 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Rewards Can Self-Train Dialogue Agents
Sep 06, 2024



Recent advancements in state-of-the-art (SOTA) Large Language Model (LLM) agents, especially in multi-turn dialogue tasks, have been primarily driven by supervised fine-tuning and high-quality human feedback. However, as base LLM models continue to improve, acquiring meaningful human feedback has become increasingly challenging and costly. In certain domains, base LLM agents may eventually exceed human capabilities, making traditional feedback-driven methods impractical. In this paper, we introduce a novel self-improvement paradigm that empowers LLM agents to autonomously enhance their performance without external human feedback. Our method, Juxtaposed Outcomes for Simulation Harvesting (JOSH), is a self-alignment algorithm that leverages a sparse reward simulation environment to extract ideal behaviors and further train the LLM on its own outputs. We present ToolWOZ, a sparse reward tool-calling simulation environment derived from MultiWOZ. We demonstrate that models trained with JOSH, both small and frontier, significantly improve tool-based interactions while preserving general model capabilities across diverse benchmarks. Our code and data are publicly available on GitHub.
Multi-Step Dialogue Workflow Action Prediction
Nov 16, 2023



In task-oriented dialogue, a system often needs to follow a sequence of actions, called a workflow, that complies with a set of guidelines in order to complete a task. In this paper, we propose the novel problem of multi-step workflow action prediction, in which the system predicts multiple future workflow actions. Accurate prediction of multiple steps allows for multi-turn automation, which can free up time to focus on more complex tasks. We propose three modeling approaches that are simple to implement yet lead to more action automation: 1) fine-tuning on a training dataset, 2) few-shot in-context learning leveraging retrieval and large language model prompting, and 3) zero-shot graph traversal, which aggregates historical action sequences into a graph for prediction. We show that multi-step action prediction produces features that improve accuracy on downstream dialogue tasks like predicting task success, and can increase automation of steps by 20% without requiring as much feedback from a human overseeing the system.
HeaP: Hierarchical Policies for Web Actions using LLMs
Oct 05, 2023



Large language models (LLMs) have demonstrated remarkable capabilities in performing a range of instruction following tasks in few and zero-shot settings. However, teaching LLMs to perform tasks on the web presents fundamental challenges -- combinatorially large open-world tasks and variations across web interfaces. We tackle these challenges by leveraging LLMs to decompose web tasks into a collection of sub-tasks, each of which can be solved by a low-level, closed-loop policy. These policies constitute a shared grammar across tasks, i.e., new web tasks can be expressed as a composition of these policies. We propose a novel framework, Hierarchical Policies for Web Actions using LLMs (HeaP), that learns a set of hierarchical LLM prompts from demonstrations for planning high-level tasks and executing them via a sequence of low-level policies. We evaluate HeaP against a range of baselines on a suite of web tasks, including MiniWoB++, WebArena, a mock airline CRM, as well as live website interactions, and show that it is able to outperform prior works using orders of magnitude less data.
On the Effectiveness of Offline RL for Dialogue Response Generation
Jul 23, 2023



A common training technique for language models is teacher forcing (TF). TF attempts to match human language exactly, even though identical meanings can be expressed in different ways. This motivates use of sequence-level objectives for dialogue response generation. In this paper, we study the efficacy of various offline reinforcement learning (RL) methods to maximize such objectives. We present a comprehensive evaluation across multiple datasets, models, and metrics. Offline RL shows a clear performance improvement over teacher forcing while not inducing training instability or sacrificing practical training budgets.
