 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIRECT: When and Where Should You Allocate Test-Time Compute in Embodied Planners?
Jun 10, 2026Vision-Language Models (VLMs) are increasingly deployed as high-level planners for embodied agents, with an emerging strategy of scaling test-time compute to improve capability. However, we observe that doing so increases latency, token usage, and FLOPs while yielding uneven, often diminishing gains in downstream success, limiting where embodied agents can be deployed. We argue that choosing when and where to spend test-time compute is central to bringing frontier performance to the real world. We introduce DIRECT, a routing framework that uses multimodal scene context to allocate compute per prompt, improving the success--cost Pareto frontier over fixed model selection. Across three dominant scaling axes, namely chain-of-thought depth, model size, and memory history, our experiments on VLABench and RoboMME show that test-time compute is not a uniform lever: different axes yield qualitatively distinct capability gains. We validate these insights on a physical Franka arm in a DROID setup spanning zero-shot manipulation and long-horizon chaining, where our router matches or exceeds a stronger model's success rate at up to 65% lower average latency. Ultimately, our results show that naively scaling test-time compute is wasteful, and that DIRECT can provide frontier-level embodied planning in robotic systems at a fraction of the cost. Project page can be found at jadee-dao.github.io/direct/.
Self-Supervised Bootstrapping of Action-Predictive Embodied Reasoning
Feb 09, 2026Embodied Chain-of-Thought (CoT) reasoning has significantly enhanced Vision-Language-Action (VLA) models, yet current methods rely on rigid templates to specify reasoning primitives (e.g., objects in the scene, high-level plans, structural affordances). These templates can force policies to process irrelevant information that distracts from critical action-prediction signals. This creates a bottleneck: without successful policies, we cannot verify reasoning quality; without quality reasoning, we cannot build robust policies. We introduce R&B-EnCoRe, which enables models to bootstrap embodied reasoning from internet-scale knowledge through self-supervised refinement. By treating reasoning as a latent variable within importance-weighted variational inference, models can generate and distill a refined reasoning training dataset of embodiment-specific strategies without external rewards, verifiers, or human annotation. We validate R&B-EnCoRe across manipulation (Franka Panda in simulation, WidowX in hardware), legged navigation (bipedal, wheeled, bicycle, quadruped), and autonomous driving embodiments using various VLA architectures with 1B, 4B, 7B, and 30B parameters. Our approach achieves 28% gains in manipulation success, 101% improvement in navigation scores, and 21% reduction in collision-rate metric over models that indiscriminately reason about all available primitives. R&B-EnCoRe enables models to distill reasoning that is predictive of successful control, bypassing manual annotation engineering while grounding internet-scale knowledge in physical execution.
S4-Driver: Scalable Self-Supervised Driving Multimodal Large Language Modelwith Spatio-Temporal Visual Representation
May 30, 2025



The latest advancements in multi-modal large language models (MLLMs) have spurred a strong renewed interest in end-to-end motion planning approaches for autonomous driving. Many end-to-end approaches rely on human annotations to learn intermediate perception and prediction tasks, while purely self-supervised approaches--which directly learn from sensor inputs to generate planning trajectories without human annotations often underperform the state of the art. We observe a key gap in the input representation space: end-to-end approaches built on MLLMs are often pretrained with reasoning tasks in 2D image space rather than the native 3D space in which autonomous vehicles plan. To this end, we propose S4-Driver, a scalable self-supervised motion planning algorithm with spatio-temporal visual representation, based on the popular PaLI multimodal large language model. S4-Driver uses a novel sparse volume strategy to seamlessly transform the strong visual representation of MLLMs from perspective view to 3D space without the need to finetune the vision encoder. This representation aggregates multi-view and multi-frame visual inputs and enables better prediction of planning trajectories in 3D space. To validate our method, we run experiments on both nuScenes and Waymo Open Motion Dataset (with in-house camera data). Results show that S4-Driver performs favorably against existing supervised multi-task approaches while requiring no human annotations. It also demonstrates great scalability when pretrained on large volumes of unannotated driving logs.
