 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Training & Inference for Forecasting: Linking Winner-Take-All back to GMMs
Jun 24, 2026Trajectory forecasting for autonomous driving has advanced rapidly, yet representative models often produce uninformative posteriors over forecast modes, causing problems for mode pruning. We trace this to a modeling-training mismatch: forecasters are typically modeled as conditional Gaussian mixture models (GMMs) but trained with a winner-take-all (WTA) loss that assigns each sample to its nearest mode. We argue that this K-means-like hard assignment (one-hot), while preventing mode collapse, is the source of uninformative mode probabilities: it over-segments the trajectory space, ignores relatedness among nearby modes, and yields assignment instability under small perturbations. Guided by this lens, we introduce two post-hoc treatments: (1) test-time posterior-weighted merging that aggregates nearby candidate trajectories; and (2) a one-step expectation-maximization (EM) update that replaces hard labels with soft responsibilities, sharing probability mass across neighboring modes. Across several WTA-trained architectures, these lightweight steps produce more informative, faithfully ranked mode posteriors and strengthen final forecasts on popular displacement metrics -- without retraining. Our analysis unifies recent design choices through a GMM-vs-K-means perspective and offers principled, practical corrections that better align training objectives with inference.
Bridging Structure and Language: Graph-Based Visual Reasoning for Autonomous Road Understanding
May 20, 2026Structured road understanding of lane geometry, topology, and traffic element relationships is foundational to safe autonomous driving. While vision-language models (VLMs) offer promising semantic flexibility, they lack the geometric and relational grounding required for precise road reasoning. Conversely, traditional modular systems, e.g., HD maps and topological road graphs, provide structural precision but remain semantically rigid. To bridge this gap, we introduce the Combined Road Substrate (CRS), a graph-grounded framework that makes geometric road structure and open-vocabulary semantics jointly executable in a single representation. CRS enables the automatic generation of compositionally complex and linguistically varied question-answer pairs via recursive graph queries, augmented with a "grounding for free" mechanism that ensures logical traceability to specific map elements, and procedurally extracted chain-of-thought supervision traces. We demonstrate that state-of-the-art VLMs - including large, closed-source models - struggle significantly with structured road reasoning, yet training a small 2- or 4-billion-parameter model with as few as 20 to 80 CRS-enriched scenes yields stable gains in compositional reasoning tasks of varying depth. Analysis of model behavior via verifiable reasoning traces reveals a systematic shift in failure modes: whereas baseline models fail at relational scene understanding, CRS-trained models reduce failures to attribute recognition, suggesting that the primary bottleneck in road understanding is not model scale, but the absence of structured supervision.
When the City Teaches the Car: Label-Free 3D Perception from Infrastructure
Mar 17, 2026Building robust 3D perception for self-driving still relies heavily on large-scale data collection and manual annotation, yet this paradigm becomes impractical as deployment expands across diverse cities and regions. Meanwhile, modern cities are increasingly instrumented with roadside units (RSUs), static sensors deployed along roads and at intersections to monitor traffic. This raises a natural question: can the city itself help train the vehicle? We propose infrastructure-taught, label-free 3D perception, a paradigm in which RSUs act as stationary, unsupervised teachers for ego vehicles. Leveraging their fixed viewpoints and repeated observations, RSUs learn local 3D detectors from unlabeled data and broadcast predictions to passing vehicles, which are aggregated as pseudo-label supervision for training a standalone ego detector. The resulting model requires no infrastructure or communication at test time. We instantiate this idea as a fully label-free three-stage pipeline and conduct a concept-and-feasibility study in a CARLA-based multi-agent environment. With CenterPoint, our pipeline achieves 82.3% AP for detecting vehicles, compared to a fully supervised ego upper bound of 94.4%. We further systematically analyze each stage, evaluate its scalability, and demonstrate complementarity with existing ego-centric label-free methods. Together, these results suggest that city infrastructure itself can potentially provide a scalable supervisory signal for autonomous vehicles, positioning infrastructure-taught learning as a promising orthogonal paradigm for reducing annotation cost in 3D perception.
On the Feasibility and Opportunity of Autoregressive 3D Object Detection
Mar 09, 2026LiDAR-based 3D object detectors typically rely on proposal heads with hand-crafted components like anchor assignment and non-maximum suppression (NMS), complicating training and limiting extensibility. We present AutoReg3D, an autoregressive 3D detector that casts detection as sequence generation. Given point-cloud features, AutoReg3D emits objects in a range-causal (near-to-far) order and encodes each object as a short, discrete-token sequence consisting of its center, size, orientation, velocity, and class. This near-to-far ordering mirrors LiDAR geometry--near objects occlude far ones but not vice versa--enabling straightforward teacher forcing during training and autoregressive decoding at test time. AutoReg3D is compatible across diverse point-cloud or backbones and attains competitive nuScenes performance without anchors or NMS. Beyond parity, the sequential formulation unlocks language-model advances for 3D perception, including GRPO-style reinforcement learning for task-aligned objectives. These results position autoregressive decoding as a viable, flexible alternative for LiDAR-based detection and open a path to importing modern sequence-modeling tools into 3D perception.