Long-term Control for Dialogue Generation: Methods and Evaluation
May 15, 2022
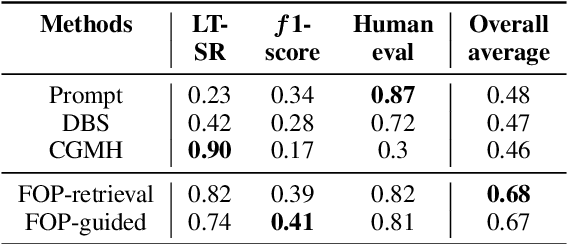
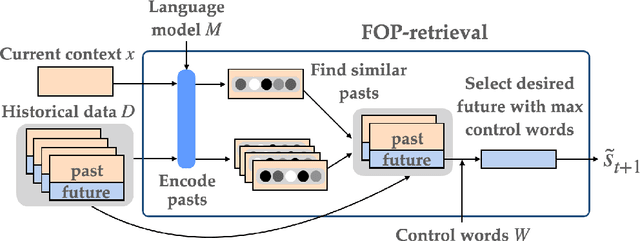
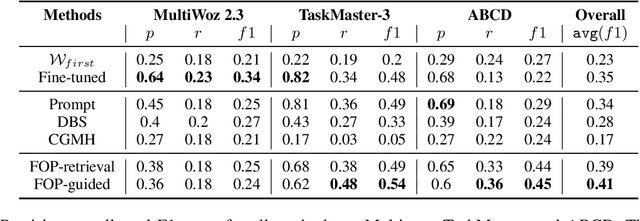
Current approaches for controlling dialogue response generation are primarily focused on high-level attributes like style, sentiment, or topic. In this work, we focus on constrained long-term dialogue generation, which involves more fine-grained control and requires a given set of control words to appear in generated responses. This setting requires a model to not only consider the generation of these control words in the immediate context, but also produce utterances that will encourage the generation of the words at some time in the (possibly distant) future. We define the problem of constrained long-term control for dialogue generation, identify gaps in current methods for evaluation, and propose new metrics that better measure long-term control. We also propose a retrieval-augmented method that improves performance of long-term controlled generation via logit modification techniques. We show through experiments on three task-oriented dialogue datasets that our metrics better assess dialogue control relative to current alternatives and that our method outperforms state-of-the-art constrained generation baselines.
Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages
May 02, 2022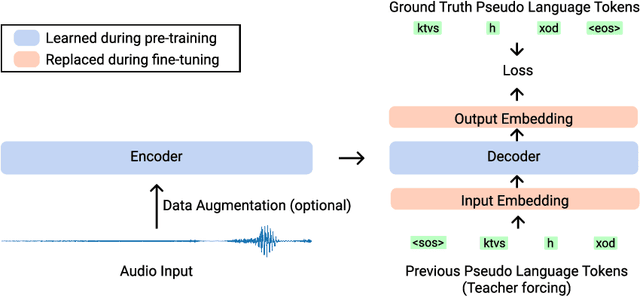

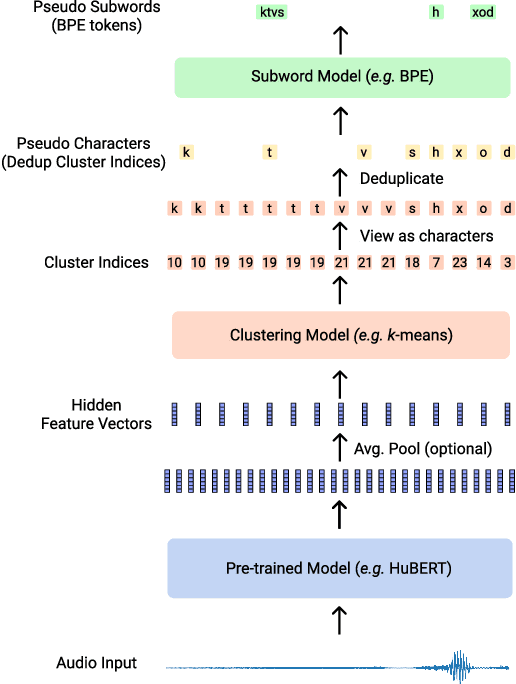
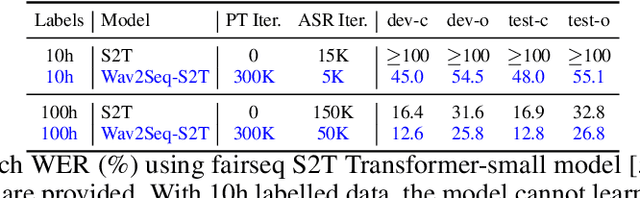
We introduce Wav2Seq, the first self-supervised approach to pre-train both parts of encoder-decoder models for speech data. We induce a pseudo language as a compact discrete representation, and formulate a self-supervised pseudo speech recognition task -- transcribing audio inputs into pseudo subword sequences. This process stands on its own, or can be applied as low-cost second-stage pre-training. We experiment with automatic speech recognition (ASR), spoken named entity recognition, and speech-to-text translation. We set new state-of-the-art results for end-to-end spoken named entity recognition, and show consistent improvements on 20 language pairs for speech-to-text translation, even when competing methods use additional text data for training. Finally, on ASR, our approach enables encoder-decoder methods to benefit from pre-training for all parts of the network, and shows comparable performance to highly optimized recent methods.