Endangered Alert: A Field-Validated Self-Training Scheme for Detecting and Protecting Threatened Wildlife on Roads and Roadsides
Dec 16, 2024Traffic accidents are a global safety concern, resulting in numerous fatalities each year. A considerable number of these deaths are caused by animal-vehicle collisions (AVCs), which not only endanger human lives but also present serious risks to animal populations. This paper presents an innovative self-training methodology aimed at detecting rare animals, such as the cassowary in Australia, whose survival is threatened by road accidents. The proposed method addresses critical real-world challenges, including acquiring and labelling sensor data for rare animal species in resource-limited environments. It achieves this by leveraging cloud and edge computing, and automatic data labelling to improve the detection performance of the field-deployed model iteratively. Our approach introduces Label-Augmentation Non-Maximum Suppression (LA-NMS), which incorporates a vision-language model (VLM) to enable automated data labelling. During a five-month deployment, we confirmed the method's robustness and effectiveness, resulting in improved object detection accuracy and increased prediction confidence. The source code is available: https://github.com/acfr/CassDetect
Unsupervised Domain Adaptation for Self-Driving from Past Traversal Features
Sep 21, 2023The rapid development of 3D object detection systems for self-driving cars has significantly improved accuracy. However, these systems struggle to generalize across diverse driving environments, which can lead to safety-critical failures in detecting traffic participants. To address this, we propose a method that utilizes unlabeled repeated traversals of multiple locations to adapt object detectors to new driving environments. By incorporating statistics computed from repeated LiDAR scans, we guide the adaptation process effectively. Our approach enhances LiDAR-based detection models using spatial quantized historical features and introduces a lightweight regression head to leverage the statistics for feature regularization. Additionally, we leverage the statistics for a novel self-training process to stabilize the training. The framework is detector model-agnostic and experiments on real-world datasets demonstrate significant improvements, achieving up to a 20-point performance gain, especially in detecting pedestrians and distant objects. Code is available at https://github.com/zhangtravis/Hist-DA.