Benchmark Datasets for Lead-Lag Forecasting on Social Platforms
Nov 05, 2025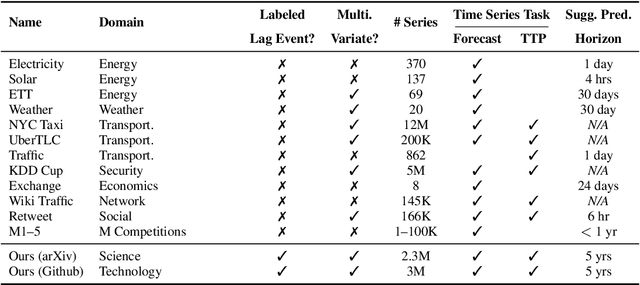


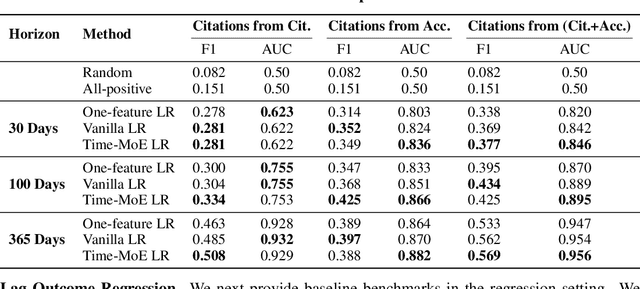
Social and collaborative platforms emit multivariate time-series traces in which early interactions-such as views, likes, or downloads-are followed, sometimes months or years later, by higher impact like citations, sales, or reviews. We formalize this setting as Lead-Lag Forecasting (LLF): given an early usage channel (the lead), predict a correlated but temporally shifted outcome channel (the lag). Despite the ubiquity of such patterns, LLF has not been treated as a unified forecasting problem within the time-series community, largely due to the absence of standardized datasets. To anchor research in LLF, here we present two high-volume benchmark datasets-arXiv (accesses -> citations of 2.3M papers) and GitHub (pushes/stars -> forks of 3M repositories)-and outline additional domains with analogous lead-lag dynamics, including Wikipedia (page views -> edits), Spotify (streams -> concert attendance), e-commerce (click-throughs -> purchases), and LinkedIn profile (views -> messages). Our datasets provide ideal testbeds for lead-lag forecasting, by capturing long-horizon dynamics across years, spanning the full spectrum of outcomes, and avoiding survivorship bias in sampling. We documented all technical details of data curation and cleaning, verified the presence of lead-lag dynamics through statistical and classification tests, and benchmarked parametric and non-parametric baselines for regression. Our study establishes LLF as a novel forecasting paradigm and lays an empirical foundation for its systematic exploration in social and usage data. Our data portal with downloads and documentation is available at https://lead-lag-forecasting.github.io/.
Mixed Signals: A Diverse Point Cloud Dataset for Heterogeneous LiDAR V2X Collaboration
Feb 19, 2025Vehicle-to-everything (V2X) collaborative perception has emerged as a promising solution to address the limitations of single-vehicle perception systems. However, existing V2X datasets are limited in scope, diversity, and quality. To address these gaps, we present Mixed Signals, a comprehensive V2X dataset featuring 45.1k point clouds and 240.6k bounding boxes collected from three connected autonomous vehicles (CAVs) equipped with two different types of LiDAR sensors, plus a roadside unit with dual LiDARs. Our dataset provides precisely aligned point clouds and bounding box annotations across 10 classes, ensuring reliable data for perception training. We provide detailed statistical analysis on the quality of our dataset and extensively benchmark existing V2X methods on it. Mixed Signals V2X Dataset is one of the highest quality, large-scale datasets publicly available for V2X perception research. Details on the website https://mixedsignalsdataset.cs.cornell.edu/.
Orchestrating LLMs with Different Personalizations
Jul 04, 2024



This paper presents a novel approach to aligning large language models (LLMs) with individual human preferences, sometimes referred to as Reinforcement Learning from \textit{Personalized} Human Feedback (RLPHF). Given stated preferences along multiple dimensions, such as helpfulness, conciseness, or humor, the goal is to create an LLM without re-training that best adheres to this specification. Starting from specialized expert LLMs, each trained for one such particular preference dimension, we propose a black-box method that merges their outputs on a per-token level. We train a lightweight Preference Control Model (PCM) that dynamically translates the preference description and current context into next-token prediction weights. By combining the expert models' outputs at the token level, our approach dynamically generates text that optimizes the given preference. Empirical tests show that our method matches or surpasses existing preference merging techniques, providing a scalable, efficient alternative to fine-tuning LLMs for individual personalization.