Focus Attention: Promoting Faithfulness and Diversity in Summarization
May 25, 2021

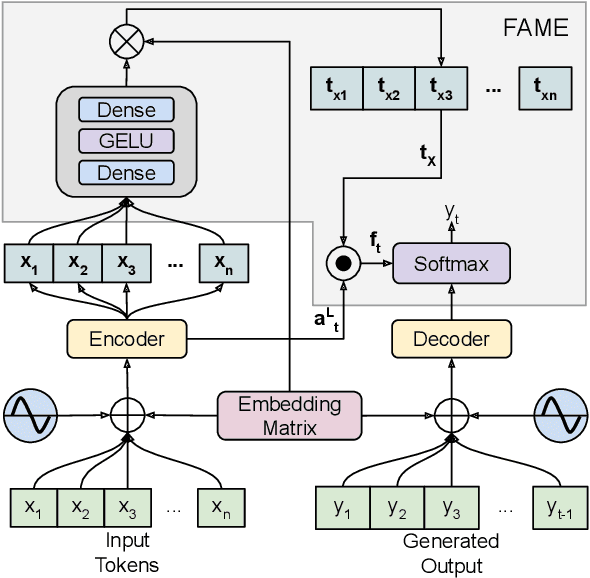
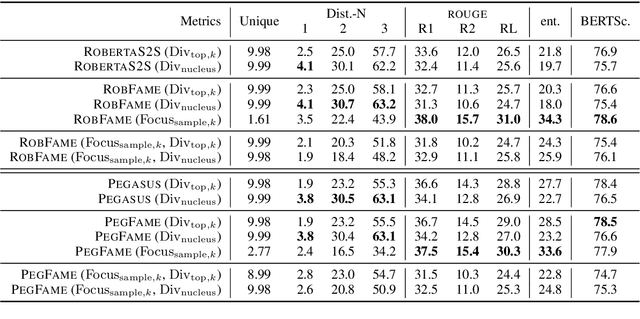
Professional summaries are written with document-level information, such as the theme of the document, in mind. This is in contrast with most seq2seq decoders which simultaneously learn to focus on salient content, while deciding what to generate, at each decoding step. With the motivation to narrow this gap, we introduce Focus Attention Mechanism, a simple yet effective method to encourage decoders to proactively generate tokens that are similar or topical to the input document. Further, we propose a Focus Sampling method to enable generation of diverse summaries, an area currently understudied in summarization. When evaluated on the BBC extreme summarization task, two state-of-the-art models augmented with Focus Attention generate summaries that are closer to the target and more faithful to their input documents, outperforming their vanilla counterparts on \rouge and multiple faithfulness measures. We also empirically demonstrate that Focus Sampling is more effective in generating diverse and faithful summaries than top-$k$ or nucleus sampling-based decoding methods.
Planning with Entity Chains for Abstractive Summarization
Apr 15, 2021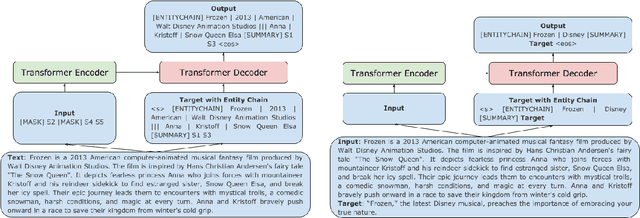

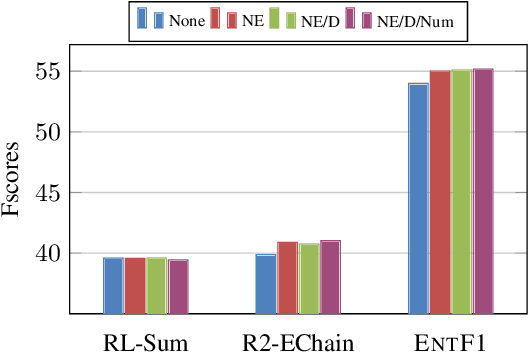
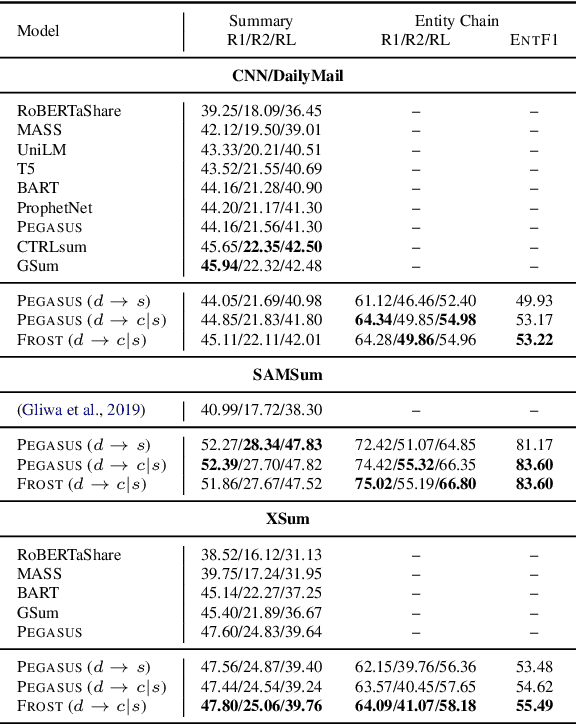