Ithaca365: Dataset and Driving Perception under Repeated and Challenging Weather Conditions
Aug 01, 2022
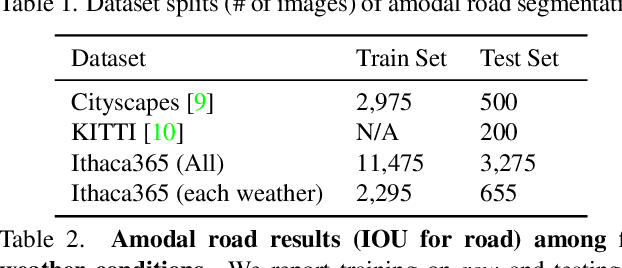
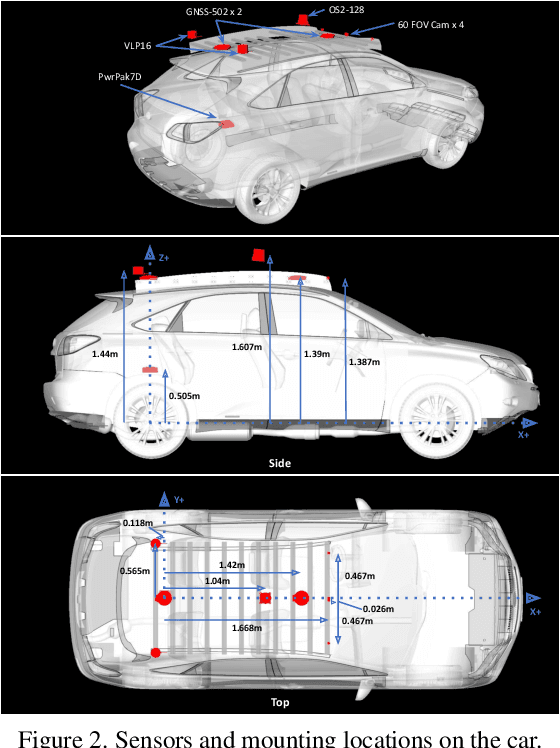
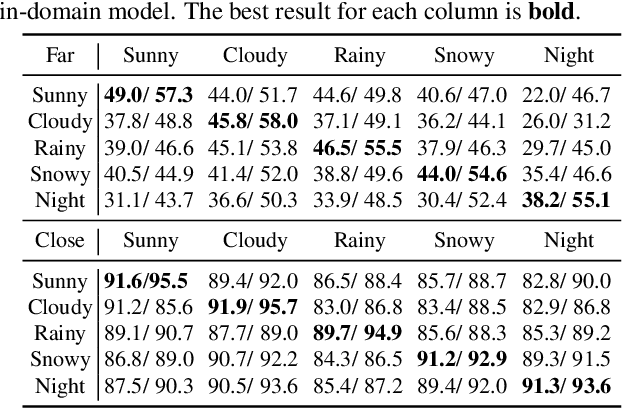
Advances in perception for self-driving cars have accelerated in recent years due to the availability of large-scale datasets, typically collected at specific locations and under nice weather conditions. Yet, to achieve the high safety requirement, these perceptual systems must operate robustly under a wide variety of weather conditions including snow and rain. In this paper, we present a new dataset to enable robust autonomous driving via a novel data collection process - data is repeatedly recorded along a 15 km route under diverse scene (urban, highway, rural, campus), weather (snow, rain, sun), time (day/night), and traffic conditions (pedestrians, cyclists and cars). The dataset includes images and point clouds from cameras and LiDAR sensors, along with high-precision GPS/INS to establish correspondence across routes. The dataset includes road and object annotations using amodal masks to capture partial occlusions and 3D bounding boxes. We demonstrate the uniqueness of this dataset by analyzing the performance of baselines in amodal segmentation of road and objects, depth estimation, and 3D object detection. The repeated routes opens new research directions in object discovery, continual learning, and anomaly detection. Link to Ithaca365: https://ithaca365.mae.cornell.edu/
Residual Aligned: Gradient Optimization for Non-Negative Image Synthesis
Feb 08, 2022



In this work, we address an important problem of optical see through (OST) augmented reality: non-negative image synthesis. Most of the image generation methods fail under this condition, since they assume full control over each pixel and cannot create darker pixels by adding light. In order to solve the non-negative image generation problem in AR image synthesis, prior works have attempted to utilize optical illusion to simulate human vision but fail to preserve lightness constancy well under situations such as high dynamic range. In our paper, we instead propose a method that is able to preserve lightness constancy at a local level, thus capturing high frequency details. Compared with existing work, our method shows strong performance in image-to-image translation tasks, particularly in scenarios such as large scale images, high resolution images, and high dynamic range image transfer.
