVF through 12 violations with various workspaces, tasks, and state space sizes.
$Q\sharp$: Provably Optimal Distributional RL for LLM Post-Training
Feb 27, 2025



Reinforcement learning (RL) post-training is crucial for LLM alignment and reasoning, but existing policy-based methods, such as PPO and DPO, can fall short of fixing shortcuts inherited from pre-training. In this work, we introduce $Q\sharp$, a value-based algorithm for KL-regularized RL that guides the reference policy using the optimal regularized $Q$ function. We propose to learn the optimal $Q$ function using distributional RL on an aggregated online dataset. Unlike prior value-based baselines that guide the model using unregularized $Q$-values, our method is theoretically principled and provably learns the optimal policy for the KL-regularized RL problem. Empirically, $Q\sharp$ outperforms prior baselines in math reasoning benchmarks while maintaining a smaller KL divergence to the reference policy. Theoretically, we establish a reduction from KL-regularized RL to no-regret online learning, providing the first bounds for deterministic MDPs under only realizability. Thanks to distributional RL, our bounds are also variance-dependent and converge faster when the reference policy has small variance. In sum, our results highlight $Q\sharp$ as an effective approach for post-training LLMs, offering both improved performance and theoretical guarantees. The code can be found at https://github.com/jinpz/q_sharp.
Rethinking LLM Unlearning Objectives: A Gradient Perspective and Go Beyond
Feb 26, 2025



Large language models (LLMs) should undergo rigorous audits to identify potential risks, such as copyright and privacy infringements. Once these risks emerge, timely updates are crucial to remove undesirable responses, ensuring legal and safe model usage. It has spurred recent research into LLM unlearning, focusing on erasing targeted undesirable knowledge without compromising the integrity of other, non-targeted responses. Existing studies have introduced various unlearning objectives to pursue LLM unlearning without necessitating complete retraining. However, each of these objectives has unique properties, and no unified framework is currently available to comprehend them thoroughly. To fill the gap, we propose a toolkit of the gradient effect (G-effect), quantifying the impacts of unlearning objectives on model performance from a gradient perspective. A notable advantage is its broad ability to detail the unlearning impacts from various aspects across instances, updating steps, and LLM layers. Accordingly, the G-effect offers new insights into identifying drawbacks of existing unlearning objectives, further motivating us to explore a series of new solutions for their mitigation and improvements. Finally, we outline promising directions that merit further studies, aiming at contributing to the community to advance this important field.
Enhancing Cognitive Diagnosis by Modeling Learner Cognitive Structure State
Dec 27, 2024Cognitive diagnosis represents a fundamental research area within intelligent education, with the objective of measuring the cognitive status of individuals. Theoretically, an individual's cognitive state is essentially equivalent to their cognitive structure state. Cognitive structure state comprises two key components: knowledge state (KS) and knowledge structure state (KUS). The knowledge state reflects the learner's mastery of individual concepts, a widely studied focus within cognitive diagnosis. In contrast, the knowledge structure state-representing the learner's understanding of the relationships between concepts-remains inadequately modeled. A learner's cognitive structure is essential for promoting meaningful learning and shaping academic performance. Although various methods have been proposed, most focus on assessing KS and fail to assess KUS. To bridge this gap, we propose an innovative and effective framework-CSCD (Cognitive Structure State-based Cognitive Diagnosis)-which introduces a novel framework to modeling learners' cognitive structures in diagnostic assessments, thereby offering new insights into cognitive structure modeling. Specifically, we employ an edge-feature-based graph attention network to represent the learner's cognitive structure state, effectively integrating KS and KUS. Extensive experiments conducted on real datasets demonstrate the superior performance of this framework in terms of diagnostic accuracy and interpretability.
Towards More Robust Retrieval-Augmented Generation: Evaluating RAG Under Adversarial Poisoning Attacks
Dec 21, 2024Retrieval-Augmented Generation (RAG) systems have emerged as a promising solution to mitigate LLM hallucinations and enhance their performance in knowledge-intensive domains. However, these systems are vulnerable to adversarial poisoning attacks, where malicious passages injected into retrieval databases can mislead the model into generating factually incorrect outputs. In this paper, we investigate both the retrieval and the generation components of RAG systems to understand how to enhance their robustness against such attacks. From the retrieval perspective, we analyze why and how the adversarial contexts are retrieved and assess how the quality of the retrieved passages impacts downstream generation. From a generation perspective, we evaluate whether LLMs' advanced critical thinking and internal knowledge capabilities can be leveraged to mitigate the impact of adversarial contexts, i.e., using skeptical prompting as a self-defense mechanism. Our experiments and findings provide actionable insights into designing safer and more resilient retrieval-augmented frameworks, paving the way for their reliable deployment in real-world applications.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.