Pre-trained transformer-based sequence-to-sequence models have become the go-to solution for many text generation tasks, including summarization. However, the results produced by these models tend to contain significant issues such as hallucinations and irrelevant passages. One solution to mitigate these problems is to incorporate better content planning in neural summarization. We propose to use entity chains (i.e., chains of entities mentioned in the summary) to better plan and ground the generation of abstractive summaries. In particular, we augment the target by prepending it with its entity chain. We experimented with both pre-training and finetuning with this content planning objective. When evaluated on CNN/DailyMail, SAMSum and XSum, models trained with this objective improved on entity correctness and summary conciseness, and achieved state-of-the-art performance on ROUGE for SAMSum and XSum.
Stepwise Extractive Summarization and Planning with Structured Transformers
Oct 06, 2020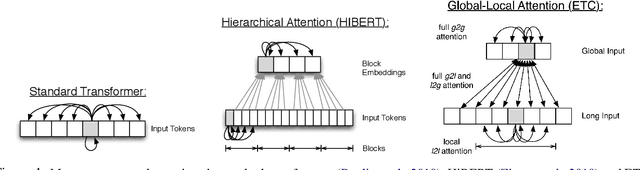
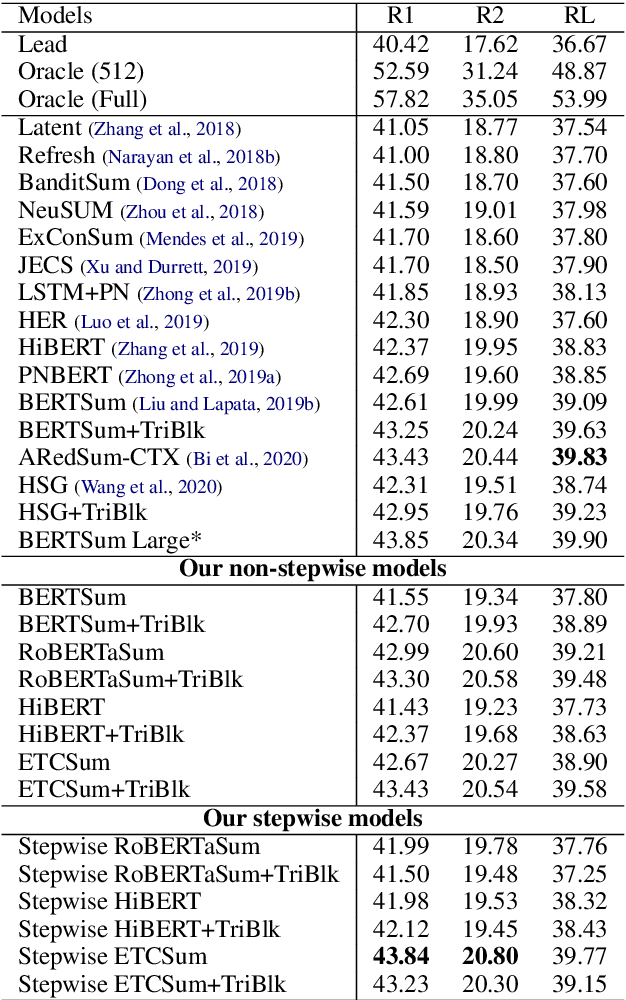
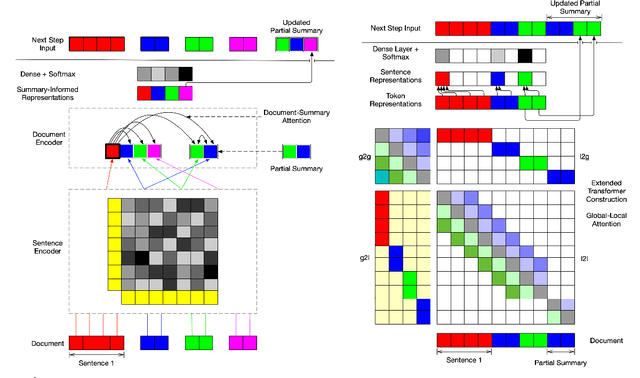
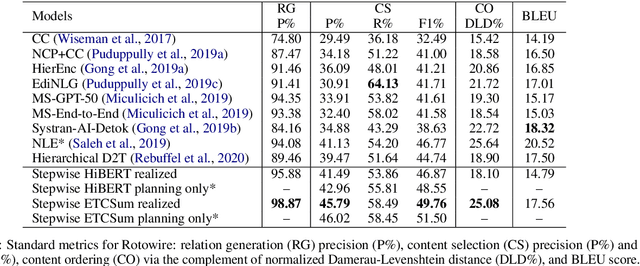
We propose encoder-centric stepwise models for extractive summarization using structured transformers -- HiBERT and Extended Transformers. We enable stepwise summarization by injecting the previously generated summary into the structured transformer as an auxiliary sub-structure. Our models are not only efficient in modeling the structure of long inputs, but they also do not rely on task-specific