DiffuBox: Refining 3D Object Detection with Point Diffusion
May 25, 2024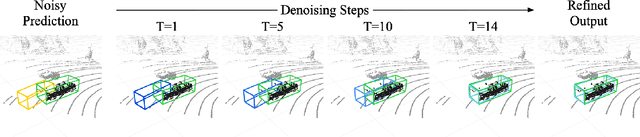
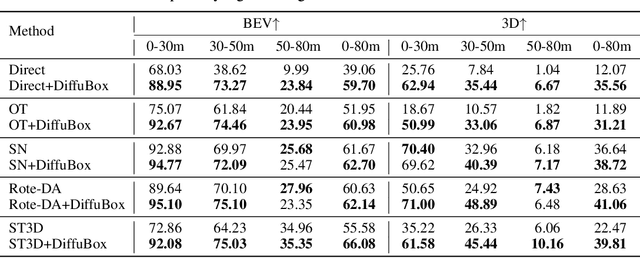
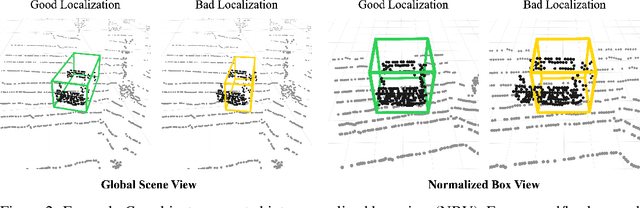
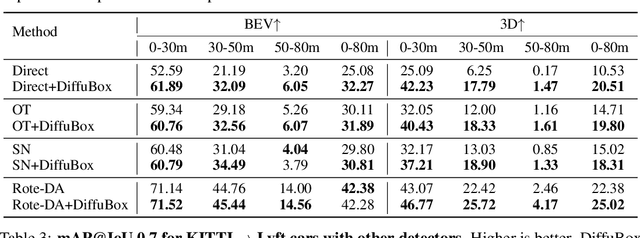
Ensuring robust 3D object detection and localization is crucial for many applications in robotics and autonomous driving. Recent models, however, face difficulties in maintaining high performance when applied to domains with differing sensor setups or geographic locations, often resulting in poor localization accuracy due to domain shift. To overcome this challenge, we introduce a novel diffusion-based box refinement approach. This method employs a domain-agnostic diffusion model, conditioned on the LiDAR points surrounding a coarse bounding box, to simultaneously refine the box's location, size, and orientation. We evaluate this approach under various domain adaptation settings, and our results reveal significant improvements across different datasets, object classes and detectors.
Better Monocular 3D Detectors with LiDAR from the Past
Apr 09, 2024



Accurate 3D object detection is crucial to autonomous driving. Though LiDAR-based detectors have achieved impressive performance, the high cost of LiDAR sensors precludes their widespread adoption in affordable vehicles. Camera-based detectors are cheaper alternatives but often suffer inferior performance compared to their LiDAR-based counterparts due to inherent depth ambiguities in images. In this work, we seek to improve monocular 3D detectors by leveraging unlabeled historical LiDAR data. Specifically, at inference time, we assume that the camera-based detectors have access to multiple unlabeled LiDAR scans from past traversals at locations of interest (potentially from other high-end vehicles equipped with LiDAR sensors). Under this setup, we proposed a novel, simple, and end-to-end trainable framework, termed AsyncDepth, to effectively extract relevant features from asynchronous LiDAR traversals of the same location for monocular 3D detectors. We show consistent and significant performance gain (up to 9 AP) across multiple state-of-the-art models and datasets with a negligible additional latency of 9.66 ms and a small storage cost.
Denoising Vision Transformers
Jan 05, 2024



We delve into a nuanced but significant challenge inherent to Vision Transformers (ViTs): feature maps of these models exhibit grid-like artifacts, which detrimentally hurt the performance of ViTs in downstream tasks. Our investigations trace this fundamental issue down to the positional embeddings at the input stage. To address this, we propose a novel noise model, which is universally applicable to all ViTs. Specifically, the noise model dissects ViT outputs into three components: a semantics term free from noise artifacts and two artifact-related terms that are conditioned on pixel locations. Such a decomposition is achieved by enforcing cross-view feature consistency with neural fields in a per-image basis. This per-image optimization process extracts artifact-free features from raw ViT outputs, providing clean features for offline applications. Expanding the scope of our solution to support online functionality, we introduce a learnable denoiser to predict artifact-free features directly from unprocessed ViT outputs, which shows remarkable generalization capabilities to novel data without the need for per-image optimization. Our two-stage approach, termed Denoising Vision Transformers (DVT), does not require re-training existing pre-trained ViTs and is immediately applicable to any Transformer-based architecture. We evaluate our method on a variety of representative ViTs (DINO, MAE, DeiT-III, EVA02, CLIP, DINOv2, DINOv2-reg). Extensive evaluations demonstrate that our DVT consistently and significantly improves existing state-of-the-art general-purpose models in semantic and geometric tasks across multiple datasets (e.g., +3.84 mIoU). We hope our study will encourage a re-evaluation of ViT design, especially regarding the naive use of positional embeddings.