Stay Positive: Non-Negative Image Synthesis for Augmented Reality
Feb 01, 2022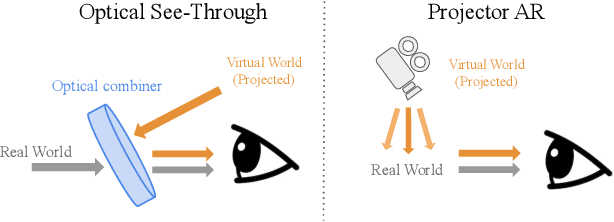
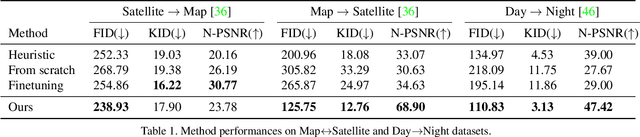
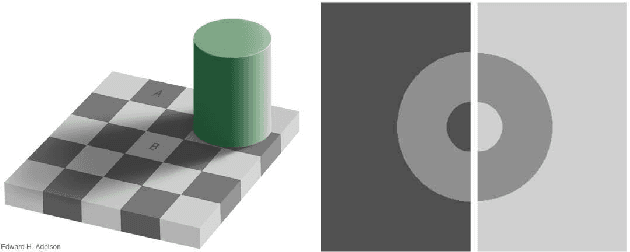
In applications such as optical see-through and projector augmented reality, producing images amounts to solving non-negative image generation, where one can only add light to an existing image. Most image generation methods, however, are ill-suited to this problem setting, as they make the assumption that one can assign arbitrary color to each pixel. In fact, naive application of existing methods fails even in simple domains such as MNIST digits, since one cannot create darker pixels by adding light. We know, however, that the human visual system can be fooled by optical illusions involving certain spatial configurations of brightness and contrast. Our key insight is that one can leverage this behavior to produce high quality images with negligible artifacts. For example, we can create the illusion of darker patches by brightening surrounding pixels. We propose a novel optimization procedure to produce images that satisfy both semantic and non-negativity constraints. Our approach can incorporate existing state-of-the-art methods, and exhibits strong performance in a variety of tasks including image-to-image translation and style transfer.
Safety-Oriented Pedestrian Motion and Scene Occupancy Forecasting
Jan 07, 2021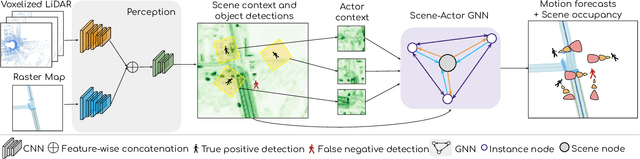
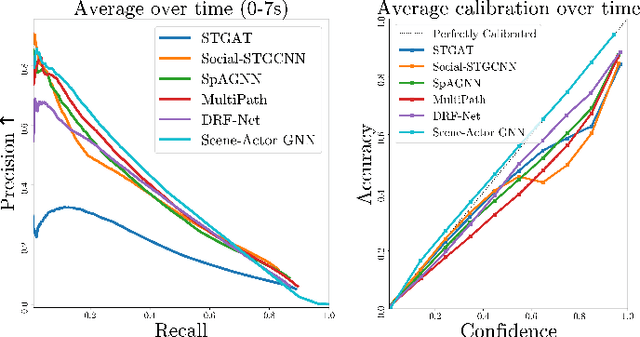
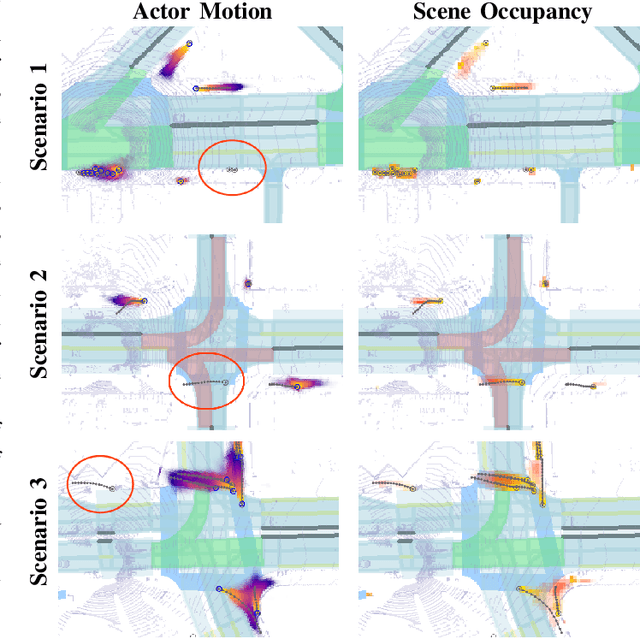
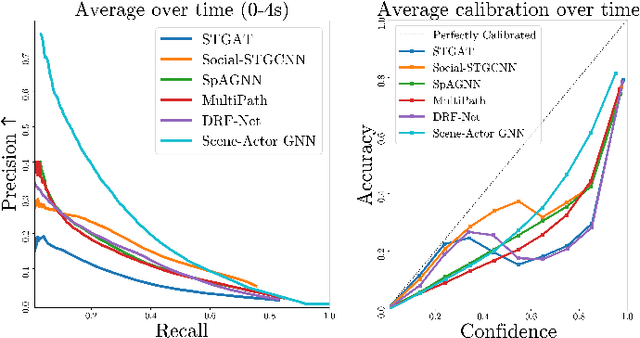