redundancy-aware modeling, making them a general purpose extractive content planner for different tasks. When evaluated on CNN/DailyMail extractive summarization, stepwise models achieve state-of-the-art performance in terms of Rouge without any redundancy aware modeling or sentence filtering. This also holds true for Rotowire table-to-text generation, where our models surpass previously reported metrics for content selection, planning and ordering, highlighting the strength of stepwise modeling. Amongst the two structured transformers we test, stepwise Extended Transformers provides the best performance across both datasets and sets a new standard for these challenges.
RRF102: Meeting the TREC-COVID Challenge with a 100+ Runs Ensemble
Oct 01, 2020
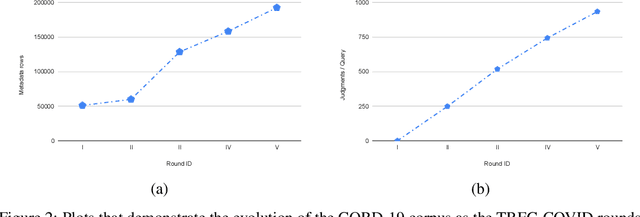
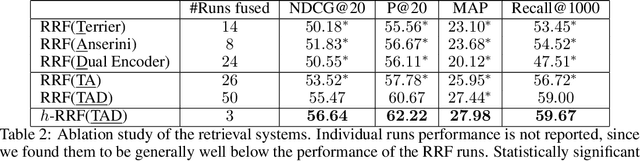
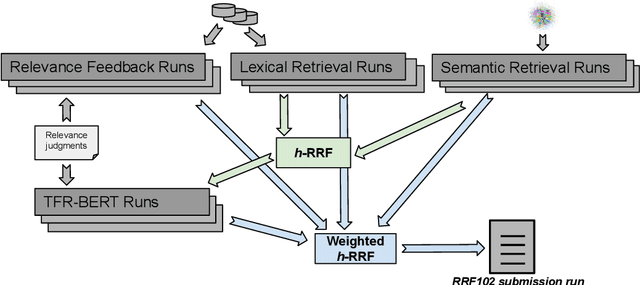
In this paper, we report the results of our participation in the TREC-COVID challenge. To meet the challenge of building a search engine for rapidly evolving biomedical collection, we propose a simple yet effective weighted hierarchical rank fusion approach, that ensembles together 102 runs from (a) lexical and semantic retrieval systems, (b) pre-trained and fine-tuned BERT rankers, and (c) relevance feedback runs. Our ablation studies demonstrate the contributions of each of these systems to the overall ensemble. The submitted ensemble runs achieved state-of-the-art performance in rounds 4 and 5 of the TREC-COVID challenge.