In this paper, we address the important problem in self-driving of forecasting multi-pedestrian motion and their shared scene occupancy map, critical for safe navigation. Our contributions are two-fold. First, we advocate for predicting both the individual motions as well as the scene occupancy map in order to effectively deal with missing detections caused by postprocessing, e.g., confidence thresholding and non-maximum suppression. Second, we propose a Scene-Actor Graph Neural Network (SA-GNN) which preserves the relative spatial information of pedestrians via 2D convolution, and captures the interactions among pedestrians within the same scene, including those that have not been detected, via message passing. On two large-scale real-world datasets, nuScenes and ATG4D, we showcase that our scene-occupancy predictions are more accurate and better calibrated than those from state-of-the-art motion forecasting methods, while also matching their performance in pedestrian motion forecasting metrics.
Implicit Latent Variable Model for Scene-Consistent Motion Forecasting
Jul 23, 2020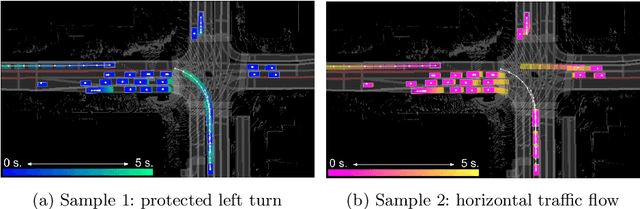
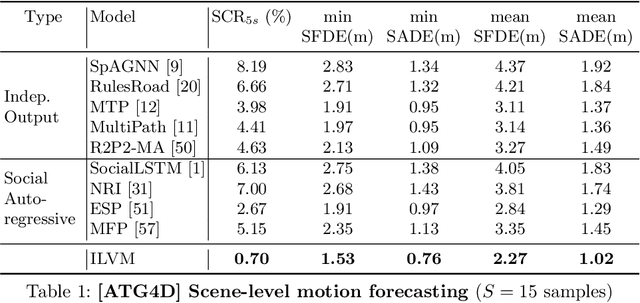

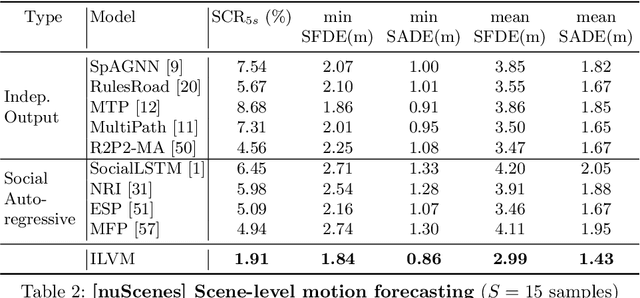
In order to plan a safe maneuver an autonomous vehicle must accurately perceive its environment, and understand the interactions among traffic participants. In this paper, we aim to learn scene-consistent motion forecasts of complex urban traffic directly from sensor data. In particular, we propose to characterize the joint distribution over future trajectories via an implicit latent variable model. We model the scene as an interaction graph and employ powerful graph neural networks to learn a distributed latent representation of the scene. Coupled with a deterministic decoder, we obtain trajectory samples that are consistent across traffic participants, achieving state-of-the-art results in motion forecasting and interaction understanding. Last but not least, we demonstrate that our motion forecasts result in safer and more comfortable motion planning.